Rethinking Retrieval-Augmented Generation for Medicine: A Large-Scale, Systematic Expert Evaluation and Practical Insights
- ArXiv URL: http://arxiv.org/abs/2511.06738v1
TL;DR
本文通过大规模专家评估,系统性地揭示了标准检索增强生成 (Retrieval-Augmented Generation, RAG) 在医学领域非但不能稳定提升性能,反而常因证据检索和选择不佳而降低响应的真实性和完整性,并证明通过证据过滤和查询重构等简单策略可显著改善此问题。
相关工作
大型语言模型 (Large Language Models, LLMs) 在医学领域的应用日益广泛,但始终面临两大核心挑战:一是如何跟上快速更新的医学知识,二是如何提供可验证的、基于证据的推理。RAG 被视为主流解决方案,旨在通过在推理时引入外部知识库来解决这些问题。
然而,尽管RAG被广泛采用,但其在医学实践中的真实效果尚不明确。现有研究大多将RAG视为一个“黑箱”,仅评估最终任务的性能,缺乏对检索质量、证据使用等中间环节的深入分析。部分研究甚至发现RAG可能会降低下游任务的准确性。因此,领域内迫切需要一个系统性的调查来厘清RAG在医学应用中的作用机制、关键瓶颈以及真实效果。
本文旨在解决这一问题,通过大规模、细粒度的专家评估,系统性地剖析RAG在医学问答场景中的三个关键阶段:证据检索、证据选择和响应生成,以准确定位性能瓶颈,并验证改进策略的有效性。
本文方法
本文的核心方法论是一个创新的、分阶段的评估框架,以及基于评估发现提出的两种实用改进策略。
创新的评估框架
作者设计了一个三阶段评估框架,以系统性地解构并评测RAG流程中的每一个环节。
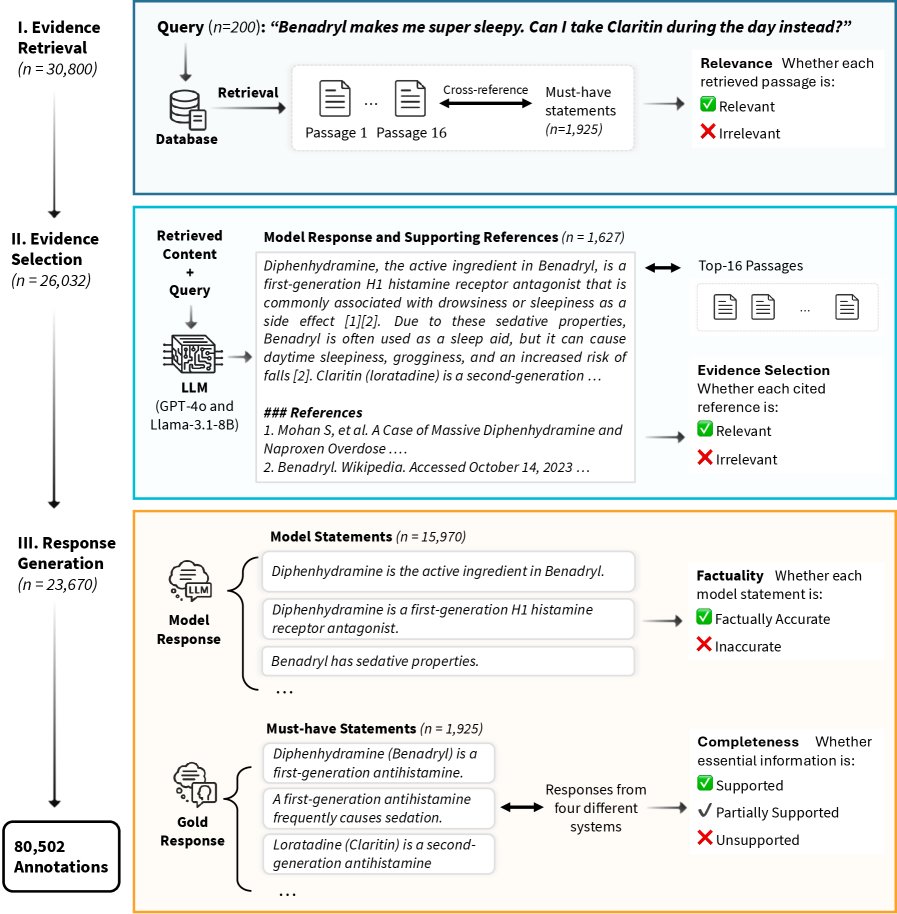 图1:研究设计与评估框架。该框架将RAG流程分解为证据检索、证据选择和响应生成三个组件,以实现对每个阶段的系统性评估。
图1:研究设计与评估框架。该框架将RAG流程分解为证据检索、证据选择和响应生成三个组件,以实现对每个阶段的系统性评估。
1. 模型与数据设置
- 模型: 选用业界领先的闭源模型 \(GPT-4o\) และ开源模型 \(Llama-3.1-8B\),并分别测试其使用RAG和不使用RAG的四种配置。
- 检索器: 采用医学领域常用的专业检索器 \(MedCPT\)。
- 知识库: 涵盖了PubMed、维基百科、临床指南、StatPearls和医学教科书等多种权威医学资源。
