记忆即算力?阿里ReMe让8B模型超越14B,揭秘动态记忆进化论

在这个“大力出奇迹”的时代,我们习惯了认为模型参数越大,能力越强。但阿里巴巴和上海交通大学的一项最新研究给出了一个反直觉的结论:一个拥有“聪明大脑”的小模型,完全可以战胜一个“健忘”的大模型。
ArXiv URL:http://arxiv.org/abs/2512.10696v1
这项名为 ReMe(Remember Me, Refine Me)的研究提出了一种全新的动态程序记忆框架。最令人震惊的实验结果是:搭载了 ReMe 的 Qwen3-8B 模型,在复杂任务上的表现竟然超越了没有记忆加持的 Qwen3-14B。
这不仅打破了参数量的迷信,更揭示了一条通过“自我进化记忆”实现低成本、终身学习的新路径。今天,我们就来深度拆解 ReMe 背后的技术奥秘。
告别“死记硬背”:传统Agent记忆的困境
目前的 LLM Agent(智能体)虽然能通过 RAG(检索增强生成)或长上下文来利用历史信息,但它们大多陷入了一种 “被动积累”(Passive Accumulation)的误区。
现有的记忆系统通常只是简单地将所有的交互轨迹(Trajectory)像流水账一样扔进数据库。这种“只存不理”的方式带来了三个致命问题:
-
噪声大:原始的交互记录包含大量无关紧要的细节,掩盖了核心逻辑。
-
难复用:过去成功的经验往往是针对特定场景的,直接照搬到新任务中容易“刻舟求剑”。
-
只增不减:随着时间推移,记忆库会变得臃肿不堪,充斥着过时或错误的经验,导致检索效率和准确率双双下降。
Agent 需要的不是一个静态的硬盘,而是一个能像人类一样提炼、反思、遗忘的动态认知系统。这正是 ReMe 的核心使命。
ReMe 架构:让记忆“活”起来的三部曲
ReMe 的全称是 “Remember Me, Refine Me”,它的设计灵感源于人类的学习过程。整个框架由三个相互交织的机制组成,完美闭环了记忆的生命周期。
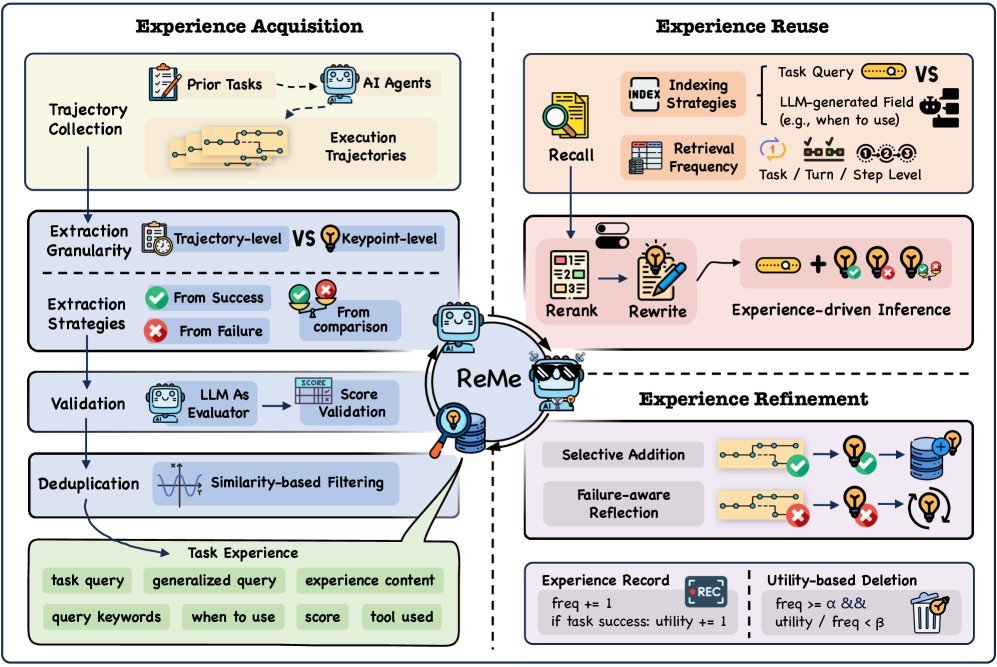
1. 多面蒸馏(Multi-faceted Distillation):从流水账到真知灼见
ReMe 拒绝存储原始的对话日志。相反,它引入了一个 总结器(Summarizer),对 Agent 的每一次尝试进行深度复盘。
这个过程不仅仅是概括发生了什么,而是提取三个维度的细粒度知识:
-
成功模式识别:做对了什么?提取通用的成功步骤。
-
失败触发分析:哪里做错了?识别导致报错或死循环的关键诱因。
-
比较性洞察:如果失败了,修正后的方案比原方案好在哪里?
