LLM与人脑“神同步”:Meta AI证实模型越大,计算路径越像人

大型语言模型(LLM)和人类大脑,一个由硅基芯片驱动,一个由碳基神经元构成,它们的思考方式会有共同点吗?
ArXiv URL:http://arxiv.org/abs/2512.01591v1
来自Meta AI、PSL大学等机构的最新研究给出了一个惊人答案:不仅有,而且它们的计算路径还高度同步!
这项研究发现,LLM处理信息的顺序与人脑惊人地相似。
LLM的浅层网络活动对应大脑的早期反应,而深层网络则对应大脑的晚期反应。
这仿佛是AI与人类心智之间的一场“神同步”。
精巧的实验设计:聆听大脑与LLM的“共鸣”
为了探究这一现象,研究团队设计了一个精巧的实验。
他们让受试者在脑磁图(Magnetoencephalography, MEG)扫描仪中,聆听长达10小时的有声读物,并记录下大脑的实时神经信号。

与此同时,研究人员将相同的文本输入到22个不同架构和规模的LLM中(如Llama 3, GPT-2, Mamba等)。
通过一个线性映射模型,他们得以比较LLM每一层的激活状态与大脑在特定时间点的神经信号。
最终,他们提出了一个关键指标:时间对齐分数(Temporal score),用$r$值表示,这个分数越高,说明LLM的计算顺序与大脑的反应时序越一致。
核心发现:惊人的“时间对齐”
研究结果证实了一个普遍现象:LLM和大脑确实以相似的顺序生成表征。
LLM的浅层(输入端)激活,与大脑接收到单词后约200-300毫秒的早期响应最为匹配。
而LLM的深层(输出端)激活,则与大脑约400-500毫秒后的晚期、更高级的语义整合阶段相匹配。
这种“时间对齐”现象非常稳健,在Transformer、循环网络(RNN)甚至Mamba等不同架构的模型上都得到了验证。
这意味着,LLM与大脑的这种计算路径上的趋同,可能是一种超越特定模型架构的普遍规律。
关键因素一:模型越大,越像大脑
那么,是什么因素促成了这种“神同步”呢?第一个关键答案是:模型规模。
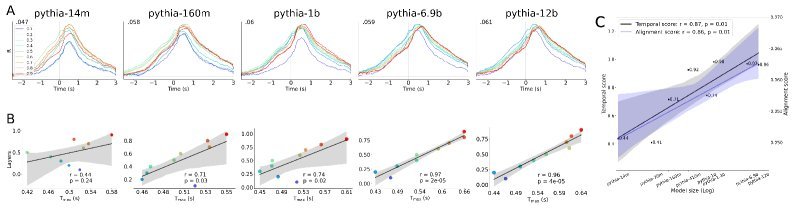
研究团队使用了Pythia模型家族——一系列从1400万到120亿参数、在相同数据上以相同方式训练的模型。
结果清晰地显示,时间对齐现象随着模型规模的增长而出现并增强。
-
对于1400万参数的小模型,时间对齐分数$r$仅为0.44,不具备统计显著性。
-
而对于120亿参数的最大模型,该分数飙升至$r=0.96$,表现出极强的相关性!
简单来说,模型越大,其处理信息的时序就越接近人脑的节律。
关键因素二:上下文越长,越像大脑
如果说模型规模是“硬件”基础,那么上下文长度就是“软件”配置。
研究发现,提供给模型的上下文越长,其时间对齐分数也越高。
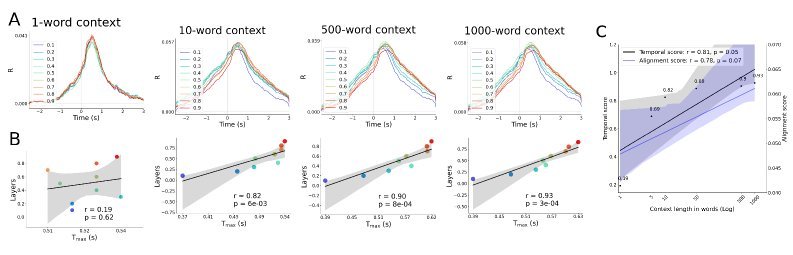
研究人员在Llama-3.2 3B模型上进行了测试,逐步增加输入文本的上下文长度。
-
当没有上下文(仅单个词)时,时间对齐分数$r$仅为0.19。
-
当上下文增加到1000个词时,分数大幅提升至$r=0.93$。
这与人类的语言理解过程非常相似:我们依赖前文的语境来更深刻、更快速地理解当前听到的内容。
超越预测:计算路径的深层共鸣
有人可能会问:这种对齐是否仅仅因为LLM和大脑都在做“下一个词预测”?
