Remote Labor Index: Measuring AI Automation of Remote Work
-
ArXiv URL: http://arxiv.org/abs/2510.26787v1
-
作者: Long Phan; Denis Peskoff; Alexandr Wang; Jaehyuk Lim; Vivswan Shah; Sumana Basu; Felix Binder; Yuntao Ma; Shivam Singhal; Jason Hausenloy; 等30人
-
发布机构: Center for AI Safety; Scale AI
TL;DR
本文提出了一种名为远程劳动指数(Remote Labor Index, RLI)的新基准,通过评估AI智能体在真实自由职业平台上的端到端项目完成能力,来衡量AI在具有经济价值的实际任务上的自动化水平,从而为追踪AI的经济影响提供了实证基础。
关键定义
本文提出或沿用了以下对理解论文至关重要的核心概念:
- 远程劳动指数 (Remote Labor Index, RLI):一个由真实的、端到端的远程自由职业项目构成的新型基准。这些项目直接来源于在线自由职业平台,旨在评估AI智能体在实际、有经济价值的工作中的表现,从而衡量其自动化能力。
- 自动化率 (Automation Rate):一个核心评估指标,指AI智能体交付的成果被人类评估员判定为“至少与人类黄金标准交付物一样好”(即,一个理性的客户会接受这项工作)的项目所占的百分比。
- Elo评分 (Elo Score):一个用于衡量不同AI智能体之间相对表现的评分系统。它通过对两个AI智能体的交付物进行成对比较(判断哪个更接近成功完成项目或整体质量更高)来计算得出,从而能够捕捉到更细微的能力进步。
- 自动通缩 (Autoflation):一个经济影响指标,衡量当每个项目都可以选择成本最低的完成方式(人类或AI)时,完成整个RLI项目组合的总成本降低的百分比。其计算公式为:\(1-\frac{\sum\min\!\big(\texttt{cost}(H),\,\min\_{j}\texttt{cost}(AI\_{j})\big)}{\sum\texttt{cost}(H)}\)
相关工作
