Reusing Pre-Training Data at Test Time is a Compute Multiplier
-
ArXiv URL: http://arxiv.org/abs/2511.04234v1
-
作者: Alex Fang; Ruoming Pang; Ludwig Schmidt; Tom Gunter
-
发布机构: Apple; Stanford
TL;DR
本文提出,在测试时通过检索增强的方式重用模型的预训练数据,可以显著提升大语言模型的性能,这种方法相当于一种高效的“计算倍增器”,证明了当前预训练方法并未充分利用数据中的信息。
关键定义
本文主要沿用并组合了现有概念,其中对理解本文至关重要的核心概念包括:
- 检索增强生成 (Retrieval Augmented Generation, RAG):一种在生成回答前,先从外部知识库中检索相关信息,并将其作为上下文提供给语言模型的技术。本文的独特之处在于,其外部知识库就是模型自己的预训练数据集。
- 测试时计算 (Test-Time Compute):指在模型推理(测试)阶段投入额外的计算资源以提升性能。本文中,这主要体现在通过多次检索、自洽性(self-consistency)投票等方式来优化最终答案。
- 计算倍增器 (Compute Multiplier):本文提出的一个核心量化指标,用于衡量通过在测试时进行检索所带来的性能提升,相当于需要对基座模型进行多少倍的额外预训练计算才能达到同样的效果。例如,一个5倍的计算倍增器意味着检索带来的提升等同于将预训练计算量增加到原来的5倍。
相关工作
当前,提升大语言模型(LLM)性能的主要途径是扩大预训练的计算量、模型参数和数据规模。然而,这一趋势面临着收益递减的挑战,即在更大规模上,需要投入不成比例的更多计算才能获得相同的性能增益。同时,研究也表明LLM在长尾知识和某些泛化能力(如“反转诅咒”)上存在局限。
虽然研究者们付出了巨大努力来构建和优化预训练数据集,但很少有工作去探究预训练过程从这些数据中提取知识的效率到底有多高。与此同时,检索增强方法通常将知识外置于非参数内存中,以提升知识密集型任务的性能。
本文旨在解决的核心问题是:现有的预训练方法是否充分利用了数据中的知识? 作者假设预训练过程是“有损”的,大量有价值的信息被遗漏。因此,他们探索能否在测试时通过检索重用这些预训练数据,来弥补预训练过程的不足,并量化这种方法带来的价值。
本文方法
本文的核心方法是在测试时对预训练数据集进行检索增强,并结合多种测试时计算技术来进一步释放数据潜力。
核心思想与流程
本文的创新并非提出一种全新的算法,而是提出一种新的范式:让模型在回答问题时,“重读”其预训练材料中的相关部分。这揭示了一个关键洞见:预训练并不能让模型完美地内化所有知识,显式地提供上下文仍然至关重要。
其技术流程如下:
- 索引构建:将用于预训练的多个数据集(如网页抓取、arXiv、维基百科、数学数据等)构建成一个可供检索的索引库。
- 检索:当模型接收到一个问题时,使用一个嵌入模型(如 Qwen3 Embedding)将问题编码,并在索引库中(使用 FAISS FlatIP)检索出 top-k(例如100个)最相关的文档片段。
- 重排 (Rerank):使用一个重排模型(如 Qwen3 Reranker)对初步检索到的文档进行重新排序,以提高最相关文档的排名。
- 生成:将排名靠前的文档作为上下文,与原始问题一起输入到“阅读器模型”(Reader Model,即被测试的LLM)中,生成最终答案。
测试时计算增强
为了最大化从检索到的文档中提取信息的能力,本文还引入了额外的测试时计算策略:
- 自洽性 (Self-Consistency):进行多次推理,每次可以基于不同的检索文档子集(例如通过bagging)或不同的推理路径,最后通过多数投票的方式选择最一致的答案。这可以有效减少单次推理的随机性错误。
- 多样性与方差缩减 (Variance Reduction, VR):采用 Maximal Marginal Relevance (MMR) 等技术来增加每次试验中检索到的文档的多样性,或通过 bagging(随机选择文档子集)来降低整体方差,从而提高集成效果的鲁棒性。