通过这种方式,ReMe 将庞杂的轨迹转化为结构化的 经验(Experience),每个经验 $E$ 都包含适用场景 $\omega$、核心内容 $e$、关键词 $\kappa$、置信度 $c$ 以及使用的工具 $\tau$。
2. 上下文自适应复用(Context-Adaptive Reuse):拒绝生搬硬套
拥有了高质量的经验库,如何在新任务中用好它?ReMe 并没有简单地进行文本相似度匹配。
它采用了一种 场景感知索引(Scenario-aware Indexing)策略。在检索时,系统会根据当前任务的上下文,去匹配经验中的“适用场景”描述,而不是仅仅匹配关键词。
检索出 Top-K 个相关经验后,ReMe 还会进行 重排序(Reranking)和 自适应重写,确保这些历史智慧能无缝融入当前的新问题中,真正起到“举一反三”的效果。
3. 基于效用的优化(Utility-Based Refinement):优胜劣汰
这是 ReMe 最具创新性的部分。人类会遗忘不重要的信息,Agent 也应该如此。ReMe 维护了一个动态的经验池,并引入了“优胜劣汰”机制。
-
自主添加:只有经过验证的、高质量的新经验才会被加入库中。
-
效用修剪:系统会持续跟踪每条记忆在实际任务中的“贡献度”。
ReMe 定义了一个移除函数 $\phi_{remove}(E)$:
\[\phi_{remove}(E)=\begin{cases}\mathds{1}\left[\frac{u(E)}{f(E)}\leq\beta\right],&\text{if }f(E)\geq\alpha,\\ 0\;,&\text{otherwise}.\end{cases}\]简单来说,如果一条记忆被检索了很多次($f(E)$ 高),但实际带来的帮助很小($u(E)$ 低),它就会被判定为“占着茅坑不拉屎”的低效记忆,并被无情删除。这保证了记忆库始终保持精简和高能。
实验结果:小马拉大车,记忆即算力
研究团队在 BFCL-V3(伯克利函数调用榜单)和 AppWorld(复杂应用交互环境)两个高难度基准上进行了广泛测试。
结果令人振奋:
-
SOTA 表现:ReMe 在各项指标上均刷新了 Agent 记忆系统的最佳成绩。
-
记忆缩放效应(Memory-Scaling Effect):这是最关键的发现。如下表所示,Qwen3-8B + ReMe 的组合,在 Avg@4 和 Pass@4 指标上全面超越了参数量大得多的 Qwen3-14B(无记忆版)。
| Model | Method | BFCL-V3 (Avg@4) | AppWorld (Avg@4) |
|---|---|---|---|
| Qwen3-8B | No Memory | 72.00 | 44.00 |
| Qwen3-8B | ReMe (Dynamic) | 82.33 | 49.83 |
| Qwen3-14B | No Memory | 75.33 | 47.33 |
这意味着,高质量的动态记忆可以作为一种计算资源的替代品。我们不需要无限堆叠显卡去训练更大的模型,通过优化记忆机制,小模型也能展现出惊人的推理能力。
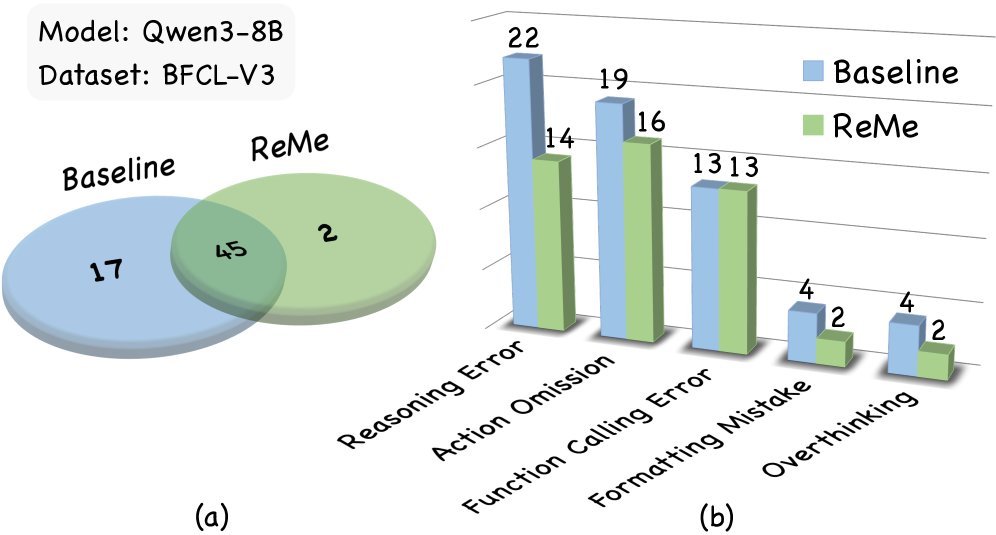
错误分析(上图)进一步证实,引入 ReMe 后,Agent 的推理错误(Reasoning Error)大幅减少。记忆不仅提供了知识,更提供了逻辑路径,帮助 Agent 避开了曾经踩过的坑。
总结与展望
ReMe 的出现标志着 Agent 记忆系统从“被动存储”向“主动进化”的转变。它证明了:一个会反思、懂取舍的 8B 模型,比一个只会蛮干的 14B 模型更强大。
对于开发者而言,ReMe 提供了一个极具价值的启示:在追求更强的 Agent 能力时,与其死磕模型参数,不如花精力构建一套高效的“认知操作系统”。
目前,研究团队已经开源了代码和 \(reme.library\) 数据集,这为社区进一步探索 Agent 的终身学习能力提供了宝贵的资源。
论文链接: Remember Me, Refine Me: A Dynamic Procedural Memory Framework