目前,评估AI智能体的基准主要集中在特定技能领域,如软件工程、基本计算机操作或网页浏览。另一些基准则衡量AI在学术知识或跨多个职业的简单通用任务(如写作、网络搜索)上的表现。
然而,这些现有基准存在明显瓶颈:它们要么依赖于简化的环境,要么只覆盖了远程工作经济中一小部分任务类型,无法全面反映真实世界中端到端工作的多样性和复杂性。因此,AI在这些基准上的高分表现,并不能直接转化为对实际人类劳动自动化能力的准确度量。
本文旨在解决这一问题,即缺乏一个标准化的、基于真实经济活动的实证方法来衡量和追踪AI自动化远程工作的能力。通过引入RLI,本文试图为探讨AI的经济影响建立一个坚实的经验基础。
本文方法
本文的核心贡献是提出了远程劳动指数(RLI),一个用于衡量AI自动化能力的全新基准。RLI通过模拟真实的远程工作市场,为评估AI智能体提供了更贴近现实的挑战。
数据集描述
RLI最终包含240个项目,其设计旨在全面反映远程工作的真实面貌。
项目构成
每个RLI项目都包含三个核心部分:
- 工作简报 (Brief):描述工作要求的文本文档。
- 输入文件 (Input Files):完成项目所需的各种文件和数据。
- 黄金标准交付物 (Gold-standard Deliverable):由人类专业人士完成的、符合要求的最终成果。
这确保了每个项目都有充足的信息和明确的成功标准。
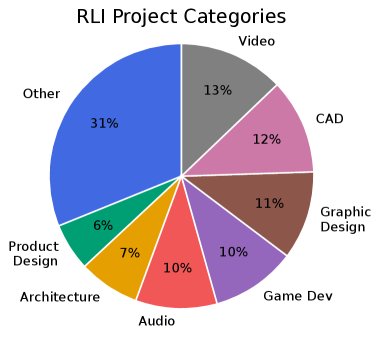
工作类型覆盖范围
RLI在两个关键维度上具有高度多样性:
- 工作类别:遵循Upwork的分类体系,最终数据集覆盖了23个不同的工作类别,远超传统基准关注的软件、研究和写作领域,囊括了设计、市场营销、行政、数据分析、音视频制作等。
- 文件格式:项目的输入和输出涉及大量不同的文件类型,比以往任何基准都更为广泛。
难度与经济价值
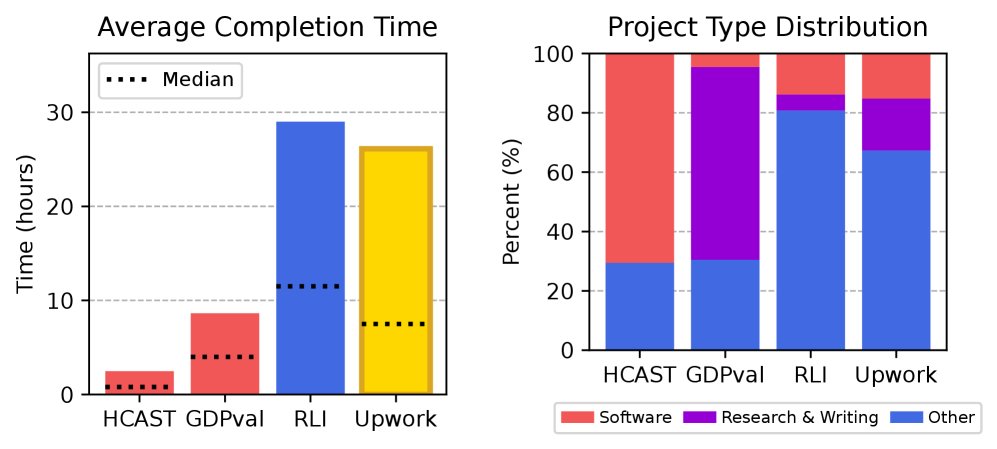
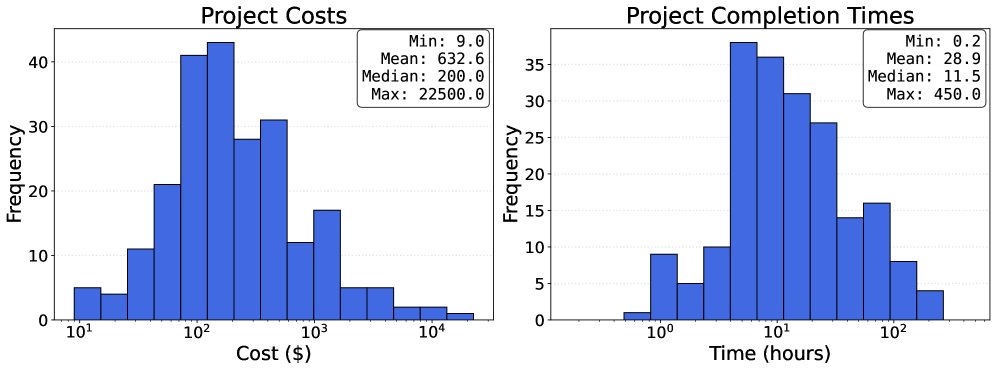
RLI中的项目具有显著的复杂性和经济价值。项目的平均完成时间为28.9小时,中位数为11.5小时,这与Upwork上随机抽样的工作耗时相当。项目的平均成本为$632.6美元,中位数为$200美元。这些特征使得RLI比以往的基准更能代表当代远程自由职业工作的真实复杂性。
数据集收集
RLI的数据集收集过程严谨,确保了其高质量和代表性。