- 数据集: 包含200个医学问题,其中100个来自真实患者的自由文本查询 (K-QA 数据集),100个是模拟美国执业医师资格考试 (United States Medical Licensing Examination, USMLE) 的复杂案例题 (MedBullets 数据集)。这些数据集均带有专家标注的黄金标准答案,并被分解为“必须包含 (must-have)”和“锦上添花 (nice-to-have)”的知识点陈述。
2. 三阶段评估流程 18名医学专家对800个模型输出进行了总计80,502项标注,评估流程如下:
- 第一阶段:证据检索 (Evidence Retrieval)
- 目标: 评估检索到的信息是否与问题相关且覆盖了关键知识点。
- 过程: 对每个问题,专家们评估由检索器返回的前16个文本段落。如果一个段落能支持答案中的至少一个“必须包含”的知识点,则被标记为相关。
- 规模: 30,800项段落-知识点对的评估。
- 第二阶段:证据选择 (Evidence Selection)
- 目标: 评估LLM是否有效地从检索到的段落中选择并引用了相关信息。
- 过程: 专家们核对模型最终响应中引用的参考文献,判断这些引用是来源于检索到的16个段落(检索驱动),还是模型内部知识生成的(自我生成)。对于检索驱动的引用,进一步判断其来源段落是相关还是不相关。
- 规模: 26,032项段落-参考文献对的对齐标注。
- 第三阶段:响应生成 (Response Generation)
- 目标: 评估最终生成的响应内容的真实性 (factuality) 和完整性 (completeness)。
- 过程: 专家们逐条判断模型生成的所有陈述是否正确(真实性评估),并判断模型响应是否覆盖了所有“必须包含”的知识点(完整性评估)。
- 规模: 15,970条模型生成陈述的真实性标注,以及7,700项响应-知识点对的完整性标注。
改进策略
基于评估中发现的问题,本文提出了两种简单而有效的策略以缓解RAG的性能下降问题:
- 证据过滤 (Evidence Filtering): 鉴于检索返回了大量不相关内容,且模型倾向于错误地使用它们,该策略在将检索到的段落送入LLM之前,先将其中的不相关段落过滤掉。
- 查询重构 (Query Reformulation): 针对检索精度和覆盖率低的问题,该策略通过重写原始用户查询,将其优化为更适合检索系统的形式,从而引导检索器找到更相关的证据。
实验结论
实验结果系统地揭示了标准RAG在医学应用中的严重局限性,并验证了所提改进策略的有效性。
证据检索:精度低、覆盖不足
检索阶段表现出显著的性能瓶颈,大部分检索到的内容都无关紧要。 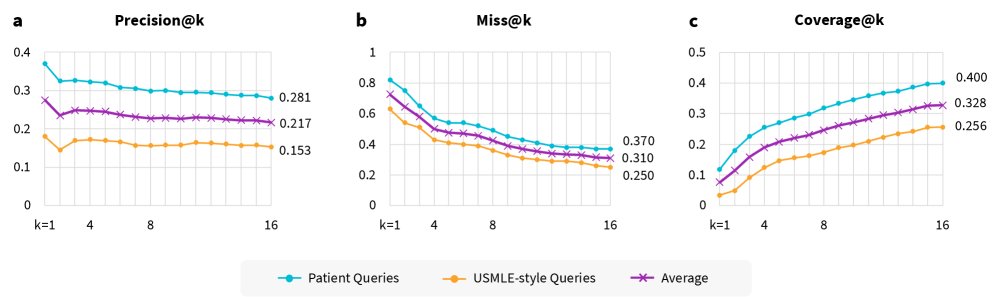 图2:证据检索性能分析。a) Precision@k,b) Miss@k,c) Coverage@k。
