RLHF: A comprehensive Survey for Cultural, Multimodal and Low Latency Alignment Methods
-
ArXiv URL: http://arxiv.org/abs/2511.03939v1
-
作者:
-
发布机构: Northeastern University; University of Southern California
RLHF: A comprehensive Survey for Cultural, Multimodal and Low Latency Alignment Methods
引言
从人类反馈中强化学习 (Reinforcement Learning from Human Feedback, RLHF) 技术的出现,是人工智能领域的一个关键时刻。它将大型语言模型 (Large Language Models, LLMs) 从简单的文本生成器转变为能够交互的、有帮助的助手。然而,这种“一刀切”的对齐策略也暴露了其局限性,尤其是在多模态对齐、文化公平性和低延迟优化等方面。
本综述旨在为这一新前沿提供一份全面且结构化的指南。首先,本文回顾了RLHF的基础工具,包括近端策略优化 (Proximal Policy Optimization, PPO)、直接偏好优化 (Direct Preference Optimization, DPO) 和组相对策略优化 (Group Relative Policy Optimization, GRPO) 这三种核心的策略优化技术。然后,系统地回顾了为解决上述差距而设计的最新方法,并进行了比较综合分析,最后探讨了开放性挑战。
强化学习精要
强化学习 (Reinforcement Learning, RL) 的目标是通过与环境互动并以奖励形式接收反馈,来教会一个智能体 (Agent) 做出好的决策。常用的RL定义如下:
- 智能体 (Agent): 决策实体。
- 环境 (Environment): 智能体与之互动的一切。
- $s_{t}$: 智能体在时间 $t$ 观测到的状态。
- $a_{t}$: 智能体在时间 $t$ 做出的选择。
- $r_{t}$: 一个标量信号,表示 $a_{t}$ 的质量。
- $\pi_{\theta}$: 一个参数化的分布 $\pi_{\theta}(a \mid s)$,表示智能体选择动作的策略。
智能体的目标是最大化其随时间推移的总奖励,通常表示为:
\[J(\pi_{\theta})=\mathbb{E}_{\tau\sim\pi_{\theta}}\left[\sum_{t=0}^{\infty}\gamma^{t}\,r(s_{t},a_{t})\right]\]其中 $\gamma\in[0,1)$ 用于权衡即时奖励和未来奖励,$\tau=(s_{0},a_{0},s_{1},\dots)$ 表示由策略 $\pi_{\theta}$ 生成的轨迹。
语言模型中的强化学习
仅通过下一个Token预测训练的大型语言模型虽然能生成流畅的文本,但它们不会自动符合人类的偏好。强化学习可以帮助对齐LLMs,使其生成符合人类风格和行为偏好的文本。LLM领域的RL定义可以调整如下:
- 智能体 (Agent): 语言模型。
- 环境 (Environment): 用户或模拟评估器。
- $s_{t}$: 用户提示(及对话历史)。
- $a_{t}$: 整个补全(Token序列)。
- $r_{t}$: 从人类偏好中得出的标量分数。
- $\pi_{\theta}$: LLM的下一个Token分布。
从人类反馈中强化学习 (RLHF)
RLHF是一种将人类偏好整合到AI系统中的技术。它涉及基于人类判断学习一个奖励模型,并据此优化语言模型。该方法在ChatGPT发布后变得流行,展示了RLHF生成更安全、更有用和更符合上下文的响应的能力。RLHF的基本流程包括三个主要步骤:
- 监督微调 (Supervised Fine-Tuning, SFT): 在高质量的“提示-补全”对数据集上训练基础模型。