通过这些方法,测试时计算被有效地、数据驱动地用于提升检索工具本身(通过选择更优的上下文)和模型推理过程,而不仅仅是简单地增加推理时长。
实验结论
本文通过一系列实验,有力地证明了在测试时重用预训练数据是一种高效的性能提升手段。
预训练实验
-
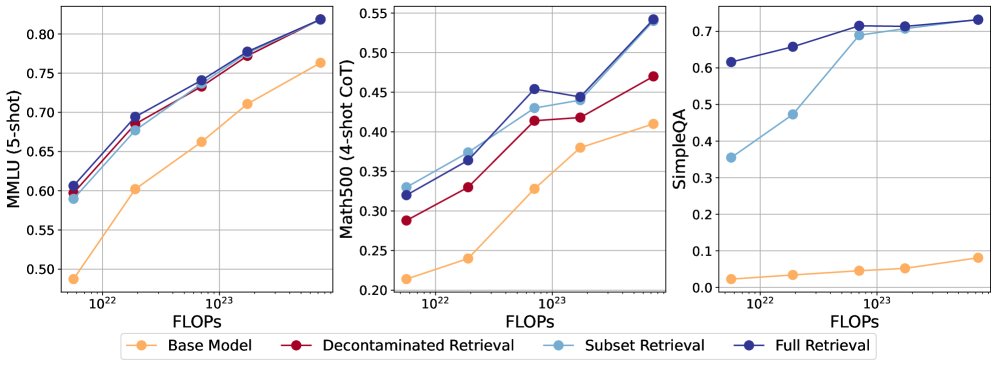
显著性能提升:在 MMLU、Math-500 和 SimpleQA 等多个基准测试上,对预训练数据进行检索增强(RAG)能够显著提升模型准确率,即使在对数据集进行去污染(decontamination)处理后,这种提升依然存在。
-
计算倍增效应:在 MMLU 基准上,与单纯增加预训练计算量相比,检索增强平均带来了 4.86倍 的计算倍增效应。这意味着,通过检索达到的性能提升,若要通过预训练实现,则需要近5倍的计算资源。不过,这种效应随着模型规模的增大而减弱,对于最大的模型,倍增效应降至2.88倍。
| 计算预算 | 基线 MMLU | 检索后 MMLU | 匹配检索性能所需的基线计算量 | 计算倍率 |
|---|---|---|---|---|
| $5.64\times 10^{21}$ | 0.4873 | 0.6063 | $2.98\times 10^{22}$ | 5.28x |
| $1.90\times 10^{22}$ | 0.6021 | 0.6943 | $1.36\times 10^{23}$ | 7.17x |
| $7.04\times 10^{22}$ | 0.6623 | 0.7410 | $3.34\times 10^{23}$ | 4.74x |
| $1.74\times 10^{23}$ | 0.7107 | 0.7775 | $7.35\times 10^{23}$ | 4.23x |
| $7.34\times 10^{23}$ | 0.7633 | 0.8186 | $2.11\times 10^{24}$ | 2.88x |
-
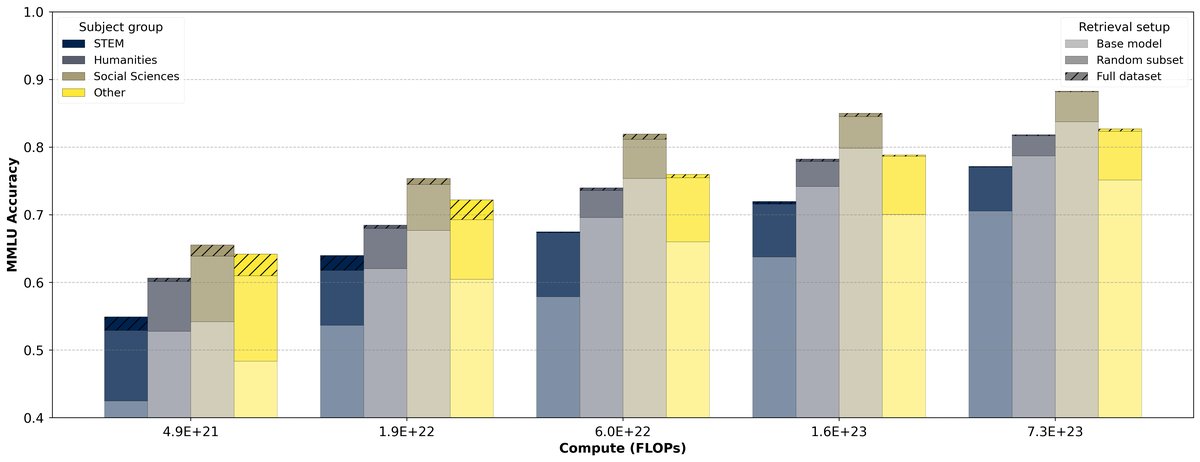
对推理任务同样有效:出乎意料的是,检索不仅对需要事实记忆的任务有帮助,对需要推理的STEM(科学、技术、工程、数学)类问题的提升甚至超过了人文社科类问题,表明检索提供的上下文也起到了辅助推理的作用。
测试时计算实验
- 效果叠加:在使用 Llama 3.1 8B 模型的实验中,检索、重排和自洽性等测试时计算技术的增益是可叠加的。三者结合使用,在 MMLU 上带来了 10.5 个百分点的巨大提升,在 MATH-500 上提升了 15.7 个百分点。
- 更高的计算倍增器:将所有测试时方法(重排、自洽性、VR)结合,相比基线模型,在 MMLU 上实现了高达 11.1倍 的计算倍增器,再次证明了这种策略的计算效率。
| 方法 | MMLU (All) | Math-500 | SimpleQA | GPQA (All) |
|---|---|---|---|---|
| 基线 | 71.6 | 48.7 | 1.5 | 30.6 |
| + 自洽性 | 75.3 | 55.9 | N/A | 31.4 |
| + 检索 | 76.6 | 56.7 | 65.7 | 33.2 |
| + 重排 | 77.7 | 56.8 | 74.0 | 34.8 |
| + 重排 + 自洽性 | 81.0 | 64.3 | N/A | 36.1 |
| + 重排 + 自洽性 + VR | 82.1 | 64.4 | N/A | 36.8 |
其他分析与总结
- 数据质量至关重要:实验表明,好的预训练数据集不一定是好的检索数据集。更重要的是,数据处理的早期阶段(如文本提取和网页爬取)对最终检索性能有巨大影响。例如,使用定制的维基百科数据提取方法,比通用方法在 SimpleQA 上性能提升了近14个百分点。
- 最终结论:目前的预训练方法远未充分利用现有数据集中的信息,留下了巨大的改进空间。在测试时通过检索重用这些数据,是一种行之有效且计算效率极高的性能提升策略,为未来如何更高效地利用数据和计算资源指明了方向。