LLM长文本“瘦身”8倍:新方法让模型按“句”读取,性能几乎无损
当Kimi、GPT-4等模型的上下文窗口卷向数百万Token时,一个现实问题摆在了所有AI从业者面前:巨大的计算和内存开销。处理长文本的成本,尤其是Transformer架构中$O(n^2)$复杂度的自注意力机制,已成为制约大模型应用普及的瓶颈。有没有办法在不牺牲太多性能的前提下,为LLM的上下文处理过程“瘦身”呢?
论文标题:Sentence-Anchored Gist Compression for Long-Context LLMs ArXiv URL:http://arxiv.org/abs/2511.08128v1
来自FusionBrainLab等机构的研究者提出了一种名为句子锚定主旨压缩(Sentence-Anchored Gist Compression)的新方法。它通过一种精巧的设计,让LLM学会边读边“提炼摘要”,实现了高达8倍的KV缓存压缩,且在多项长短文本基准测试中性能几乎没有下降。
什么是Gist Token压缩?
要理解这项技术,我们先得了解主旨Token(Gist Token或Beacon Token)的概念。
想象一下你在读一本厚厚的书。你不太可能记住每一页的每一个字。更高效的做法是,每读完一章,就在旁边写下一两句核心摘要。当阅读后续章节需要回顾前面内容时,你只需看这些摘要,而无需重读整个章节。
Gist Token扮演的就是“章节摘要”的角色。它是一种特殊的可学习Token,用来概括和压缩一段文本的核心信息。通过在文本中插入这些Gist Token,模型可以将长序列的信息浓缩到少数几个向量中,从而大幅减少后续计算的负担。这是一个简洁而强大的思路,但关键在于:摘要应该在什么时候写?写多少才合适?
核心创新:以句子为锚点的压缩艺术
以往的方法通常采用固定的策略,比如每隔N个Token就插入一个Gist Token。这种“一刀切”的方式虽然简单,但忽略了文本自身的语义结构。
本文最大的亮点在于,它提出了一种更符合直觉的、数据依赖(data-dependent)的策略:在每个句子的末尾插入Gist Token。