sourcing策略
采用自下而上的方法,直接与自由职业平台(主要是Upwork)上的专业人士合作,获取他们过往真实完成的项目样本。收集范围覆盖了Upwork分类中经过筛选的43个适合标准评估的类别,并通过定向征集和在线搜寻高质量工作样本来补充长尾工作类型。
招募与专业性
共招募了358名在Upwork上有认证账户和丰富经验的自由职业者。这些专业人士平均拥有2,341个工作小时和$23,364美元的总收入,确保了项目来源的专业性。
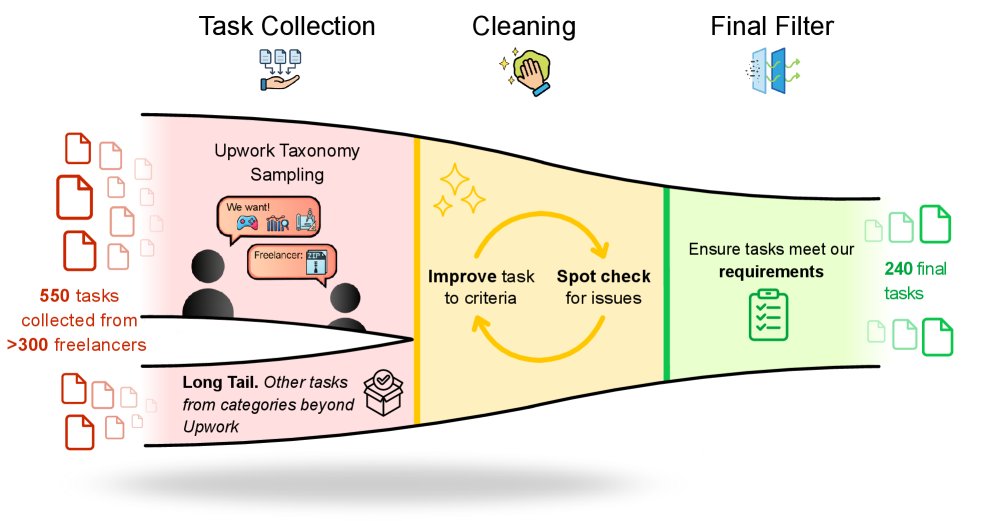
审查与清理
收集到的550个初始项目经过多轮严格的审查和清理。排除了那些需要人类互动、依赖专有软件或难以在评估平台上复现的项目,最终筛选出240个符合标准的、自成一体的项目实例。
评估方法
由于RLI项目的复杂性和交付物的多样性,本文依赖于严格的人工评估。
评估平台
为了标准化评估流程,本文开发了一个专门的、开源的Web评估平台。该平台能够原生渲染数十种不同的文件格式,让评估员可以在统一的环境中高效地查看和比较AI与人类的交付物。
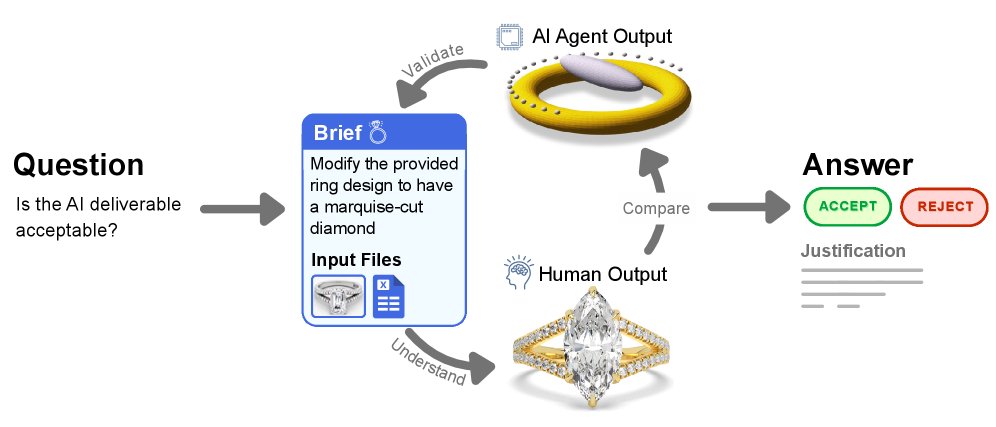
自动化率评估
评估的核心是判断AI的交付物是否“至少和人类黄金标准一样好”。评估员采用整体评估法,在理解项目背景后,将AI交付物与人类交付物进行比较,并根据以下3点量表进行打分:
- AI交付物未满足要求或质量显著较低,不会被理性客户接受。
- AI交付物满足要求且质量相当,会被理性客户接受。
- AI交付物不仅满足要求,且在整体质量上超越了人类交付物。
最终的自动化率是获得评分2或3的项目百分比。该方法的评估员间一致性高达94.4%。
Elo评估
Elo评估用于衡量不同AI智能体之间的相对性能。评估员同时看到两个AI的交付物(以人类交付物为参考),并从“完成度”和“整体质量”两个维度进行比较。这使得即使所有智能体的绝对表现都很差,也能衡量出它们之间的细微差距和进步趋势。
实验结论
本文对六个前沿AI智能体在RLI基准上进行了评估,揭示了当前AI自动化能力的现状。
实验设置
评估了包括ChatGPT agent、GPT-5、Claude Sonnet 4.5在内的六个顶尖AI智能体。根据模型是否支持计算机使用,为它们配备了计算机使用代理(CUA)或命令行界面(CLI)环境,并进行了提示词优化以发挥其最佳性能。
