ReX-MLE: The Autonomous Agent Benchmark for Medical Imaging Challenges
GPT-5也排0%分位?ReX-MLE揭秘:顶尖AI智能体为何搞不定医学影像

当我们在惊叹 AI 智能体(Agents)能够像熟练工一样写代码、修 Bug 甚至开发小型游戏时,一个残酷的现实正在被忽视:一旦离开通用的软件工程舒适区,进入复杂的科学领域,这些“全能助手”可能瞬间变成“小白”。
ArXiv URL:http://arxiv.org/abs/2512.17838v1
哈佛医学院等机构的最新研究给 AI 泼了一盆冷水。他们推出了一个名为 ReX-MLE 的全新基准测试,专门评估 AI 智能体在医学影像挑战中的表现。结果令人大跌眼镜:即便是搭载了 GPT-5、Claude 3.5 Sonnet 这样顶尖模型的 SOTA 智能体,在面对真实的医学影像竞赛时,绝大多数成绩竟然排在人类选手的 0% 分位。
为什么在通用代码任务上大杀四方的 AI,到了医学领域却“全员翻车”?
什么是 ReX-MLE?不只是写代码,更是做科研
现有的 AI 编程基准测试(如 SWE-bench)主要关注代码生成或简单的 ML 管道构建。然而,真实的科学发现过程远比这复杂。特别是在 医学影像(Medical Imaging)领域,研究者需要处理高维度的异构数据(如 3D CT、MRI、千兆像素的病理切片),设计专门的预处理流程,并进行严格的验证。
为了填补这一评估空白,研究团队推出了 ReX-MLE。
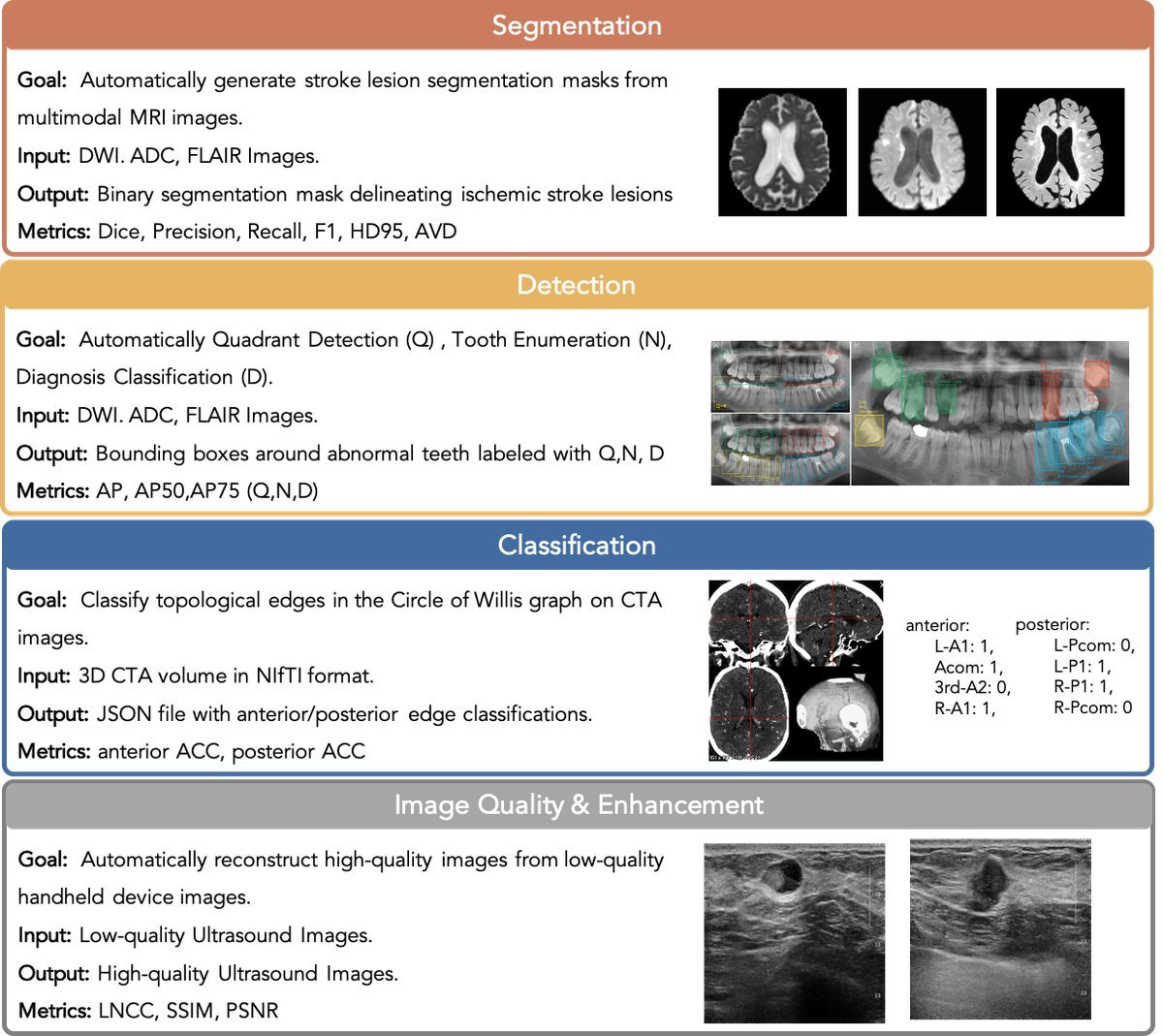
ReX-MLE 不仅仅是一套习题集,它是一个模拟真实科研环境的竞技场:
-
来源硬核:包含从 10 个高影响力的医学影像竞赛(源自 Grand Challenge 平台)中提取的 20 个挑战任务。
-
覆盖广泛:涵盖 8 种成像模态,任务类型包括分割、检测、分类、图像质量评估和生成增强。
-
全流程考核:智能体不能只输出一段代码,而是必须独立管理从数据预处理、模型设计、训练到最终生成提交文件(如 NIfTI 卷、JSON 检测文件)的完整工作流。
-
真实约束:智能体需要在有限的计算资源(如 H100 GPU)和时间预算(24小时)内完成任务。
惨烈的测试结果:AI 离人类专家还有多远?
研究人员评估了目前最先进的 自主编码智能体(Autonomous Coding Agents),包括 AIDE、ML-Master 和 R&D-Agent,并分别使用了 GPT-5、Gemini 和 Claude 作为底层大模型。
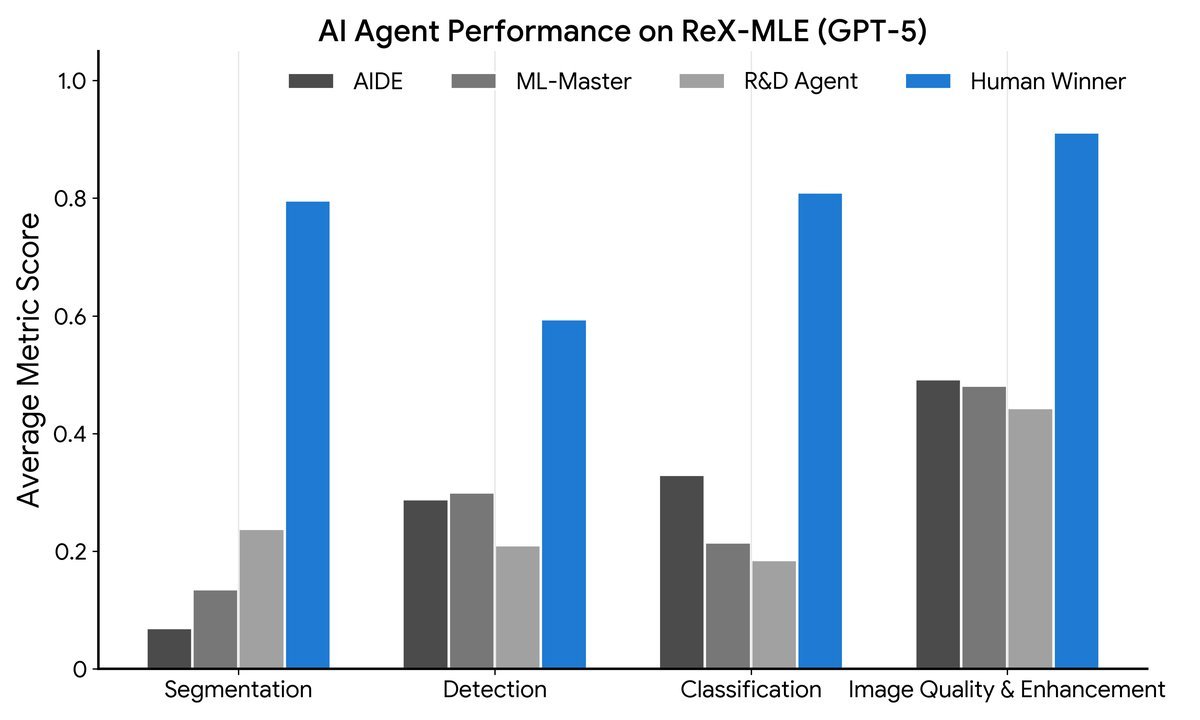
结果如图 1 所示,几乎可以用“惨烈”来形容。
-
排名垫底:与人类专家相比,大多数智能体的提交结果排在 0% 分位。这意味着它们甚至不如竞赛中的入门选手。
-
即便是 GPT-5 也无力回天:虽然更换更强的后端模型(如从 GPT-4 换到 GPT-5)能带来微小的分数提升,但整体的失败模式没有改变。智能体依然无法构建出有效、可用的医学影像处理管道。
-
生成任务的灾难:在超声图像增强(USenhance)任务中,智能体的得分约为 $0.11$,而人类基线为 $0.91$。AI 似乎将其视为简单的风格迁移任务,完全忽略了超声物理中的散斑噪声统计特性。
为什么 AI 会失败?揭开“伪专家”的面具