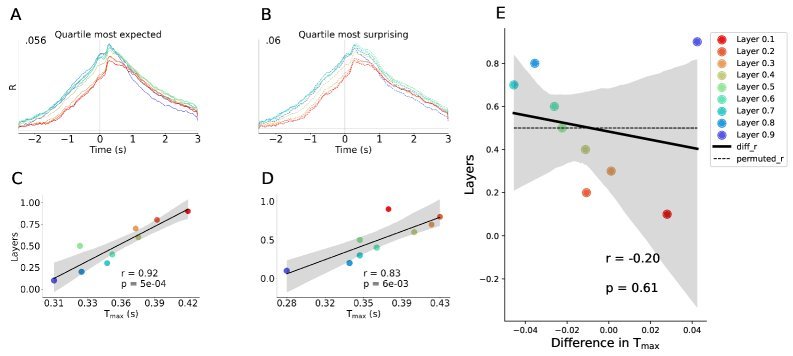
研究团队通过控制实验排除了这种简单的解释。他们发现,无论是对于非常容易预测的词,还是非常出人意料的“惊喜”词,LLM与大脑的时间对齐都非常稳固。
 LLM与人脑惊人同步!Meta AI揭示:模型越大、上下文越长,计算路径越像人
LLM与人脑惊人同步!Meta AI揭示:模型越大、上下文越长,计算路径越像人
大型语言模型(LLM)究竟是如何工作的?它们仅仅是模仿人类语言的统计机器,还是在某种程度上,它们的“思考”过程与人脑有相似之处?
最近,来自Meta AI和法国国家健康与医学研究院(Inserm)等机构的一项重磅研究,为这个问题提供了迄g今为止最直接的证据。研究发现,LLM与人脑在处理语言时,不仅最终的表征相似,连计算过程的“先后顺序”都惊人地一致!
更重要的是,这种“神同步”的程度,与模型的大小和上下文长度直接相关。
实验设计:用10小时有声书“对齐”脑电波与模型
为了探究LLM与人脑计算路径的奥秘,研究者设计了一个巧妙的实验。
他们采集了受试者在收听长达10小时有声书时的脑磁图(Magnetoencephalography, MEG)数据。MEG能够以毫秒级精度捕捉大脑处理语言时的动态神经信号。
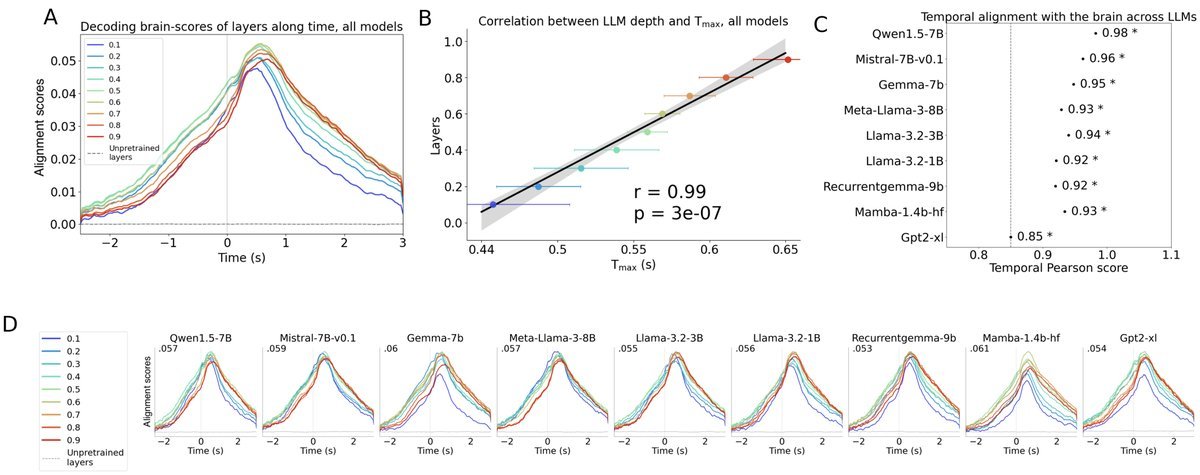
与此同时,研究团队将相同的文本输入到22个不同架构和规模的LLM中(包括Llama 3、GPT-2、Mamba等),并提取出模型每一层的激活值。
通过一个线性模型,他们试图用大脑的MEG信号来预测LLM每一层的激活值。预测的准确度,即对齐分数(Alignment Score),就衡量了大脑和LLM在特定时刻表征的相似性。
\[\hat{W} =\underset{W}{\arg\min}\left\{\ \mid Y-XW\ \mid \_{2}^{2}+\lambda\ \mid W\ \mid \_{2}^{2}\right\}\]关键发现:计算路径的“时间对齐”
研究的核心发现是存在一种显著的时间对齐(Temporal Alignment)。
这意味着,LLM的浅层网络激活,与大脑处理单词后早期的神经反应(约200-300毫秒)最为匹配。
而LLM的深层网络激活,则与大脑后期的、更高级的语义整合阶段的神经反应(约400-500毫秒)最为匹配。
简单来说,从接收一个词开始,大脑和LLM似乎都在沿着一条相似的计算路径前进:从低阶的特征提取,逐步走向高阶的语义理解。
研究者将这种层深度与大脑反应时间的关联度量化为时间分数(Temporal Score),发现几乎所有现代LLM都表现出极高的相关性(平均$r$ = 0.99)。