为什么是句子?因为句子是语言中天然的、完整的语义单元。在一个句子结束时进行信息总结,显然比在任意位置打断要合理得多。这种方法让压缩的边界与文本的语义边界对齐,有助于模型生成更有意义、更连贯的“摘要”。
具体操作上,模型会在文本预处理阶段自动识别句号、问号、感叹号等标点,并在其后插入$N_g$个(例如1个、2个或4个)可学习的Gist Token。
揭秘“句子注意力”机制
为了让Gist Token真正发挥作用,研究者设计了一种巧妙的注意力掩码(Attention Mask),我们称之为“句子注意力”。它重新定义了模型中不同Token之间的“可见性”规则。
继续用读书的例子来解释:
- 普通词语(Regular Tokens)的视野:当模型处理某个句子中的一个词时,它只能“看到”这个句子内的其他词,以及之前所有句子的Gist Token(摘要)。它无法直接回看前面句子的原文。这极大地减少了计算量。
- Gist Token(摘要)的视野:当模型生成某个句子的Gist Token时,它被赋予了更高的权限。它既可以“看到”当前句子中的所有词语,也能“看到”之前所有句子的Gist Token(摘要)。这保证了Gist Token能够充分概括当前句子的信息,并继承历史摘要。
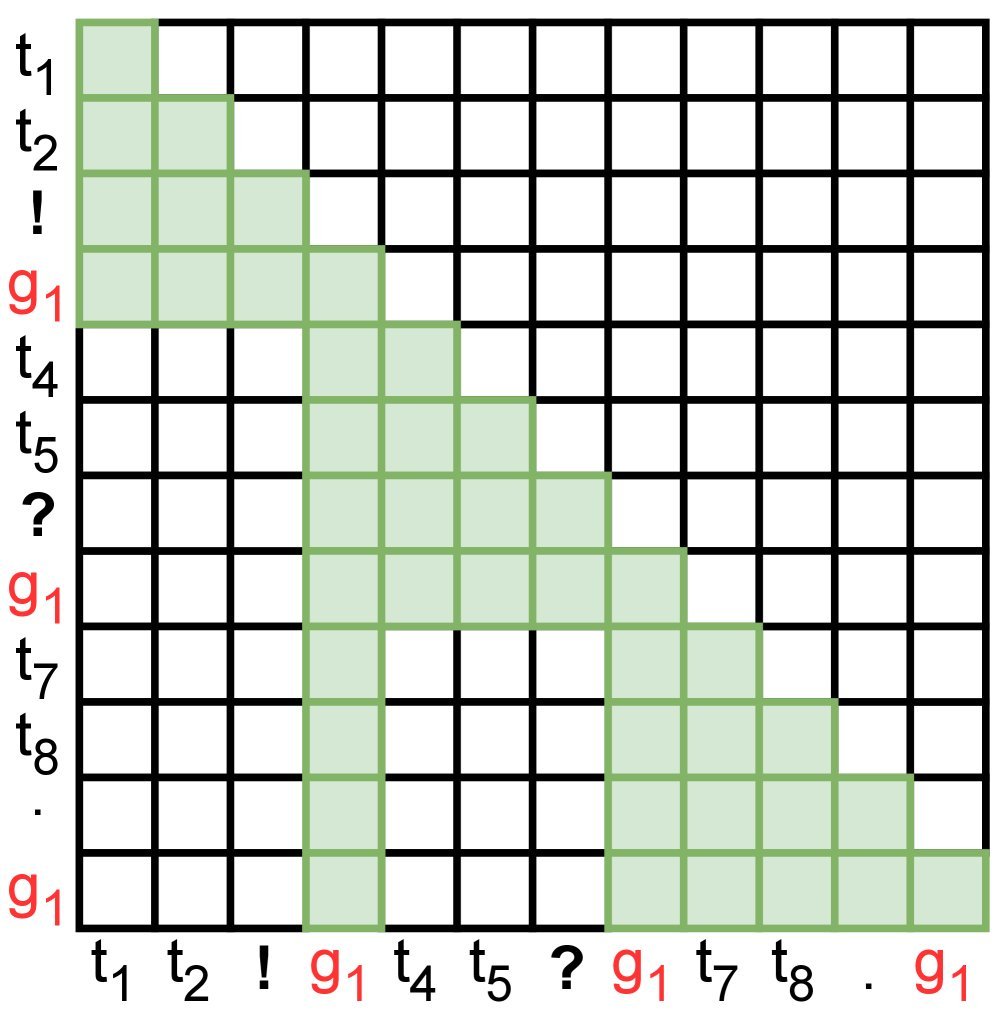 图1:(a) 标准因果注意力 vs (b) 句子注意力。在句子注意力中,普通Token($t_i$)只关注句内信息和历史摘要($g_1$),而摘要($g_1$)则聚合当前整个句子的信息。
图1:(a) 标准因果注意力 vs (b) 句子注意力。在句子注意力中,普通Token($t_i$)只关注句内信息和历史摘要($g_1$),而摘要($g_1$)则聚合当前整个句子的信息。
这种设计通过一个修改后的注意力掩码实现,无需改变Transformer的核心架构,训练和推理都能高效并行。
三步走的训练策略
为了让模型稳定地学会这种压缩技巧,研究者采用了精心设计的三阶段训练法:
- Gist Token预热:冻结大模型主体参数,只训练新加入的Gist Token。让这些“摘要笔”先学会如何捕捉信息。
- 全模型微调:放开所有参数,对整个模型进行微调。让模型学会如何有效地利用这些Gist Token来进行推理。
