RevFFN: Memory-Efficient Full-Parameter Fine-Tuning of Mixture-of-Experts LLMs with Reversible Blocks
单卡全量微调MoE大模型?RevFFN让显存占用减半,性能超越LoRA

在当今的大模型(LLM)时代,全量微调(Full Fine-Tuning) 依然是让模型适应下游任务的“黄金标准”。相比于只更新少量参数的 LoRA 等方法,全量微调往往能带来更强悍的性能表现。
ArXiv URL:http://arxiv.org/abs/2512.20920v1
但现实是残酷的:全量微调对显存的需求简直是“无底洞”。尤其是对于现在流行的 混合专家模型(MoE),动辄几十亿甚至上千亿的参数,想要在单张消费级甚至服务器级 GPU 上进行全量微调,几乎是不可能的任务。
我们通常面临的两难选择是:要么忍受多卡分布式训练的高昂硬件成本和通信延迟,要么妥协使用 PEFT(参数高效微调)技术,牺牲一部分模型潜力。
有没有一种方法,既能享受全量微调的性能红利,又能把显存占用打下来,甚至能在单卡上跑起来?
中山大学的研究团队带来了一个令人兴奋的答案:RevFFN。这是一种基于可逆网络(Reversible Networks) 的全新微调范式,它成功地将 MoE 大模型的全量微调显存占用大幅降低,打破了“显存墙”的限制。
显存杀手:中间激活值
在深入 RevFFN 之前,我们需要先明白为什么全量微调这么吃显存。
很多人误以为显存主要被模型权重占用了。其实在训练过程中,真正的“显存杀手”是中间激活值(Intermediate Activations)。为了计算梯度进行反向传播,传统的优化器(如 Adam)需要缓存前向传播过程中每一层的输出。
对于深层网络和长序列数据,这些缓存的激活值大小会随着层数线性增长,最终占据了绝大部分显存。DeepSpeed 等框架虽然可以通过 CPU 卸载(Offloading)来缓解,但这会带来巨大的通信开销,严重拖慢训练速度。
RevFFN 的核心魔法:可逆计算
RevFFN 的核心思想非常巧妙:既然存不下,那就不存了,用的时候再算出来!
它利用了可逆网络(Reversible Networks) 的特性。在一个可逆块中,如果我们知道输出,就可以通过数学公式精确地反推出输入。这意味着,在反向传播时,我们不需要从显存中读取缓存的激活值,而是直接根据当前的输出来实时重构上一层的输入。
这就好比你走迷宫,传统方法是在每个路口撒面包屑(缓存激活值)以便往回走;而可逆网络则是给你一张精确的地图,让你随时都能推算出上一步是在哪里,从而彻底省去了撒面包屑的空间。
1. 巧妙的“双流”设计
RevFFN 并没有直接生硬地改造 Transformer,而是设计了一种特殊的可逆块(Reversible Block)。
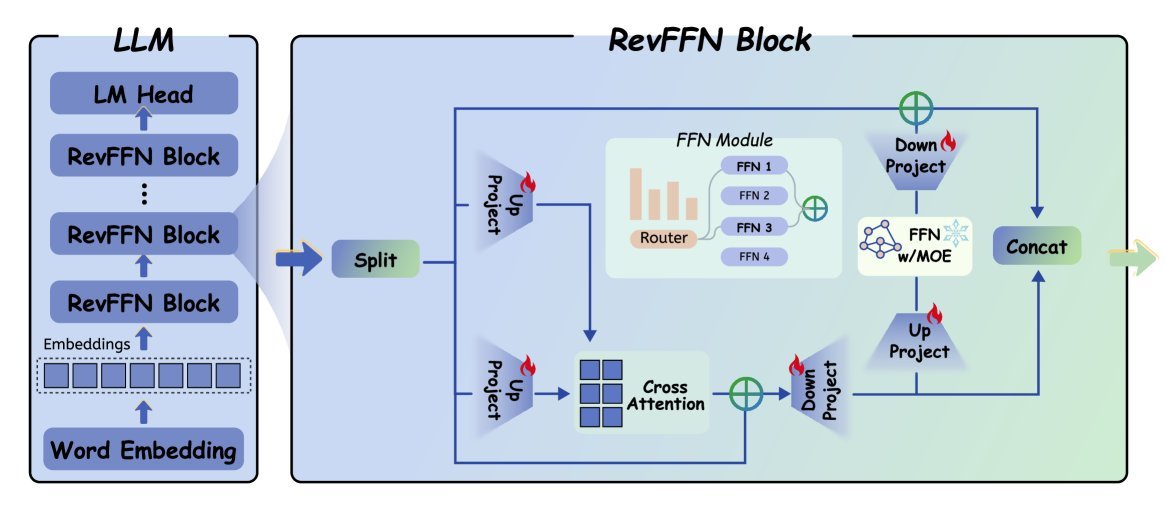
