Rethinking Supervised Fine-Tuning: Emphasizing Key Answer Tokens for Improved LLM Accuracy
SFTKey:别让CoT喧宾夺主!两阶段微调让大模型准确率提升超5%

在大模型微调的江湖里,思维链(Chain-of-Thought, CoT)几乎成了提升推理能力的“标配”。然而,你是否想过,过长的推理过程可能会产生副作用?当模型在训练中花费大量精力去学习冗长的推理步骤时,它往往会忽视那个虽然短小但至关重要的部分——最终答案。
ArXiv URL:http://arxiv.org/abs/2512.21017v1
这种“重过程、轻结果”的现象,正是当前监督微调(SFT)面临的一大隐痛。为了解决这个问题,来自北京智源人工智能研究院和北京交通大学的研究者们提出了一种名为 SFTKey 的新策略。这项研究不仅揭示了传统 SFT 的弊端,更通过一个简单而巧妙的“两阶段”训练法,在不牺牲格式正确性的前提下,将模型的平均准确率提升了超过 5%。
传统 SFT 的“注意力陷阱”
在标准的监督微调(Supervised Fine-Tuning, SFT)中,模型的目标是最小化整个序列的预测误差。这意味着,每一个 Token 在损失函数中通常被视为同等重要。
但在处理复杂推理任务时,数据通常由两部分组成:
-
CoT 部分:冗长的中间推理步骤。
-
Key 部分:简短的最终答案。
由于 CoT 序列往往非常长,模型在训练时会分配不成比例的注意力去优化这些推理 Token,从而“淹没”了对最终答案(Key)的学习。这就好比一个学生在考试时,把所有时间都花在写解题步骤上,最后却因为匆忙而写错了最终答案。
为了打破这种不平衡,研究团队提出了 SFTKey 框架,核心思想非常直观:既要学会推理,更要确保答对。
SFTKey:两阶段训练的艺术
SFTKey 并非完全推翻传统的 SFT,而是对其进行了精细化的重构。该方法引入了特殊的标签(Tag),即 \(<Thinking>\) 和 \(<Answer>\),将推理过程和最终答案明确区分开来。
如下图所示,整个训练过程被拆分为两个互补的阶段:
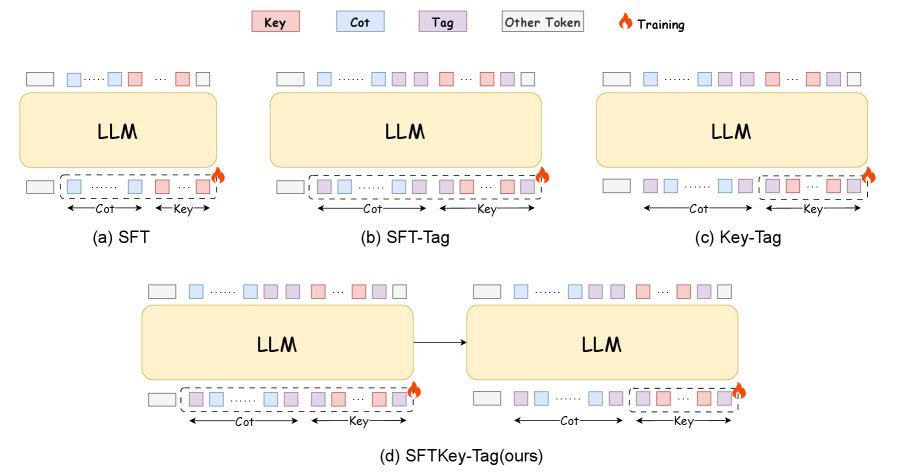
第一阶段:SFT-Tag(打好基础)
在这一阶段,研究者使用带有 \(<Thinking>\) 和 \(<Answer>\) 标签的完整数据进行标准的 SFT 训练。
这一步的目的非常明确:确保模型能够学会正确的输出格式,并具备基本的推理能力。 如果跳过这一步,模型可能连基本的 XML 标签都无法正确生成,更别提逻辑连贯了。
第二阶段:Key-Tag(精准提分)
这是 SFTKey 的灵魂所在。在第一阶段模型参数的基础上,第二阶段仅针对 Key 部分(即最终答案)进行微调。
此时的损失函数不再关心 \(<Thinking>\) 部分的预测,而是专注于 \(<Answer>\) 标签后的内容:
\[\mathcal{L}\_{\text{Answer}}(\mathbf{\theta})=-\sum\_{i=1}^{N}\sum\_{t=T\_{i}+1}^{L\_{i}}\log P\left(y\_{i,t}\mid\mathbf{x}\_{i},\hat{\mathbf{y}}\_{i,<t};\mathbf{\theta}\right)\]通过这种方式,模型被强制要求“全神贯注”于最终结果的准确性,从而修正了之前因 CoT 过长而导致的权重失衡。
实验结果:简单即有效
为了验证这一策略的有效性,研究团队在多个基准测试(如 GSM8K, MATH 等)和不同规模的模型(Qwen, Llama, SmolLM 等)上进行了广泛实验。
结果令人振奋:SFTKey-Tag 策略在保持输出格式正确的同时,显著提升了模型的准确率。
下表展示了不同策略下的综合得分(结合了准确率和格式依从性):
| Model | SFT | SFT-Tag | Key-Tag | SFTKey-Tag (Ours) |
|---|---|---|---|---|
| Qwen2.5-7B | 68.4 | 69.1 | 70.9 | 73.5 (+5.1) |
| Qwen2.5-3B | 56.5 | 56.8 | 58.2 | 60.3 (+3.8) |
| SmolLM-3B | 38.2 | 38.5 | 39.8 | 42.1 (+3.9) |
(注:表格数据为简化展示,完整数据请参考原论文 Table 1)
从数据中我们可以看到几个关键结论:
-
SFTKey-Tag 完胜:相比于标准的 SFT,SFTKey-Tag 在 Qwen2.5-7B 上带来了惊人的 5.1% 的提升。
-
大模型受益更多:参数量越大的模型(如 7B, 8B),从这种策略中获得的收益似乎比小模型(1.5B, 3B)更明显。
-
单一策略的局限:
-
仅使用 SFT-Tag(加标签但不分阶段)提升有限。
-
仅使用 Key-Tag(只训答案)虽然能提高准确率,但严重破坏了输出格式(模型可能会忘记怎么写 \(<Thinking>\) 标签)。
-
为什么必须是“两阶段”?
你可能会问,既然只训 Key 部分就能提高准确率,为什么不直接只做第二阶段?
研究者在消融实验中给出了答案。如下图所示,Key-Tag 策略(只训答案)虽然在准确率上表现强劲(蓝色区域),但在格式依从性上往往不如 SFT-Tag。
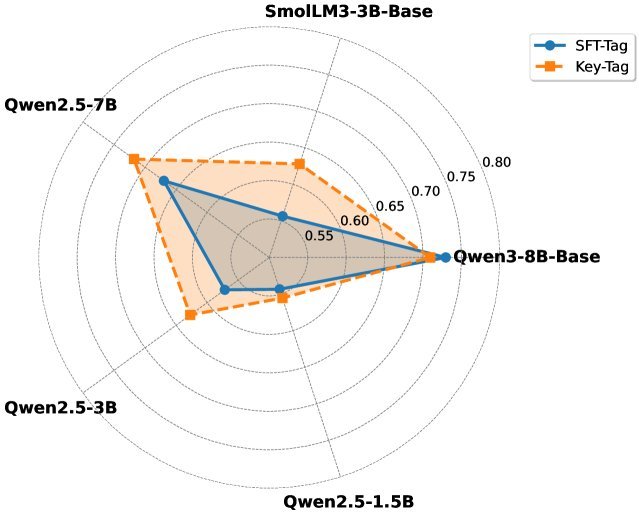
这就好比一个偏科的天才,虽然题都能算对,但卷面一塌糊涂,甚至连答题卡都填不对。SFTKey 的两阶段设计,正是为了在“卷面整洁”(格式正确)和“答案正确”(高准确率)之间找到完美的平衡点。
总结与启示
这篇论文为我们提供了一个非常实用的微调思路:在追求长思维链(CoT)带来的推理能力提升时,不要忘记“答案”才是任务成功的关键。
SFTKey 通过简单有效的两阶段训练,无需引入复杂的强化学习或额外的奖励模型,就显著提升了 LLM 的表现。对于那些正在为 SFT 效果瓶颈而苦恼的开发者来说,这无疑是一个值得尝试的“低成本、高回报”的优化方案。
既然让模型多看一眼答案就能变强,何乐而不为呢?