图2:证据检索性能分析。a) Precision@k,b) Miss@k,c) Coverage@k。
- 低精度: 在检索到的前16个段落中,平均只有21.7%是相关的 (Precision@16),对于更复杂的USMLE风格问题,该比例更是降至15.3%。
- 高失误率: 31% 的查询在前16个检索结果中未能找到任何相关段落 (Miss@16)。
- 低覆盖率: 前16个检索段落总共只覆盖了32.8% 的“必须包含”的关键知识点 (Coverage@16)。这意味着即使模型能完美利用所有检索信息,仍有近70%的关键信息缺失。
证据选择:模型难以有效利用相关信息
即使检索到了相关段落,LLM在选择和使用这些信息时也表现不佳。
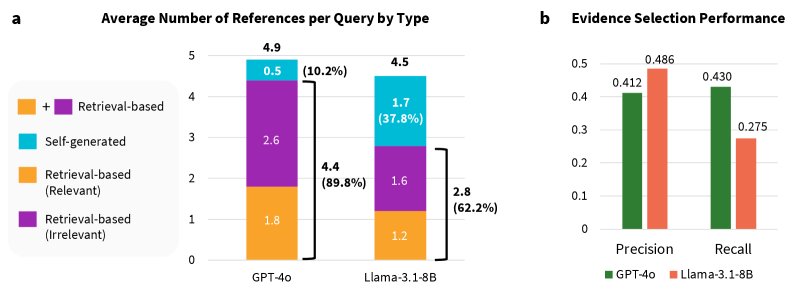 图3:引用类型和证据选择性能分析。a) 按证据来源分类的每条查询的平均引用数。b) 识别检索段落中相关证据的精确率和召回率。
图3:引用类型和证据选择性能分析。a) 按证据来源分类的每条查询的平均引用数。b) 识别检索段落中相关证据的精确率和召回率。
- 选择能力差: 模型在从检索结果中挑选相关信息方面的表现很差。GPT-4o的精确率仅为41%,召回率为49%;Llama-3.1的精确率为43%,召回率更是低至28%。这意味着模型既引用了大量不相关信息,也遗漏了大量已检索到的相关信息。
- 偏好引用不相关内容: 模型响应中引用不相关段落的频率几乎是引用相关段落频率的两倍,这直接导致了后续响应生成中的错误。
响应生成:RAG导致性能下降
与普遍认知相反,使用标准RAG后,模型的最终输出在真实性和完整性方面均出现下降。
- 真实性下降: 与不使用RAG的版本相比,GPT-4o的响应级真实性下降了高达6%。当模型引用不相关段落时,Llama-3.1的真实性下降超过8%。
- 完整性下降: Llama-3.1的陈述级完整性下降了超过5%。当相关信息未能被检索到时,完整性下降更为明显。
改进策略效果显著
与标准RAG的负面效果形成鲜明对比,结合了证据过滤和查询重构的改进策略在多个医学问答基准测试中取得了显著的性能提升。
- 在 MedMCQA 数据集上,Llama-3.1 准确率提升了 12%,GPT-4o 提升了 3.4%。
- 在 MedXpertQA 数据集上,Llama-3.1 准确率提升了 8.2%,GPT-4o 提升了 6.6%。
总结
本文的结论颠覆了“RAG默认能提升模型性能”的普遍看法。研究表明,在医学这一高风险领域,盲目应用标准RAG不仅无效,甚至可能有害。其失败的根源在于检索质量差和模型证据选择能力弱。未来的研究方向不应将RAG视为即插即用的默认方案,而应转向更审慎的系统设计和分阶段的细粒度评估,例如本文提出的证据过滤和查询重构等针对性干预措施,才是构建可靠医疗LLM应用的关键。