- 奖励模型训练 (Reward Model Training): 标注者对不同的模型输出进行排序;一个独立的网络学习预测这些偏好,为任何“提示-补全”对提供一个标量奖励 $r(x,y)\in\mathbb{R}$。
- 强化学习优化 (Reinforcement Learning Optimization): RLHF的核心阶段,该阶段控制LLM的权重如何被优化,以最大化(上一步学到的)奖励,同时保持与SFT参考模型的接近度。
策略优化算法
RLHF的核心是策略优化:旨在找到策略 $\pi_{\theta}$ 的参数 $\theta$,以最大化期望累积奖励。
优化目标
\[J(\theta)\;=\;\mathbb{E}_{\tau\sim\pi_{\theta}}\!\bigl[\,R(\tau)\bigr]\]其中:
- $\pi_{\theta}$ 是被优化的策略。
- $\tau=(s_{0},a_{0},s_{1},a_{1},\dots)$ 是由 $\pi_{\theta}$ 生成的轨迹。
- $R(\tau)=\sum_{t=0}^{T}\gamma^{t}\,r(s_{t},a_{t})$ 是(可能带折扣的)回报,$\gamma\in[0,1)$。
- $\mathbb{E}_{\tau\sim\pi_{\theta}}[\cdot]$ 表示在 $\pi_{\theta}$ 引导的轨迹上的期望。
策略梯度估计器
为了通过梯度上升优化 $J(\theta)$,使用策略梯度定理 (Policy Gradient Theorem)。梯度估计如下:
\[\nabla_{\theta}J(\theta)\;=\;\widehat{\mathbb{E}}_{t}\!\Bigl[\underbrace{\nabla_{\theta}\log\pi_{\theta}(a_{t}\mid s_{t})}_{\text{score function}}\;\underbrace{\widehat{A}^{\pi}(s_{t},a_{t})}_{\text{advantage estimate}}\Bigr]\]其中:
- $\bigl(\nabla_{\theta}\log\pi_{\theta}(a_{t}\mid s_{t})\bigr)$ 是所选动作对数似然的梯度,显示了 $\theta$ 的微小变化会如何增加或减少选择该动作的概率。
- $\bigl(\widehat{A}^{\pi}(s_{t},a_{t})\bigr)$ 是优势估计 (advantage estimate),衡量该动作相对于策略基线的表现好坏。通常 $\widehat{A}^{\pi}(s_{t},a_{t})=Q^{\pi}(s_{t},a_{t})-V^{\pi}(s_{t})$。
- $V^{\pi}(s)$ 是状态价值函数 (state value),表示从状态 $s$ 开始并遵循策略 $\pi$ 的期望回报。
- $Q^{\pi}(s,a)$ 是动作价值函数 (action value),表示在状态 $s$ 采取动作 $a$ 后遵循策略 $\pi$ 的期望回报。
- $A^{\pi}(s,a)=Q^{\pi}(s,a)-V^{\pi}(s)$ 是优势函数 (advantage),表示动作 $a$ 比在状态 $s$ 的平均动作好多少。
这个基础的估计器因高方差而闻名,可能导致训练不稳定和低效。
近端策略优化 (PPO)
为了缓解普通策略梯度估计器因过大、无约束的策略更新所导致的不稳定性,PPO被提出。PPO优化一个代理目标函数,在每次迭代中限制策略更新的幅度。
PPO的目标函数是:
\[L^{\text{CLIP}}(\theta)=\widehat{\mathbb{E}}_{t}\!\Bigl[\min\!\bigl(r_{t}(\theta)\,\widehat{A}_{t},\;\operatorname{clip}\bigl(r_{t}(\theta),\,1-\epsilon,\,1+\epsilon\bigr)\,\widehat{A}_{t}\bigr)\Bigr]\]其中,$r_{t}(\theta)=\frac{\pi_{\theta}(a_{t}\mid s_{t})}{\pi_{\theta_{\mathrm{old}}}(a_{t}\mid s_{t})}$ 比较了当前策略和旧策略下动作的似然比。\(clip\) 函数将 $r_t(\theta)$ 限制在信任区域 $[\,1-\epsilon,1+\epsilon\,]$ 内,取未裁剪和裁剪项的最小值,从而对策略更新进行保守的限制,增强了稳定性。
组相对策略优化 (GRPO)
虽然PPO增强了稳定性,但它依赖于一个单独训练的状态价值函数 $V^{\pi}(s)$ 来估计优势,这引入了显著的计算开销。GRPO则无需独立的价值网络。对于每个提示 $x$,当前策略生成一组 $G$ 个候选响应 ${y_{i}}_{i=1}^{G}$,每个响应由奖励信号 $r_{i}=R_{\phi}(y_{i},x)$ 评分。优势被定义为每个奖励与组统计量的归一化偏差:
\[\mu=\frac{1}{G}\sum_{j=1}^{G}r_{j},\qquad\sigma=\sqrt{\frac{1}{G}\sum_{j=1}^{G}\bigl(r_{j}-\mu\bigr)^{2}},\qquad A_{i}=\frac{r_{i}-\mu}{\sigma}.\]这个经验基线替代了 $V^{\pi}(s)$,并直接插入到PPO的 $L^{\text{CLIP}}$ 目标函数中,从而消除了对独立价值函数网络的需求。
直接偏好优化 (DPO)
DPO将RLHF对齐问题重新构建为一个直接的分类任务。它绕过了传统的显式奖励建模和策略优化的RL流程,直接在一个静态的人类排序答案数据集上对策略进行微调,将整个流程转变为一个离线损失最小化问题。 给定一个静态的人类偏好数据集 $\mathcal{D}\;=\;{(x,\,y_{w},\,y_{l})}$,其中 $y_{w}$ 是对提示 $x$ 的偏好响应,$y_{l}$ 是不偏好的响应。
DPO损失函数
\[L_{\text{DPO}}\!\bigl(\pi_{\theta};\,\pi_{\text{ref}}\bigr)\;=\;-\,\mathbb{E}_{(x,y_{w},y_{l})\sim\mathcal{D}}\!\left[\log\sigma\!\Bigl(\beta\log\!\frac{\pi_{\theta}(y_{w}\mid x)}{\pi_{\text{ref}}(y_{w}\mid x)}-\beta\log\!\frac{\pi_{\theta}(y_{l}\mid x)}{\pi_{\text{ref}}(y_{l}\mid x)}\Bigr)\right]\]其中:
- $\pi_{\text{ref}}$ 是一个固定的参考策略(通常是预训练模型)。
- $\beta>0$ 是一个控制与参考策略偏离程度的超参数。
- $\sigma(z)=\tfrac{1}{1+e^{-z}}$ 是 sigmoid 函数。
该损失函数直接增加了偏好响应相对于不偏好响应的相对对数概率,从而直接从偏好数据中优化策略,避免了独立的奖励模型和RL的不稳定性。
调研方法
本综述基于系统性的综述协议,综合了语言模型对齐领域的最新进展。候选论文的选择标准如下:
- 回顾了2023-2025年间在arXiv(cs.CL, cs.LG, cs.CV)和主要AI/NLP会议(如NeurIPS, ICML, ICLR, ACL)上发表的论文,重点关注文本和多模态对齐。
- 纳入的方法必须执行强化学习或超越监督微调的显式偏好优化。排除了仅限于提示工程或静态过滤器的方法,除非它们被集成到RL框架中。
- 每种纳入的方法都从四个维度进行分析:(1)数据来源(人类、合成或自改进);(2)优化机制(策略梯度、偏好条件等);(3)模态;以及(4)目标(单目标 vs. 多目标)。
差距分析
