告别“对齐税”!Meta新研究:RL将LLM变身知识导航员,分层知识检索飙升24%

长期以来,AI社区一直流传着一个“魔咒”:用强化学习(Reinforcement Learning, RL)对大模型进行对齐,虽然能提升其推理和遵循指令的能力,但往往会损害模型在预训练阶段学到的海量知识,这被称作“对齐税”(Alignment Tax)。
论文标题:Reinforcement Learning Improves Traversal of Hierarchical Knowledge in LLMs
ArXiv URL:http://arxiv.org/abs/2511.05933v1
然而,来自苏黎世联邦理工学院、Meta和西蒙弗雷泽大学的最新研究,对这一传统观念发起了颠覆性质疑。
研究发现,在处理需要遍历分层结构(Hierarchical Structures)的知识时,经过RL增强的模型,其知识回忆能力不仅没有下降,反而完胜了它的基础版和监督微调版!
在医疗编码查询这类任务上,性能差距竟高达惊人的24个百分点。这究竟是怎么回事?难道强化学习 secretly 给模型“补课”了吗?

图1:左侧展示了普通模型(DeepSeek-V3)靠“猜”而答错,而RL增强模型(DeepSeek-R1)通过分层导航答对。右侧显示,通过优化提示词,可以缩小两者差距。
知识已在,只缺“导航术”
研究团队首先提出了一个大胆的假设:RL带来的性能提升,并非源于模型学到了新知识,而是因为它掌握了一项新技能——在模型内部参数中高效导航和搜索已有知识体系的程序化技巧。
就像一个图书馆,书(知识)一直都在,但RL给了图书管理员(模型)一套更先进的检索系统。
为了验证这一点,研究者们进行了一个绝妙的实验。他们为未经RL训练的监督微调(Supervised Fine-Tuned, SFT)模型设计了一种结构化提示词(structured prompting)。
这个提示词就像一份“寻宝地图”,明确引导模型一步步地进行分层检索。
结果令人震惊!在DeepSeek模型家族中,通过这种方式,原本SFT模型与RL模型之间24个百分点的巨大性能鸿沟,瞬间被缩小到了7个百分点。
这有力地证明了:知识其实一直都在SFT模型中,只是它不知道如何有效“导航”去找到答案。RL所做的,正是教会了模型这种“导航术”。
不只看结果,更要看过程
仅仅答对还不够,关键是“如何”答对的。RL模型真的掌握了更优的解题路径吗?
为此,研究团队引入了一个根据复杂度分层的专利分类数据集,并设计了一个“路径匹配得分”指标,专门评估模型回答问题的“思考路径”是否正确。
实验结果再次印证了假设。随着任务复杂度(检索深度)的增加,RL模型在“路径匹配得分”上的优势愈发明显。
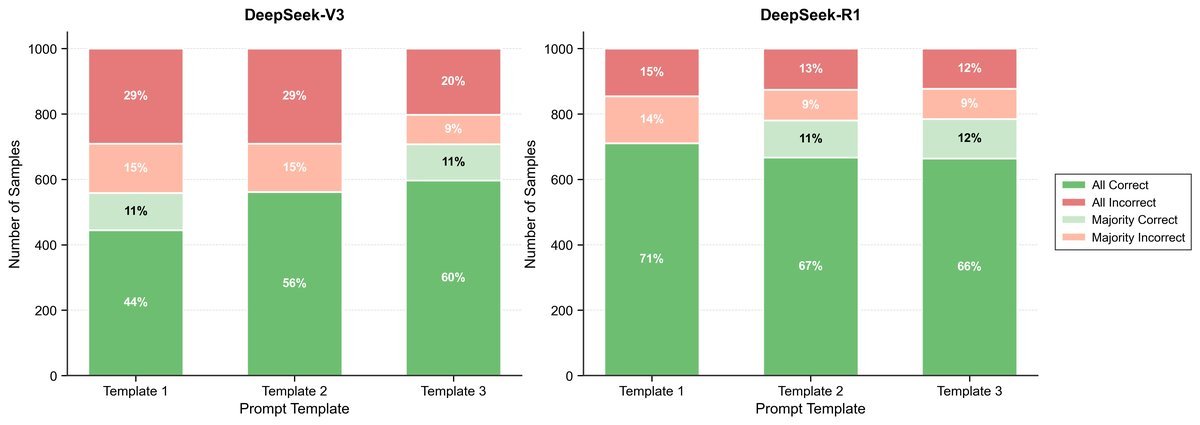
表5:在需要5次以上分层回忆的复杂任务中,DeepSeek-R1(RL模型)的路径匹配得分(Path Matching Score)领先V3(SFT模型)的差距从简单任务的5pp扩大到9pp。
如上表所示,在深度超过5层的复杂检索任务中,RL模型(R1)与SFT模型(V3)的路径得分差距,从简单任务的5个百分点扩大到了9个百分点。
这表明,RL模型不仅能给出正确答案,更重要的是,它真正理解并掌握了在复杂知识层级中穿行的正确“程序”。
深入大脑:RL如何重塑模型思维
最硬核的证据来自对模型内部激活状态的分析。研究者们想知道,RL到底改变了模型大脑的哪个部分?
