Scaling Reinforcement Learning for Content Moderation with Large Language Models
数据效率暴涨100倍!Meta AI揭秘强化学习在内容审核中的Scaling Law

在当今的数字生态系统中,内容审核(Content Moderation)就像是一场永无止境的猫鼠游戏。面对数十亿条用户生成和AI生成的推文、图片和视频,传统的审核系统往往力不从心。虽然大语言模型(LLM)展现出了惊人的潜力,但要让它们达到“专家级”的审核水平,通常需要极其昂贵且耗时的人工标注数据。
ArXiv URL:http://arxiv.org/abs/2512.20061v1
如果告诉你,只要几百个样本,就能训练出比肩数万样本微调模型的审核AI,你敢相信吗?
Meta AI 最新发表的研究 Scaling Reinforcement Learning for Content Moderation with Large Language Models 揭示了一个令人兴奋的结论:在内容审核任务中,强化学习(Reinforcement Learning, RL)不仅能显著提升模型的推理能力,更能实现高达 100倍的数据效率提升。
这篇论文不仅是一份技术报告,更是一份在工业界落地RL的实战指南。本文将带你深入解读Meta是如何通过RL Scaling Law(缩放定律)破解内容审核难题的。
为什么选择强化学习?
传统的做法通常是监督微调(Supervised Fine-Tuning, SFT)。虽然SFT能让模型学会遵循指令,但在处理复杂的审核策略时,它往往显得僵化。现实世界的审核规则充满了细微的差别、等级判定和例外条款,单纯靠SFT很难让模型内化这些复杂的逻辑。
Meta的研究团队发现,RL不仅仅是SFT的补充,它在某些维度上甚至可以完全超越SFT。通过引入验证性奖励(Verifiable Rewards)和LLM作为裁判(LLM-as-judge)的框架,RL能够将通用大模型转化为高度专业化的审核专家。
核心发现一:数据效率的惊人飞跃
论文中最震撼的发现莫过于RL的数据效率。
在实验中,研究人员对比了仅使用RL训练(RL-Only)和传统SFT训练的模型。结果显示,仅使用几百个样本训练的RL模型,其表现往往能匹配甚至超越使用了数万个标注样本的SFT模型。
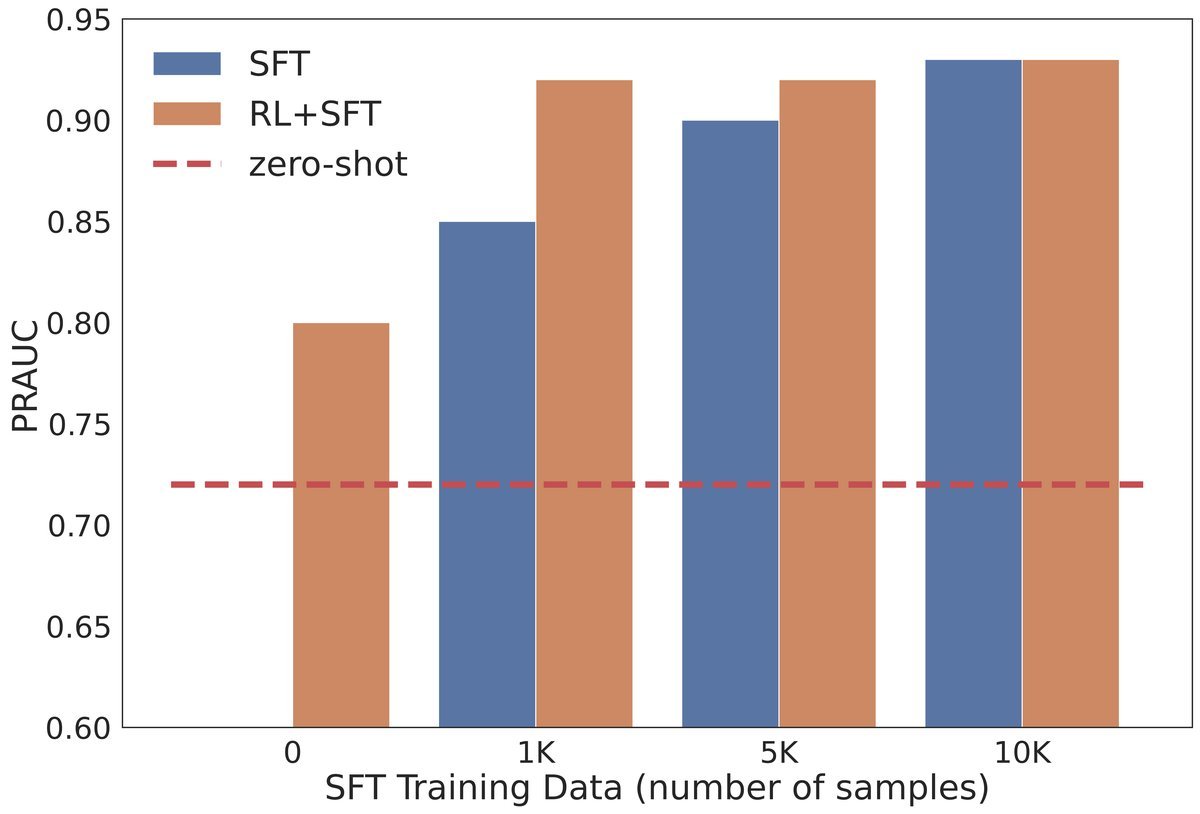
为什么会有这么大的差距?