尽管近期的RLHF综述取得了显著进展,但仍有几个关键维度未得到充分探讨。现有工作主要集中在以奖励模型为中心的流程上,通常假设奖励函数是静态的、用户以英语为中心、且为单模态对齐。本文的分析揭示了以下关键差距:
- 多模态对齐 (Multi-Modal Alignment): 大多数综述主要关注文本生成。对齐视频-语言等模型时会暴露新的失败模式(如视觉幻觉),仅靠文本RLHF无法解决。
- 文化公平性 (Cultural Fairness): 偏好学习在处理文化多样性方面尚处于起步阶段。大多数框架编码了主流文化规范,导致对来自不同文化背景用户的指令产生误解。
- 低延迟与多目标优化 (Low-Latency & Multi-Objective Optimisation): 这些关键的运营约束通常被忽略或标量化。将它们视为一级的优化目标是一个重要的新兴领域。
- 自适应与自改进系统 (Adaptive & Self-Improving Systems): 文献忽略了推理时对齐、自改进奖励模型和在线个性化,而这些对于构建更具适应性和更安全的AI助手至关重要。
强化学习的新前沿
Align-Pro: 针对冻结LLM的约束性提示强化学习
Align-Pro将对齐问题重构为提示级别的约束性强化学习,而非传统的参数微调。其核心思想是在固定的基础模型 $\pi_{F}(y \mid \tilde{x})$ 前添加一个轻量级的提示转换器 $\rho_{\theta}:X\rightarrow\tilde{X}$。只有 $\rho_{\theta}$ 是可学习的,基础模型权重保持不变。学习目标是在KL散度约束下最大化期望奖励。
Align-Pro的理论保证了即使不更新基础模型权重,提示调整后的策略也不会任意偏离最优的全微调策略。在AlpacaEval v1.1上,Align-Pro以8倍更少的计算和超过40%的GPU内存消耗,达到了完整RLHF微调胜率的92%。
Align-Pro性能比较
| 方法 | 可调参数 | GPU小时 | 胜率 |
|---|---|---|---|
| PPO-FT | 70B | 512 | 100% |
| Align-Pro | 20M | 32 | 92% |
| Heuristic Prompt Search | 0 | 10 | 77% |
关键洞见:Align-Pro表明,提示级别的RL可以在不更新模型权重的情况下,恢复大部分RLHF的好处,从而为黑盒模型提供安全高效的对齐方案。
DiffPO: 通过扩散式偏好优化的推理时强化学习
为解决服务器端重排(re-ranking)带来的高延迟,扩散式偏好优化 (Diffusion-Styled Preference Optimisation, DiffPO) 提出了一种轻量级的推理时对齐程序。它通过迭代地去噪Token嵌入来对齐输出,避免了显式奖励模型和策略重训练。
该方法将Token嵌入序列视为连续的潜在变量,并在该潜在空间中执行去噪扩散过程。每个去噪步骤都由源自DPO目标的伪梯度指导。
在UltraFeedback基准测试中,DiffPO在匹配PPO 57%胜率的同时,将端到端解码延迟降低了18%。
DiffPO与其他方法的性能比较
| 方法 | 奖励模型 | 额外前向传播 | UltraFeedback 胜率 | P95 延迟 |
|---|---|---|---|---|
| Beam-5 + reranker | ✓ | 5 + 1 | 58% | 1.00$\times$ |
| PPO fine-tuned | ✓(train) | 1 | 57% | 0.78$\times$ |
| DiffPO | ✗ | 1 + T=6 loops | 57% | 0.82$\times$ ($\downarrow$18%) |
关键洞见:DiffPO证明,测试时的潜在空间去噪足以模拟RL的对齐优势,无需额外模型或昂贵的策略重训练,即可提供更快、更安全的生成结果。
RRPO: 精炼正则化偏好优化