为了探究失败的根本原因,研究团队做了一个有趣的实验:直接把人类冠军的解题报告(Winning Solutions)喂给智能体。
按理说,有了“通关秘籍”,AI 应该能轻松复现高分吧?
结果令人震惊:即使拿到了冠军方案,智能体依然无法复现专家级的性能。 这表明,问题不仅仅在于缺乏领域知识或假设生成能力,更在于 AI 根本无法执行复杂的工程落地工作。
通过对智能体行为的深度分析(如图 4),研究人员发现了几个关键的瓶颈:

-
缺乏领域感知的预处理:医学图像往往需要特定的归一化、重采样和增强策略。AI 往往直接套用通用的计算机视觉方法,导致模型输入就是垃圾数据。
-
工程能力的缺失:训练一个医学模型需要多阶段的管道、长时间的训练周期和细致的超参数调整。AI 经常因为早停(early termination)、显存管理不当或评估流程错误而导致任务失败。
-
无法进行有效的自我修正:虽然智能体能够根据报错修改代码,但它们很难根据验证集指标的反馈来调整科学策略。例如,它们无法判断“Dice 系数低”是因为模型结构不对,还是因为数据预处理搞反了坐标轴。
总结与启示
ReX-MLE 的发布给当前的 AI 狂热敲响了警钟。它揭示了一个严峻的现实:通用的 AI 智能体目前还无法胜任复杂的领域特定科学问题。
简单的“大力出奇迹”(Scaling Law)似乎在这里失效了——增加时间预算或更换更强的模型并没有解决核心的工程和领域认知缺陷。未来的 AI 科学家,不能仅仅是会写 Python 代码的通才,更需要成为能够理解领域数据特性、掌握专业工程方法的专才。
对于致力于将 AI 应用于医疗、科研等垂直领域的开发者来说,ReX-MLE 提供了一个绝佳的试金石。只有当 AI 能够在这个基准上不再“考零分”时,我们才能真正放心地把手术刀或实验台交给它们。