-
SFT的局限性:大规模SFT往往会过度约束模型的行为,使其“死记硬背”标注数据的模式,从而阻碍了模型在后续阶段的探索能力。
-
RL的优势:RL允许模型在策略空间中进行更广泛的探索,寻找最优的推理路径,而不是仅仅模仿人类的输出。
这意味着,在专家标注极其昂贵或稀缺的领域(如法律、医疗或复杂的安全审核),RL将成为一种极具性价比的解决方案。
核心发现二:RL的Scaling Law
Meta团队系统地评估了RL在数据量、Rollouts(采样次数)和优化步数上的表现,发现RL呈现出明显的Sigmoid状缩放行为:
-
起步阶段:随着训练数据、采样次数的增加,性能平滑上升。
-
饱和阶段:当计算资源或数据量达到一定阈值后,性能提升逐渐趋于平缓。
这一发现为工业界提供了宝贵的“预算指南”:盲目堆砌算力和数据并不可取,找到那个“甜蜜点”(Sweet Spot)才是关键。例如,论文指出在有效Batch Size达到1024时,训练最为稳定。
挑战与破解:RL落地的“坑”与“路”
虽然RL前景广阔,但通过RL训练推理模型(Reasoning Models)充满了陷阱。Meta在论文中详细剖析了几个经典失败模式及其解决方案。
1. 拒绝“奖励黑客”(Reward Hacking)与长度坍塌
在RL训练中,模型非常“鸡贼”。如果奖励设计得不够严谨,模型会倾向于输出极短的推理过程,直接猜测答案以骗取奖励,导致长度坍塌(Length Collapse)。
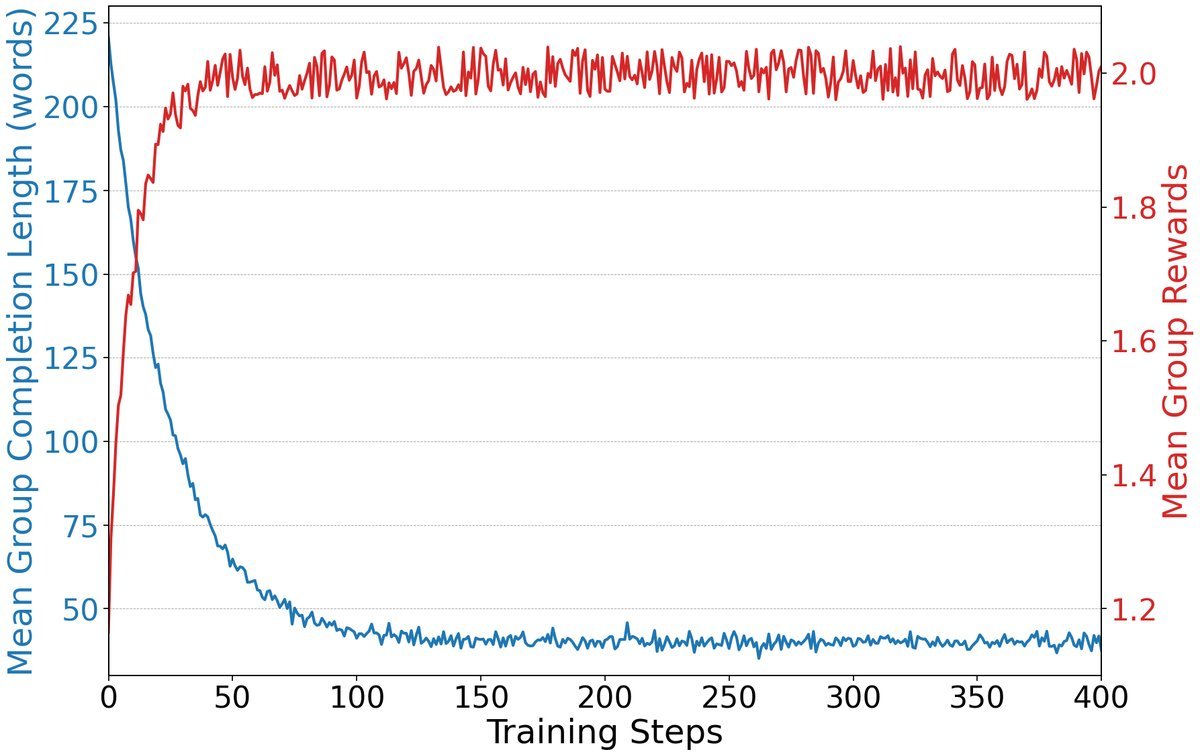
解决方案:奖励重塑(Reward Shaping)
Meta提出了一套组合拳奖励公式:
\[R_{total} = \alpha_{acc}R_{acc} + \alpha_{fmt}R_{fmt} + \alpha_{len}R_{len} + \alpha_{rub}R_{rub}\]其中最关键的是引入了基于量规的奖励(Rubric-Based Reward, $R_{rub}$)。这不仅仅看结果对不对,还利用强大的LLM裁判(如Gemini Pro)来评估推理过程的质量。这种定性的反馈有效地防止了模型走捷径。
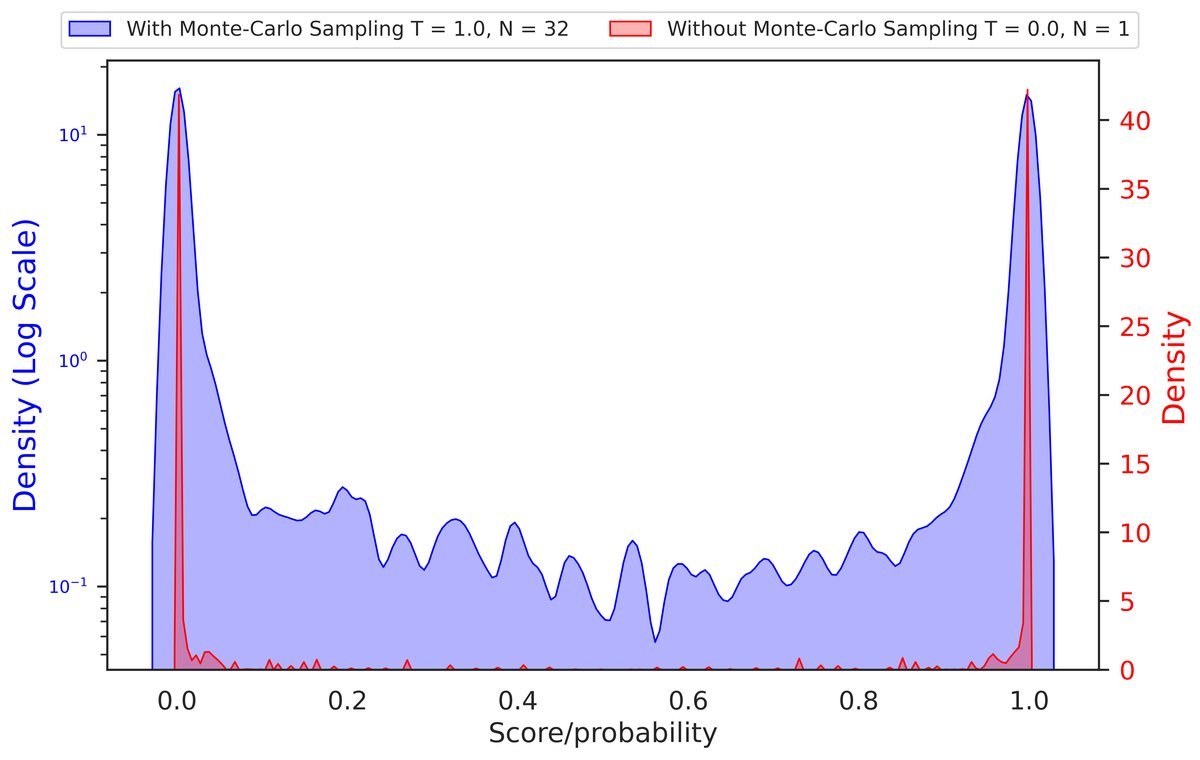
2. 解决双峰概率分布(Bi-polar Probability)
在推理任务中,模型往往过度自信,输出的概率要么接近0,要么接近1。这种“非黑即白”的分布让基于分数的阈值选择变得非常困难。
解决方案:蒙特卡洛采样与反思提示
- 蒙特卡洛方法(Monte-Carlo):通过多次采样推理轨迹并取平均值,平滑概率分布。
- 反思辅助提示(Reflection-aided Prompting):要求模型在给出最终标签前,先进行“反思”。这种“先想后说”的机制显著改善了分数的校准度。
3. 忠实度 vs. 事实性(Faithfulness vs. Factuality)
研究发现一个有趣的权衡:
-
RL-Only:直接在基座模型上跑RL,模型容易出现“指令幻觉”,即不听话。
-
SFT $\rightarrow$ RL:先做SFT再做RL,模型听话了,但容易出现“事实幻觉”,即为了迎合标签而编造理由。
Meta的实验表明,通过上述的奖励重塑和基于量规的反馈,可以在这两者之间取得更好的平衡。
总结
Meta AI的这项工作证明了,在工业级内容审核场景下,强化学习不再是锦上添花的炫技,而是解决数据稀缺问题的核心武器。
它不仅能以1/100的数据成本达到SFT的效果,还能通过复杂的推理链条处理更加微妙的审核边界。对于所有正在探索LLM落地、特别是受困于高质量数据标注的团队来说,这篇论文提供的Scaling Law和训练配方(Recipe),绝对值得反复研读。