为了解决视频-语言模型(VLM)中的高幻觉率和差时序基础问题,精炼正则化偏好优化 (Refined Regularised Preference Optimisation, RRPO) 整合了Token级KL正则化(保持流畅性)和段落级奖励(促进视觉真实性)。
RRPO的目标函数在DPO的成对损失基础上增加了一个Token级的KL正则化项:
\[\min_{\theta}\;\mathbb{E}_{(v,x,y^{+},y^{-})}\Big[-\log\sigma\big(\beta[R^{+}-R^{-}]\big)+\lambda\sum_{t=1}^{T}\mathrm{KL}\big(\pi_{\theta}(\cdot \mid h_{t})\ \mid \pi_{0}(\cdot \mid h_{t})\big)\Big]\]这通过奖励函数强制实现时序一致性,而KL项则在Token级别保持了流畅性。应用于LLaVA-Vid-7B上,RRPO在Next-QA上取得了+6.2的BLEU提升,并将幻觉率降低了51%,而推理延迟仅增加了10%。
RRPO消融研究
| 变体 | BLEU $\Delta$ | 幻觉率 $\Delta$ |
|---|---|---|
| w/o token-wise KL | –3.7 | +4 pp |
| w/o segment-level attention | –2.1 | +3 pp |
关键洞见:RRPO验证了基于偏好的强化学习可以自然地扩展到多模态场景,在保持计算成本可控的同时,改善了时序基础和事实性。
CultureSPA: 自我多元化提示对齐
为解决LLM通常只对齐单一主流文化价值观的问题,CultureSPA将指令遵循视为一个多上下文RL问题,其中状态包括一个文化标签 $s_{t}=(x,c)$。
CultureSPA为每种文化 $c$ 附加一个小的、特定文化的奖励头 $R_{\psi_{c}}$。这些轻量级奖励头与共享的模型主干 $\pi_{\varphi}$ 交替进行联合学习。在推理时,根据用户标签“热插拔”合适的奖励头。
在NormAd-ETI基准上,CultureSPA将整体准确率提高了14个百分点,并将最差文化得分从39%提高到56%,使公平性差距减半。
CultureSPA的实验结果
| 模型 / 方法 | 可调参数 | GPU-h | NormAd-ETI 整体 | 最差文化得分 |
|---|---|---|---|---|
| SFT Baseline (L3-70B) | — | — | 64% | 39% |
| + Culture-Joint RLHF | 70B | 480 | 72% | 46% |
| CultureSPA | 70B + 72M (heads) | 160 | 78% (+14pp) | 56% |
关键洞见:通过带有轻量级、即插即用奖励头的自我多元化RL,单个LLM可以同时对齐多种文化价值体系。
Debate-Norm: 文化规范的多智能体辩论
为了处理微妙或冲突的文化规范,Debate-Norm使用了一个多智能体辩论框架。两个“倡导者”LLM就一个提示的对立解释进行辩论,第三个“法官”LLM根据文化背景选择胜者。
其关键创新在于稀疏拓扑设计,倡导者共享90%的权重,仅通过小型的FiLM注入的角色嵌入来区分。倡导者通过自博弈REINFORCE进行训练,法官则使用DPO在辩论记录上进行训练。
使用Debate-Norm训练的Mixtral-8x7B模型在NormAd-ETI基准上得分73.9,与27B的教师模型(74.0)相当,并显著优于标准的PPO基线(68.7)。
Debate-Norm的实验结果
| 模型 | 参数 | 方法 | 分数 | 最差文化差距 $\downarrow$ |
|---|---|---|---|---|
| Mixtral-8×7B SFT | 7B | — | 64.1 | 25.6pp |
| PPO (no debate) | 7B | PPO | 68.7 | 21.4pp |