定量结果
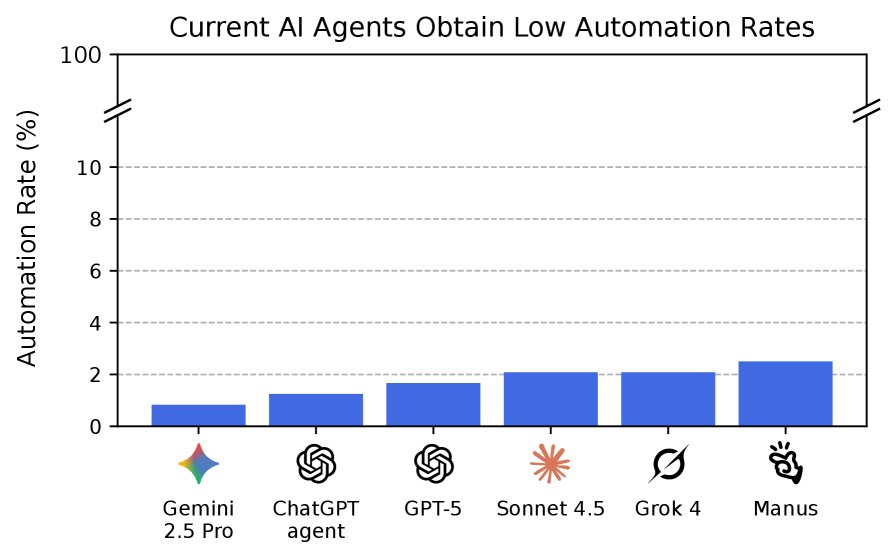
绝对表现接近“地板”水平
实验的核心发现是,当前最先进的AI智能体在完成RLI中的真实经济价值项目方面能力极低。自动化率是衡量绝对成功的关键指标,表现最好的智能体(Manus)也仅达到了2.5%。这意味着在97.5%的项目中,AI的交付物未能达到专业工作的验收标准。相应的,经济影响指标(如“赚取的美元”和“自动通缩”)也同样处于极低水平。
| 模型 | 自动化率 |
|---|---|
| Manus | 2.5% |
| Grok 4 | 2.1% |
| Sonnet 4.5 | 2.1% |
| GPT-5 | 1.7% |
| ChatGPT agent | 1.3% |
| Gemini 2.5 Pro | 0.8% |
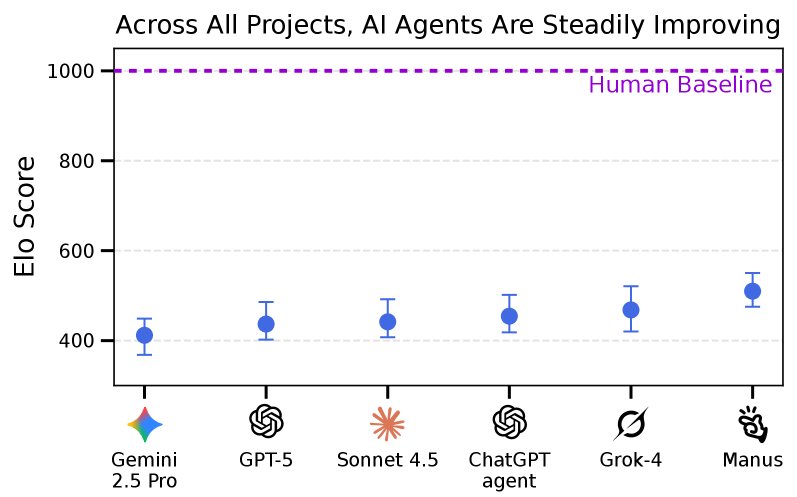
Elo评分揭示了稳步提升
尽管绝对表现不佳,但通过Elo评分进行相对比较后发现,AI模型仍在稳步取得进展。Elo排名显示,更新的模型通常比旧模型表现更好,证明RLI基准能够灵敏地捕捉到AI能力的持续进步。
定性发现
通过对失败案例的定性分析,本文总结了当前AI智能体常见的失败模式。
常见失败模式
评估员的反馈显示,AI交付物被拒的原因主要集中在以下几个方面:
- 文件损坏或格式错误 (Corrupted files):AI生成了无法打开的、空的或格式不正确的文件。
- 不完整 (Incomplete):交付物缺少关键组件,例如视频时长严重不足、缺少必要的源文件等。
- 质量差 (Poor quality):即使交付物在形式上是完整的,其内容质量也远未达到专业标准。
- 不一致 (Inconsistencies):当使用AI生成工具时,交付物的不同部分之间存在明显的风格或内容矛盾。
| 失败模式 | 出现频率 (%) |
|---|---|
| 文件损坏 | $17.6$ |
| 不完整 | $35.7$ |
| 质量差 | $45.6$ |
| 不一致 | $14.8$ |
总结:实验结论非常明确,尽管AI在许多研究型基准上取得了惊人进展,但它们距离自主完成多样化、复杂的远程工作还有很长的路要走。RLI作为一个全新的实证工具,为客观衡量和追踪这一进程提供了可靠的基准。