这个发现意义重大,它表明LLM与人脑的趋同进化,并不仅仅是巧合,也不局限于特定的Transformer架构。
越大越像:模型规模的影响
那么,是什么因素驱动了这种时间对齐呢?研究首先指向了模型规模。
通过分析Pythia系列模型(从1400万到120亿参数,在相同数据上训练),研究者发现了一个清晰的规律:模型越大,其计算路径与人脑的“时间对齐”程度就越高。
如上图所示,14M参数的小模型,其时间分数并不显著($r$ = 0.44)。
而当模型增长到12B参数时,时间分数飙升至惊人的$r$ = 0.96,呈现出非常清晰的线性对齐关系。
这表明,单纯地扩大模型规模,就能让AI的内部计算过程自发地向人脑的语言处理机制靠拢。
上下文越长,对齐越好
除了模型规模,上下文长度是另一个关键变量。
人类理解语言时,会不断累积上下文信息。LLM也是如此。那么,更长的上下文是否也能促进与人脑的对齐呢?
答案是肯定的。
研究团队在Llama-3.2 3B模型上进行了测试,通过改变输入上下文的长度(从单个词到1000个词),他们观察到:
随着上下文窗口的增长,时间对齐分数也呈现出对数级的增长。
当模型只看到当前单词(无上下文)时,时间对齐几乎不存在($r$ = 0.19)。
而当上下文增加到1000个词时,时间分数达到了$r$ = 0.93。
这说明,让模型“看得更远”,能够帮助它形成更像人脑的、循序渐进的推理路径。
预测下一个词并非全部
一个很自然的问题是:这种对齐会不会只是因为LLM和人脑都在做“预测下一个词”这件事?
为了验证这一点,研究者将单词按其可预测性分为四组,从“最意料之中”到“最出乎意料”。
结果发现,无论是处理高预测性的词还是低预测性的词(“惊喜词”),LLM都与人脑保持了显著的时间对齐。
这表明,时间对齐并非简单源于自回归预测任务本身,而是反映了一种更深层次、更普适的语言处理机制。
结论与启示
这项研究为我们理解LLM与人脑的关系打开了一扇新的窗户。
-
首次证实时间对齐:LLM和人脑不仅在表征上相似,其计算路径的“时间顺序”也高度一致。
-
规模与上下文是关键:模型越大、上下文越长,这种计算路径的相似性就越强。
-
架构无关性:这种对齐现象存在于多种架构中(Transformer、Mamba等),暗示了语言处理可能存在某种普适的计算原理。
这些发现表明,尽管LLM的训练方式与人脑的生物进化截然不同,但为了高效地处理语言,它们似乎殊途同归,走向了一条相似的计算道路。
当然,研究也存在局限,例如MEG的空间分辨率有限,受试者数量较少等。但它无疑为我们指明了方向:通过系统性地研究影响对齐的因素,我们或许能最终揭开语言智能的终极奥秘,并构建出更高效、更像人脑的AI系统。