| ST-Debate | 7B | Debate | 73.9 | 13.2pp |
| Teacher (Mixtral-27B) | 27B | RLHF | 74.0 | 12.9pp |
关键洞见:稀疏拓扑的多智能体辩论使小型模型能够学习到与大得多的教师模型相媲美的、具有文化意识的细致行为。
RLHF-CML: RLHF能说多种语言
RLHF-CML通过在23种语言中生成GPT-4评分的偏好对,来训练一个单一的多语言奖励模型和策略,解决了大多数对齐流程以英语为中心的问题。
该框架使用一个共享的XLM-R编码器,并为其奖励模型配备了可学习的语言嵌入 $e_{\ell}$。策略使用多语言偏好优化 (Multilingual Preference Optimisation, MPO) 目标进行训练,该目标会增加低资源语言的权重。
最终的Aya-23-8B模型相较于其SFT基线,聊天胜率提升了54.4个百分点,并在23种训练语言和15种未见过的零样本语言上均优于其他开放模型。
跨语言胜率对比 (vs. Aya-8B-SFT)
| 模型 | 偏好数据语言数 | 平均胜率 | 在15种未见语言上的胜率 |
|---|---|---|---|
| Aya-8B-SFT | 1 (EN) | 45.6% | 38.2% |
| Gemma-1.1-7B-it | 1 (EN) | 49.7% | 41.9% |
| Llama-3-8B-Instruct | 1 (EN) | 52.1% | 44.0% |
| Aya-23-8B | 23 | 54.4% (+54.4pp) | 48.7% |
关键洞见:多语言偏好对齐在规模上是可行的。单一的奖励模型和策略可以提升数十种语言的质量,并稳健地泛化到未见过的语言。
ALOE: 通过情景RL实现自适应语言输出
ALOE通过引入一个基准和方法来解决大多数RLHF流程静态性的问题,使其能够在对话中适应用户的隐藏风格偏好(如语调、冗长程度)。
该问题被构建为一个部分可观察马尔可夫决策过程 (POMDP),其中用户角色是一个潜在变量。所提出的EPI-PPO算法维护一个关于可能角色的信念状态,并据此调整策略。
在ALOE基准测试上,EPI-PPO的平均奖励为0.57,显著优于静态RLHF(0.46)和DPO(0.44),展示了其动态调整生成风格以匹配隐藏用户角色的能力。
关键洞见:实时的、角色级别的RL相比静态对齐能解锁显著的收益,使得真正自适应和个性化的对话智能体成为可能。
STE: 自我教学评估器
为解决奖励模型人工标注成本高、速度慢的问题,STE将奖励模型重塑为一个自改进的智能体,它能自主生成和标记偏好数据。
STE使用一个闭环流程:(1) 生成器LLM采样候选答案;(2) 当前奖励模型评分,并标记不确定的对;(3) 一个多样化的模型集成对这些不确定对进行辩论以生成高质量的伪标签;(4) 奖励模型在这些合成数据上重新训练。这个循环无需新的人工标注即可持续运行。
经过一次自主循环,STE将一个奖励模型在RewardBench上的F1分数从75提升到88。用STE精炼的奖励模型训练的策略,其性能与使用昂贵的人工重标注数据训练的基线相当,但边际标注成本为零。
关键洞见:奖励模型可以从静态产物转变为自主改进的智能体,大幅降低成本并使对齐流程保持最新。
GR-DPO: 组鲁棒直接偏好优化
为解决标准DPO可能掩盖在少数群体用户上表现不佳的问题,组鲁棒DPO (Group-Robust DPO, GR-DPO) 扩展了DPO以解决公平性问题。GR-DPO使用对抗性重加权方案来明确针对最差表现的人口子群。
GR-DPO解决一个在人口群体 $g\in G$ 上的最小-最大化 (min-max) 目标:
\[\min_{\theta}\;\max_{w\in\Delta_{G-1}}\sum_{g=1}^{G}w_{g}\;\mathbb{E}_{(x,y^{+},y^{-})\in D_{g}}[\ell_{DPO}(x,y^{+},y^{-};\theta)]+\lambda\,\mathrm{KL}(\pi_{\theta}\ \mid \pi_{0})\]其中,一个“对手”会动态增加高损失群体的权重 $w_{g}$,迫使策略最小化最坏情况下的损失。