- 大批量冷却:最后阶段使用超大批量(Batch Size)进行训练,帮助模型收敛得更稳定。
整个训练过程仅使用标准的语言建模目标函数,无需像其他方法那样引入额外的重构损失函数,方法非常简洁。
实验效果:8倍压缩,性能不减
该研究基于Llama3.2-3B模型进行了实验。结果令人印象深刻:
在MMLU等短文本基准上,压缩后的模型与原始模型性能持平,证明这种压缩机制没有损害模型的基础语言和知识能力。
在HELMET等长文本基准上,本文提出的模型(Sentence Llama)表现尤为出色。尽管模型参数量(3B)只有其他基线模型(如Activation Beacon,7B)的一半,但性能却不相上下,甚至在某些任务上更优。
表2:在长文本基准HELMET (tiny)上的对比。Sentence Llama-3B ($N_g=4$)在性能上与7B的模型相当。
更关键的是压缩率。当每句使用4个Gist Token ($N_g=4$)时,该方法在长文本任务上的平均KV缓存压缩率达到了6倍左右。相比之下,与之类似的Activation Beacon模型压缩率仅为2倍。这意味着用更小的模型、更少的显存,就能处理同样复杂的长文本任务。
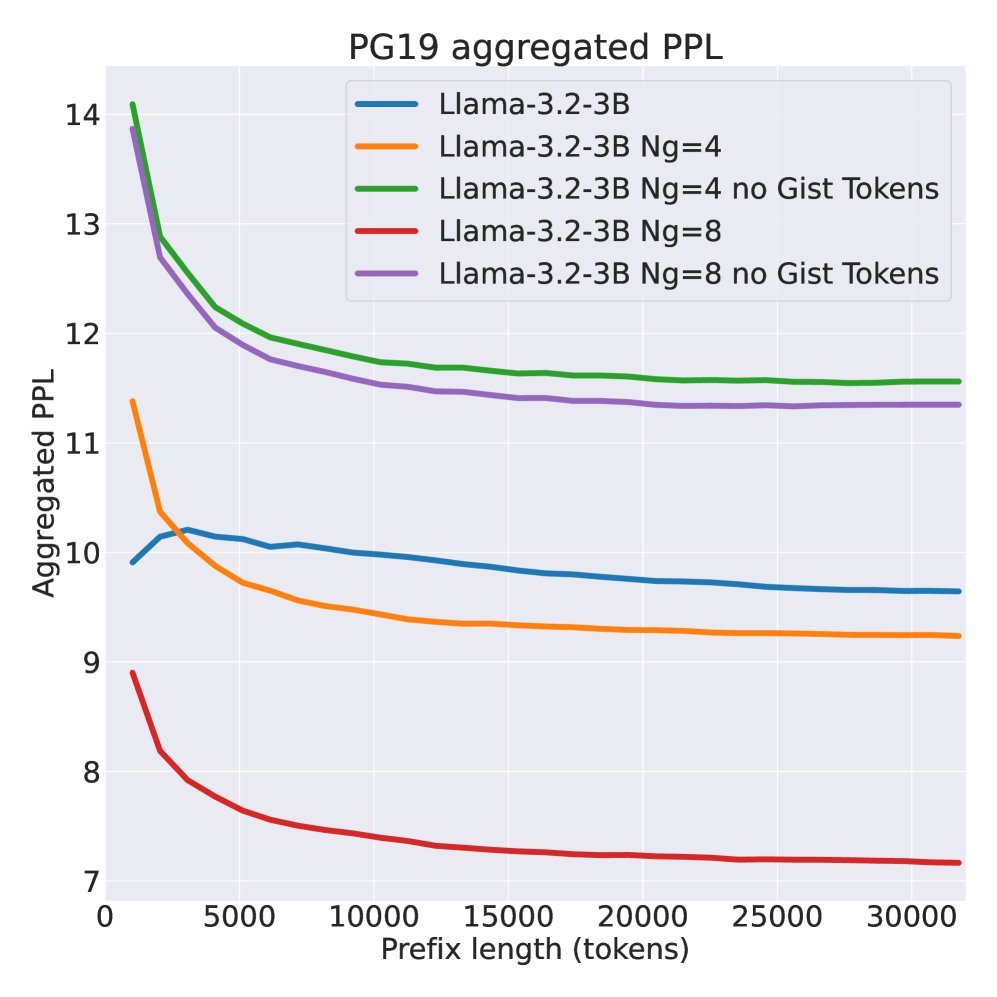 图2:在PG19数据集上的困惑度。压缩模型(蓝色/橙色实线)的整体困惑度甚至低于基线,显示了其强大的建模能力。
图2:在PG19数据集上的困惑度。压缩模型(蓝色/橙色实线)的整体困惑度甚至低于基线,显示了其强大的建模能力。
结论与局限
句子锚定主旨压缩为解决LLM长文本处理的效率问题提供了一个优雅且高效的方案。它通过将压缩点与句子的语义边界对齐,并设计了简洁的注意力机制和训练流程,在实现高压缩率的同时保持了强大的性能。
当然,该研究也存在一些局限性,例如目前所有实验都基于3B模型,其在更大模型上的可扩展性有待验证。此外,由于方法依赖标点符号,其性能对文本格式的规范性比较敏感。
尽管如此,这项工作无疑为开发更经济、更易于部署的长文本大模型指明了一条极具潜力的道路。它告诉我们,最高效的压缩,或许就隐藏在语言自身最基本的结构之中。