RMAAT: Astrocyte-Inspired Memory Compression and Replay for Efficient Long-Context Transformers
模拟大脑“胶质细胞”!RMAAT解锁线性注意力,长序列训练显存效率暴涨

Transformer 架构虽然统治了自然语言处理领域,但它一直背负着一个沉重的“包袱”:自注意力机制的二次方复杂度($O(N^2)$)。这使得处理超长序列变得极其昂贵,甚至在硬件上不可行。为了解决这个问题,研究人员尝试了稀疏注意力、线性近似等各种魔改,但往往要在性能和效率之间做艰难的取舍。
ArXiv URL:http://arxiv.org/abs/2601.00426v1
如果我们的灵感来源——大脑,其实还有一半的计算潜力没被挖掘呢?
宾夕法尼亚州立大学(PSU)的研究团队提出了一种全新的视角:不要只盯着神经元,看看星形胶质细胞(Astrocytes)吧! 他们发布的 RMAAT(Recurrent Memory Augmented Astromorphic Transformer)模型,通过模拟大脑中星形胶质细胞的记忆和突触调节机制,不仅实现了线性的注意力复杂度,还通过一种独特的“记忆回放”训练算法,大幅降低了长序列训练的显存占用。
为什么是星形胶质细胞?
长期以来,AI 领域的生物启发计算主要关注神经元(Neurons)。然而,大脑中还有大量的胶质细胞,特别是星形胶质细胞,它们不仅仅是神经元的“后勤保障”,更深度参与了突触传递、可塑性调节以及记忆的形成。
RMAAT 的核心理念在于:利用星形胶质细胞的长时程增强(Long-Term Plasticity, LTP)机制来管理长期记忆,利用短时程可塑性(Short-Term Plasticity, STP)来实现高效的注意力计算。
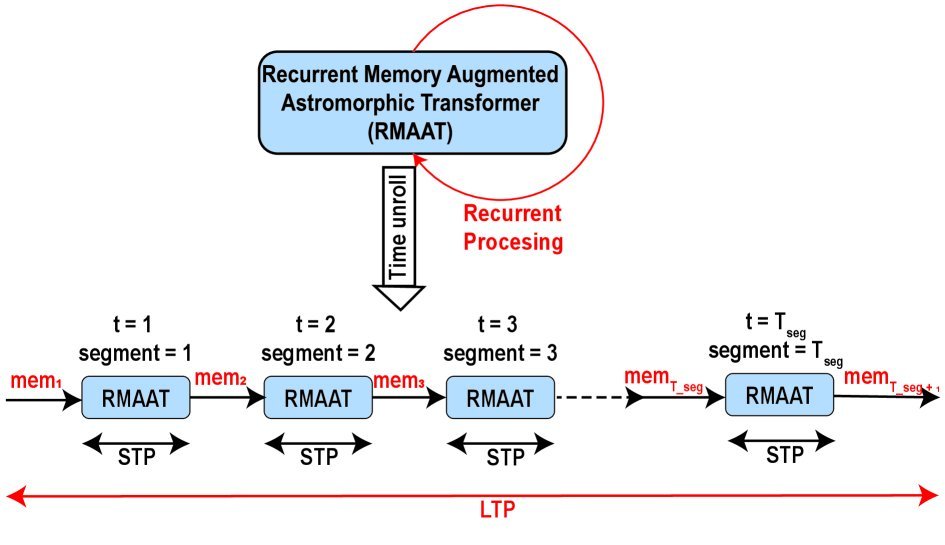
RMAAT 的核心架构:分段与记忆
为了打破 $O(N^2)$ 的魔咒,RMAAT 采用了分段处理(Segmented Processing)策略。它将长序列切分为多个片段,就像阅读长篇小说时分章节阅读一样。
但分段处理最怕的是“读了后章忘前章”。为了解决这个问题,RMAAT 引入了记忆 Token(Memory Tokens)。这些 Token 就像是流动的“笔记”,在处理完一个片段后,会携带上下文信息传递给下一个片段。
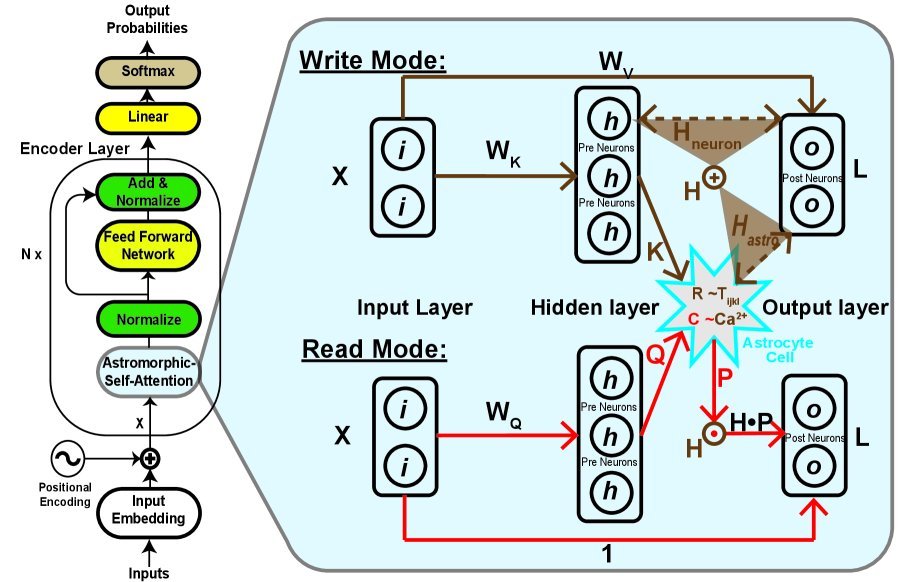
这就引出了 RMAAT 的第一个杀手锏:基于星形胶质细胞的自适应记忆压缩。
与传统的 RNN 或其他 Recurrent Transformer 不同,RMAAT 的记忆更新不是简单的门控机制,而是由一套模拟生物物理过程的微分方程控制的。研究团队提炼了一个宏观计算模型:
\[\tau\_{s}\frac{ds\_{ij}}{dt} \propto-\beta s\_{ij}+\theta(x\_{i})\theta(x\_{j})+\psi(p\_{ij}^{s})\] \[\tau\_{p}^{l}\frac{dp\_{ij}^{l}}{dt}\propto-\gamma^{l}p\_{ij}^{l}+\kappa(s\_{ij})\]这些公式描述了突触活动如何随时间衰减和增强。RMAAT 将其中的 $p^{l}_{ij}$(代表星形胶质细胞的长时程参数)抽象为一个记忆保留因子(Retention Factor)。这个因子能够根据生物学原理,自适应地压缩旧的记忆 Token,确保信息在跨越多个长片段时既不会爆炸,也不会轻易丢失。
线性复杂度的“星形”注意力
在每个片段内部,RMAAT 并没有使用标准的 Softmax Attention,而是设计了一种星形注意力机制(Astromorphic Attention)。