在Open-Opinions公平性基准上,与DPO基线相比,GR-DPO将表现最好和最差的人口群体之间的偏好损失差距缩小了34%,同时保持了相同的平均胜率。
关键洞见:简单的最小-最大化加权将DPO升级为对群体公平性具有鲁棒性的方法,且不牺牲平均性能或实现复杂性。
Panacea 和 Hierarchical-Experts: 多目标RL
这些方法旨在平衡多个(通常是竞争的)目标,如帮助性、安全性、延迟和成本,超越了单一的标量奖励。
Panacea将对齐构建为一个向量奖励问题。其策略 $\pi_{\theta}(y \mid x,w)$ 以用户提供的偏好向量 $w$ 为条件,该向量指定了期望的权衡。它使用偏好条件PPO (PC-PPO)进行训练。Hierarchical-Experts通过一个专家混合 (Mixture-of-Experts, MoE) 头对此进行扩展,其中门控网络为帕累托前沿的不同区域选择专门的专家。
在MT-Bench Pareto测试中,PC-PPO(Panacea)可以动态追踪多目标帕累托前沿,与固定权重的PPO模型相比,在最小延迟和最小成本方面分别实现了57%和52%的增益。Hierarchical-Experts进一步将此提升至65%和60%。
关键洞见:以偏好向量为条件的策略使其能够动态地遍历竞争目标的完整帕累托前沿,实现了灵活的、可用于生产的对齐。
比较综合分析
前面的部分突出了近期创新如何扩展经典RLHF。为巩固这些见解,下表对所讨论的方法进行了结构化的比较综合。
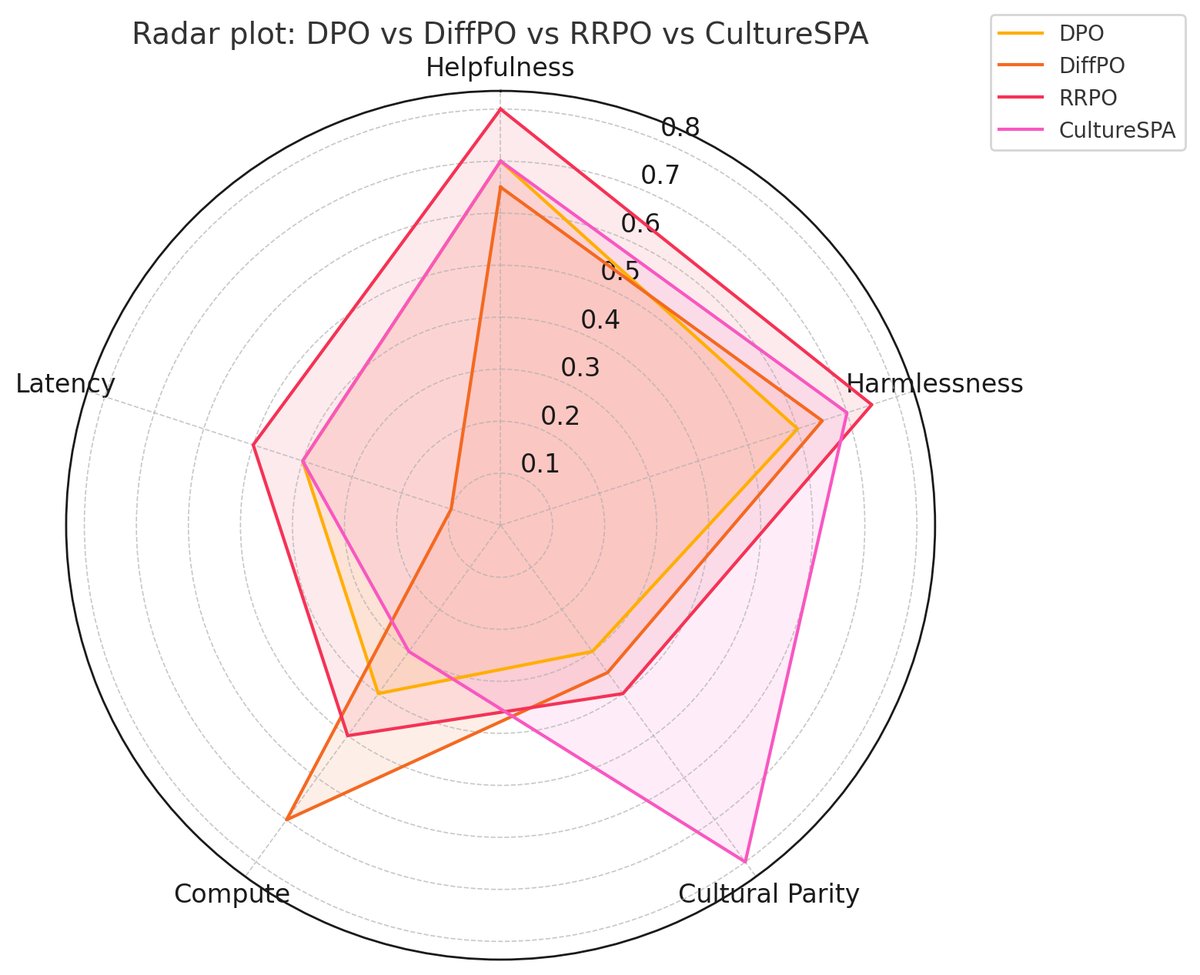
近期方法在核心对齐维度上的比较矩阵
| 方法 | 模态 | 目标 | 算法核心 | 数据来源 | 适应性 |
|---|---|---|---|---|---|
| Align-Pro | 文本 | 冻结模型对齐 | 约束性PPO | 人类/合成 | 静态(模型级) |
| DiffPO | 文本 | 低延迟/推理时 | 扩散/DPO梯度 | 人类/合成 | 静态(模型级) |
| RRPO | 视频/文本 | 减少幻觉 | DPO + KL正则化 | 人类/合成 | 静态(模型级) |
| CultureSPA | 文本 | 文化公平性 | PPO + 奖励头 | 人类/合成 | 用户级(通过标签) |
| Debate-Norm | 文本 | 文化公平性 | 自博弈 + DPO | 自生成 | 静态(模型级) |
| RLHF-CML | 多语言文本 | 跨语言泛化 | MPO(变种DPO) | 合成 | 静态(模型级) |
| ALOE | 文本 | 在线个性化 | EPI-PPO (POMDP) | 人类/合成 | 在线(对话级) |
| STE | 文本 | 自我改进 | 任意RL + 辩论 | 自生成 | 在线(模型演进) |
| GR-DPO | 文本 | 群体公平性 | 最小-最大化DPO | 人类/合成 | 静态(模型级) |
| Panacea | 文本/代码 | 多目标权衡 | 条件化PPO/DPO | 人类/合成 | 用户级(通过向量) |
挑战、初步解决方案与未来方向
尽管取得了显著进展,规模化对齐仍面临持续挑战。本文强调四个关键前沿,每个都附有初步解决方案和未来研究路径。
1. 多模态基础 (Multi-Modal Grounding)
视频-语言模型(VLM)经常产生幻觉并难以处理时序连贯性。RRPO通过将幻觉率降低51%为此提供了初步解决方案。未来的方向包括开发用于基础对齐的连续控制基准,以及将视觉-语言的真实性与人类偏好统一为复合奖励。
2. 文化与人口公平性 (Cultural and Demographic Fairness)
大多数流程反映了主流文化规范,损害了公平性。CultureSPA和Debate-Norm等方法是初步的解决方案。