具体来说,它将输入特征 $H$ 沿着特征维度一分为二,变成 $X_1$ 和 $X_2$ 两股“流”。这两股流通过一种耦合更新规则进行交替处理:
\[Y_1 = X_1 + \text{Attention}(X_2)\] \[Y_2 = X_2 + \text{MoE-MLP}(Y_1)\]这种设计保证了数学上的可逆性。在反向传播时,只需简单的减法就能从 $Y_1, Y_2$ 还原出 $X_1, X_2$,从而消除了存储大部分中间激活值的需求。
2. 解决维度不匹配:投影适配器
这里有个棘手的问题:预训练好的 MoE 模型(比如 Qwen1.5-MoE)的权重矩阵是针对完整维度 $d_{model}$ 设计的,而 RevFFN 将输入切分成了 $d_{model}/2$。如果直接重训权重,预训练的知识就废了。
为了解决这个问题,RevFFN 引入了轻量级的投影适配器(Projection Adapters)。
-
升维 ($P_{\uparrow}$):在进入 Attention 或 MoE 层之前,把 $d/2$ 维的输入投影回 $d$ 维。
-
降维 ($P_{\downarrow}$):在计算完之后,再把 $d$ 维的输出投影回 $d/2$ 维。
这一招非常高明,它确保了所有复杂的计算(如注意力矩阵乘法、MoE 路由)依然在原始的高维空间进行,完美保留了预训练模型的能力,而新增的参数量几乎可以忽略不计。
两阶段训练:稳扎稳打
为了让改动后的模型能顺利继承“前辈”的功力,RevFFN 采用了一种两阶段训练策略:
-
适配器热身(Adapter Warm-up):冻结所有预训练权重,只训练新加入的投影适配器。这就像是让新零件先磨合一下,适应老机器的运转。
-
联合全量微调(Joint Fine-tuning):解冻 Transformer 层,进行端到端的全量训练(MoE 的路由网络通常保持冻结以维持稳定性)。
实验证明,这种策略比直接上来就全量微调效果要好得多,能有效避免灾难性遗忘。
实验结果:单卡战群雄
研究团队在 Qwen1.5-MoE-A2.7B 模型上进行了验证,结果令人印象深刻。
-
显存占用大幅下降:相比于标准的 SFT(监督微调),RevFFN 的显存占用几乎减半。
-
性能超越 LoRA:在 MMLU(多任务理解)、GSM8K(数学推理)和 MT-Bench(多轮对话)等多个权威基准测试中,RevFFN 的表现全面超越了 LoRA 和 DoRA 等主流 PEFT 方法,甚至在某些指标上优于标准的全量微调。
这意味着,RevFFN 不仅让你“买得起马”(降低显存门槛),还让你“跑得快”(保持全量微调的高性能)。
总结
RevFFN 的出现,打破了“全量微调必须依赖昂贵集群”的刻板印象。通过引入可逆架构,它成功地在单张 GPU 上实现了 MoE 大模型的全量微调,且没有牺牲模型性能。
对于那些手握有限算力,但又渴望挖掘大模型全部潜力的开发者和研究者来说,RevFFN 无疑是一个极具吸引力的选择。它告诉我们:在算法层面的精巧设计,有时比单纯堆砌硬件更能解决核心痛点。