这种机制受到星形胶质细胞短时程可塑性(STP)的启发,将注意力计算分解为“写入”(Write)和“读取”(Read)两个模式,模拟了三方突触(神经元-星形胶质细胞-神经元)的互动:
其数学形式巧妙地转化为线性操作:
\[H\_{neuron}=\frac{1}{m}\phi(K)^{T}V\qquad H\_{astro}=\frac{1}{m}\phi(R)^{T}V\] \[L=\phi(Q)(H\odot P)+X\]这里,$H$ 和 $g$ 等中间变量的维度与序列长度 $N$ 无关,因此计算复杂度被成功降维到了 $O(N)$。这意味着,无论序列多长,计算量的增长都是线性的!
训练黑科技:AMRB 算法
处理长序列的另一个噩梦是显存爆炸。标准的反向传播(BPTT)需要保存整个序列的激活值,这对于超长文本来说是不可承受之重。
RMAAT 提出了一种名为星形记忆回放反向传播(Astrocytic Memory Replay Backpropagation, AMRB)的训练算法。
AMRB 的核心思想是“以计算换空间”。在训练过程中,它不需要存储所有片段的中间激活值,而只存储在片段之间传递的、经过压缩的记忆 Token。
当需要计算梯度时,算法会利用存储的记忆 Token,重新计算当前片段的前向传播(这就是“Replay”),从而恢复激活值。由于记忆 Token 的体积非常小,这种方法极大地降低了显存占用,使得在有限的硬件上训练超长上下文模型成为可能。
实验结果:LRA 榜单上的新星
研究团队在著名的长序列基准测试 Long Range Arena (LRA) 上对 RMAAT 进行了评估。结果显示,RMAAT 在多个任务上不仅击败了标准的 Transformer,还超越了 RMT(Recurrent Memory Transformer)等同类高效模型。
下表展示了 RMAAT 在 LRA 任务上的表现(加粗为最优):
\[\begin{array}{lcccccc} \hline \textbf{Model} & \textbf{ListOps} & \textbf{Text} & \textbf{Retrieval} & \textbf{Image} & \textbf{Pathfinder} & \textbf{Avg} \\ \hline \text{Transformer} & 36.4 & 64.3 & 57.5 & 42.4 & 71.4 & 54.4 \\ \text{Linformer} & 17.1 & 63.6 & 59.6 & 44.2 & 71.7 & 51.2 \\ \text{Linear Trans.} & 16.1 & 65.9 & 53.1 & 42.3 & 75.3 & 50.5 \\ \text{Performer} & 18.0 & 65.4 & 53.8 & 42.8 & 77.1 & 51.4 \\ \text{RMT} & 37.4 & 65.0 & 79.3 & 54.6 & 81.5 & 63.6 \\ \hline \textbf{RMAAT (Ours)} & \mathbf{38.9} & \mathbf{65.9} & \mathbf{83.2} & \mathbf{64.8} & \mathbf{87.1} & \mathbf{68.0} \\ \hline \end{array}\]可以看到,RMAAT 以 68.0 的平均分位居榜首,特别是在需要极长依赖关系的 Pathfinder 任务上达到了 87.1 的高分。
总结来说,RMAAT 的成功证明了生物启发式 AI 不仅仅是模仿大脑的结构,更重要的是借鉴其高效的计算原理。 通过引入星形胶质细胞的动力学机制,RMAAT 为长上下文 Transformer 的设计提供了一条兼具高性能与低资源消耗的新路径。