Agent智能进化论:阿里港科大万字综述,揭秘GEF三步循环

大模型Agent正以前所未有的速度发展,但一个巨大的瓶颈也随之浮现:静态数据集已经喂不饱它们了!
论文标题:Scaling Environments for LLM Agents in the Era of Learning from Interaction: A Survey
ArXiv URL:http://arxiv.org/abs/2511.09586v1
依赖人工标注、知识水平受限于人类的数据集,不仅成本高昂,更缺乏真实世界的动态性。如何培养Agent的自适应行为和长期决策能力,让它们超越人类水平?
答案或许不在于模型本身,而在于它们所处的“环境”。
最近,来自阿里巴巴和香港科技大学等机构的研究者发布了一篇重磅综述。该文首次从“环境中心”的视角出发,系统性地梳理了如何为LLM Agent打造一个能够自我进化、无限扩展的“修炼场”。
其核心框架,就是生成-执行-反馈(Generation-Execution-Feedback, GEF)循环。
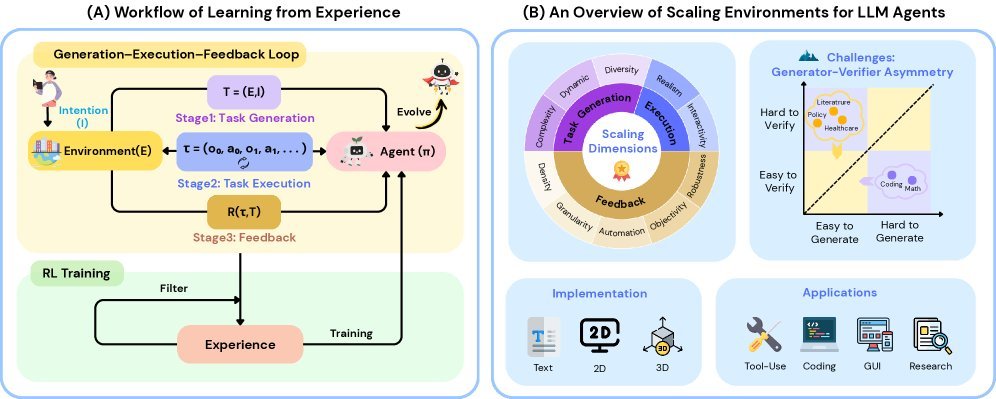
图1: (A) GEF循环示意图;(B) 以GEF为核心的环境扩展方法论
GEF循环:Agent智能进化的核心引擎
传统的AI训练,环境往往只是一个被动的“沙盒”。
而本文提出的GEF循环,将环境的角色彻底颠覆,使其成为经验数据的“主动生产者”。
这个循环包含三个关键阶段:
-
生成 (Generation):环境主动生成富有挑战性的任务,把Agent推向能力边界。
-
执行 (Execution):Agent在环境中执行任务,与环境交互产生行动轨迹。
-
反馈 (Feedback):环境评估Agent的表现,筛选出有价值的经验用于强化学习。
通过一次次GEF循环,Agent的策略不断迭代,能力持续进化,就像一个在高级“陪练”指导下不断成长的学员。
任务生成:动态演化的“无限考题”
一个好的“修炼场”,首先要能源源不断地出题,而且题目的难度和类型要恰到好处。
研究将任务生成的扩展归为三个维度:
-
复杂度扩展:任务从简单的单步指令,演变为需要多步推理、具有层级结构甚至图结构的复杂任务链,考验Agent的组合泛化能力。
-
动态性扩展:环境不再是静止的。它可以根据Agent的表现动态调整任务难度(如R-Zero提出的挑战者-求解者框架),甚至引入异步事件,让环境独立于Agent动态演化(如Meta的ARE平台)。
-
多样性扩展:通过生成跨领域、跨工具集的异构任务,避免Agent过拟合,提升其在未知场景下的泛化能力,如AgentGym、AgentGen等工作所示。
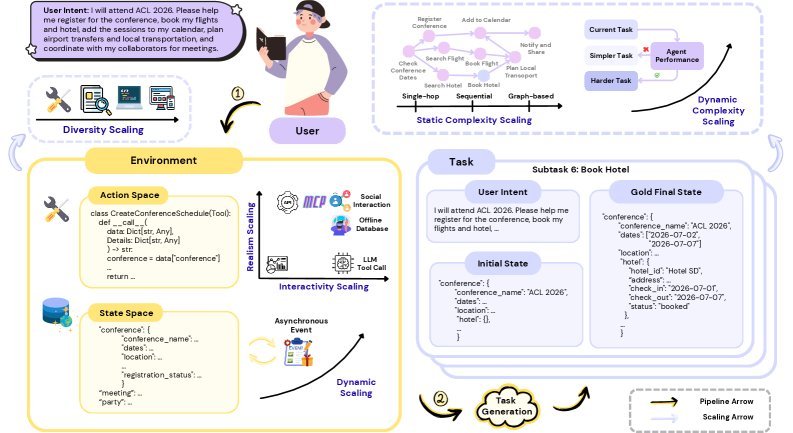
图3: 会议安排任务中的环境扩展示例
任务执行:从“纸上谈兵”到“真实战场”
光有难题还不够,Agent必须能在接近真实的环境中“动手”实践。
-
交互性扩展:早期的Agent训练依赖预设的行动序列,无法根据中间结果调整策略。而新的研究趋势是让Agent能够真正地、交互式地调用真实API或工具。例如,BrowseMaster支持并行调用工具,将交互性提升到了新的高度。
-
真实性扩展d:为了保证Agent学到的经验能在现实世界奏效,环境的真实性至关重要。研究者们正从“模拟API返回结果”转向“调用真实API”或“在与真实世界一致的离线数据库上交互”,确保训练数据与现实世界的一致性。
反馈:打造客观、自动的“智能裁判”
Agent做得好不好,需要一个公正的“裁判”。GEF循环的最后一步,就是提供高质量的反馈信号。
如何扩展反馈的能力?研究指出了五个方向:密度、粒度、自动化、客观性和鲁棒性。
简而言之,理想的反馈系统应该:
-
不仅在任务结束时给出最终评价,更要在过程中提供密集的指导。
-
能够自动、客观地进行评估,减少对昂贵人工标注的依赖。
-
即使面对不确定或开放性任务,也能给出稳定、可靠的奖励信号。
核心挑战:生成器-驗證器不對稱性
一個深刻的洞見是,现实世界存在普遍的“生成器-验证器不对称性(Generator-Verifier Asymmetry)”。
有些任务,验证答案很容易,但生成答案却极难。比如数学问题,验证一个解法(验证器)比从零开始求解(生成器)简单得多。强化学习在“易于验证”的领域取得了巨大成功。
反之,另一些任务,提出问题很容易,但评估答案的好坏却非常困难。例如创意写作、政策制定等开放性问题,评估标准主观且复杂。
这正是当前Agent发展的核心瓶颈之一,也是扩展环境最具挑战、最有价值的地方。如果能利用更强的“生成器”智能来反哺和增强“验证器”,就有可能驱动Agent实现自我进化和能力飞跃。
写在最后
这篇综述为我们描绘了一幅清晰的LLM Agent发展蓝图。
未来的Agent智能,可能不再仅仅取决于模型参数的堆砌,而是更多地依赖于我们能否为其构建一个足够复杂、真实、且富有挑战性的交互式环境。
通过GEF循环,Agent将不再是被动学习的学生,而是能在“无限游戏”中自我成长的智能体。通往通用人工智能的道路,或许就隐藏在这一个个精心设计的“修炼场”之中。