他们对比了SFT模型和RL模型在处理两类输入时内部表征的差异:
-
陈述句(事实):例如,“代码57.95指代的是泌尿系统感染”。
-
疑问句(查询):例如,“代码57.95是什么?”
分析发现了一个惊人的模式:
-
对于事实陈述,SFT和RL模型在各网络层中的表征具有极高的余弦相似度($0.85$ - $0.92$)。这意味着,它们对知识本身的“存储”方式几乎没有区别。
-
但对于问题查询,两者表征的相似度在模型中间层急剧下降(低至$0.65$ - $0.73$)。
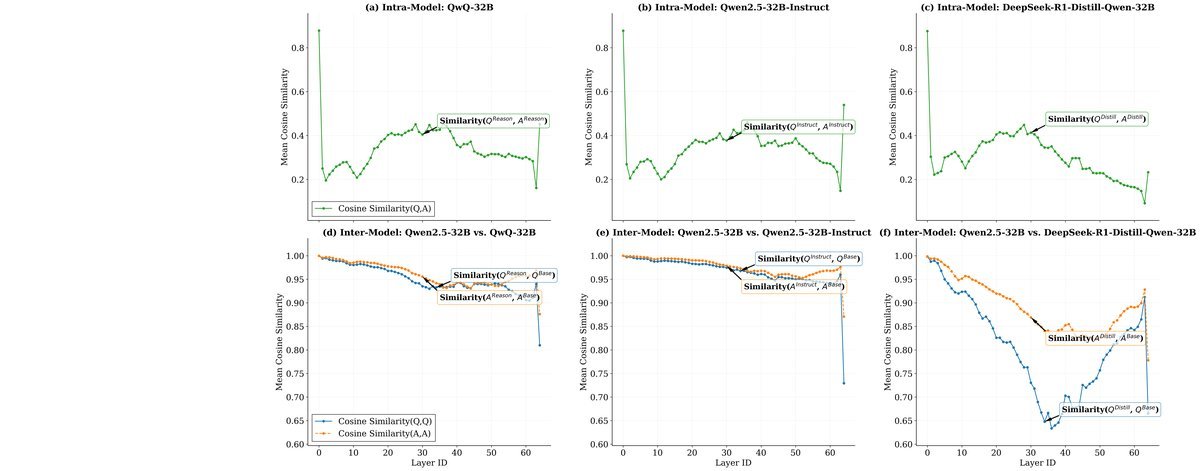
图3:模型内部激活分析。无论哪个模型,(d)问句表征在SFT和RL版本间的相似度,都显著低于(a)答案(事实)表征的相似度。
这种“冰火两重天”的现象揭示了真相:强化学习主要改变了模型处理和理解问题的方式,即知识的“导航”和“检索”机制,而几乎没有触动知识本身的“存储”形态。这为“RL提升导航技能”的假说提供了强有力的神经层面证据。
结论与启示
这项研究有力地反驳了“对齐税”在结构化知识领域的普遍性,并为我们揭示了强化学习在LLM能力提升中的一个新维度:
它不仅仅是“教导员”,更是“导航员”。它不创造新知识,而是解锁、组织并高效利用模型在预训练中已经内化的庞大知识网络。
这一发现为未来的AI训练范式提供了重要启示:我们或许可以将知识获取(预训练)与知识组织和检索(RL后期训练)更明确地分离开来,从而开发出更高效、更强大的AI系统。
未来,我们能否设计出专门优化“导航能力”的RL算法?这种机制是否也适用于数学推理、代码调试等其他结构化任务?这些问题,将为AI的下一步发展指明新的方向。