80%的预测只需96个Token!DeepMind揭示大模型“短视”的秘密

当整个AI界都在为百万、千万级长上下文窗口欢呼时,你是否想过一个反直觉的问题:在大多数情况下,大语言模型真的需要那么长的上下文吗?
ArXiv URL:http://arxiv.org/abs/2512.08082v1
最近,Google DeepMind的一项研究给出了一个惊人的答案。他们发现,对于高达7000 Token的序列,75-80%的预测任务,模型其实只需要最后96个Token就足够了!
这项研究不仅系统性地验证了“短上下文主导”这一现象,还开发出了一套实用的检测和优化方法,能够智能识别并增强模型在真正需要长距离依赖时的表现。
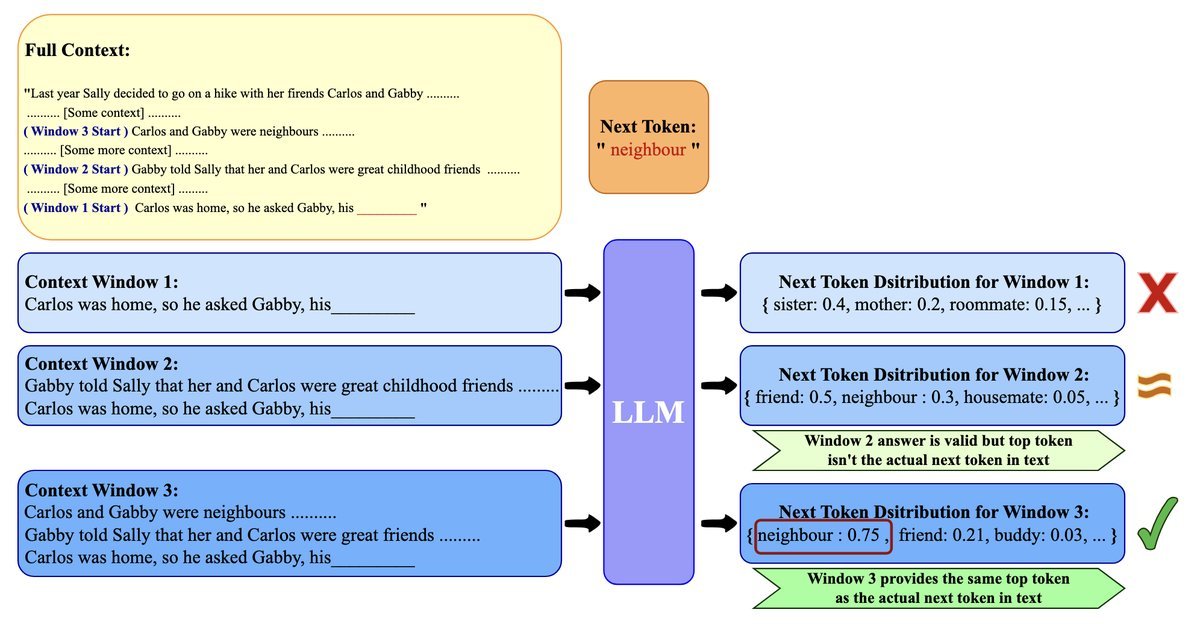
短上下文主导:一个反直觉的假设
我们常常认为,上下文越长,模型能理解的信息就越多,预测也就越准。但该研究提出了一个核心假设:短上下文主导(Short-context dominance)。
即对于绝大多数自然语言序列,预测下一个词元(Token)所需的信息,其实都包含在一个很短的、紧邻的局部上下文中。
为了验证这个假设,研究者们引入了一个关键指标:最小上下文长度(Minimal Context Length, MCL)。
定义1:最小上下文长度 (MCL) 对于一个给定的序列和它的真实下一个词元$t$,MCL指的是能让模型自信且正确地预测出$t$所需的最短末尾上下文长度$l$。 \(\mathsf{MCL}\left(\mathbf{s}|t\right):=\arg\min\nolimits\_{l\in|\mathbf{s}|}\big\{l\;\;|\;\;\mathsf{Top}\_{1}(\mathbf{s}\_{[-l:]})=t,\;\;\mathsf{\Delta Conf}({\mathbf{s}\_{[-l:]}})\geq\delta\big\}\) 简单来说,就是找到一个最短的“记忆窗口”,只要有这个窗口内的信息,模型就能做出和拥有全部信息时一样准确的预测。
实验结果令人震惊。研究团队在新闻、故事、政府报告等多种数据集上进行了测试,发现MCL的分布严重偏向极短的长度。
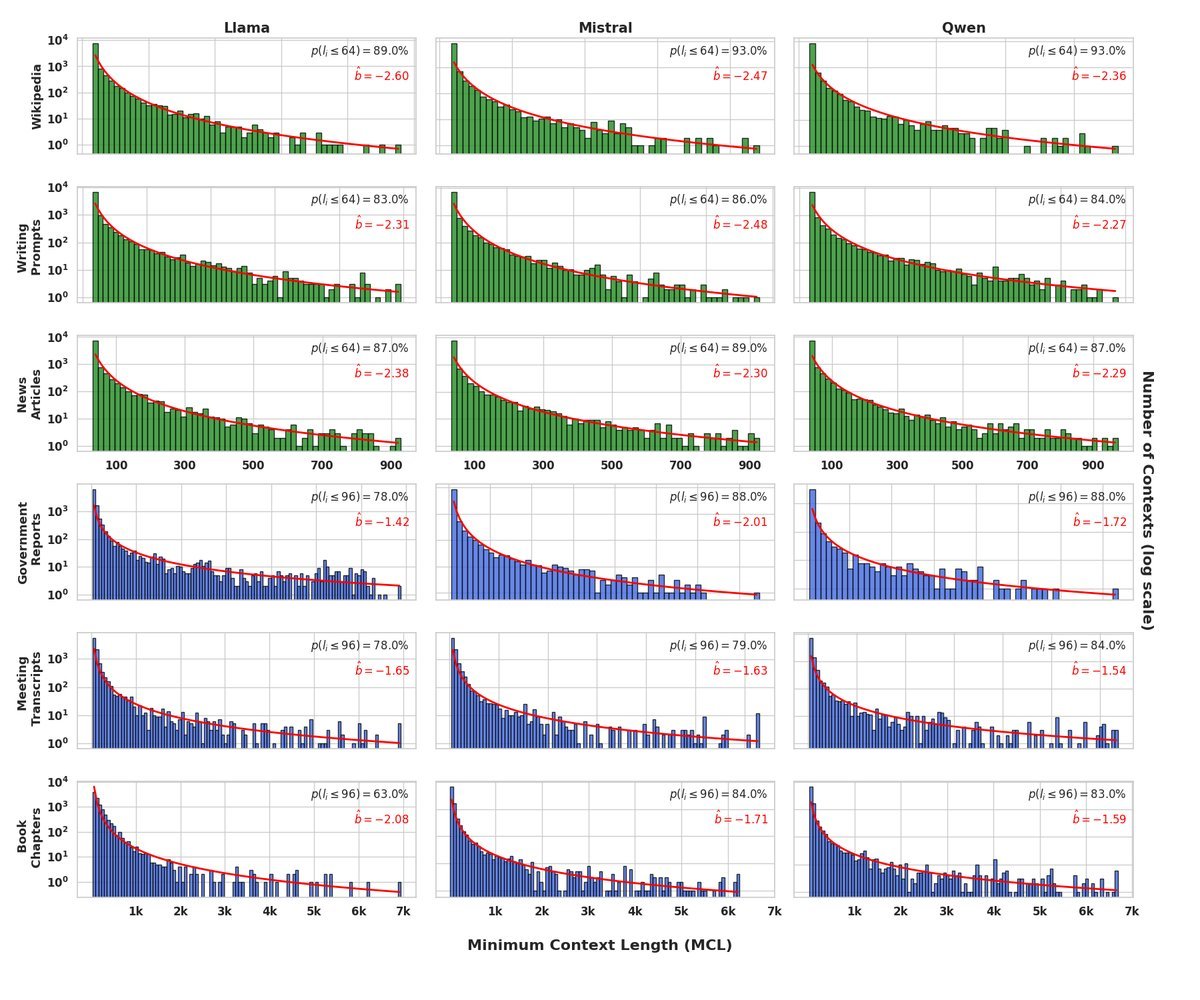
如上图所示(注意Y轴是对数尺度),无论是长文本还是短文本,绝大多数(约80-90%)序列的MCL都不超过96个Token。这有力地证明了“短上下文主导”假设的普遍性。
这一发现也解释了为什么基于困惑度(Perplexity)的评估指标有时会“失灵”——因为它被大量简单的、仅需短上下文的预测任务所主导,无法真正衡量模型处理长距离依赖的能力。
从“正确答案”到“概率分布”:更实用的DaMCL
MCL虽然揭示了问题的本质,但它有一个致命缺陷:计算它需要知道“正确答案”(即真实的下一个词元)。这在实际的生成任务中是无法实现的。
为了解决这个问题,研究者们提出了一种更灵活、更实用的变体:分布感知最小上下文长度(Distribution-aware MCL, DaMCL)。
定义2:分布感知最小上下文长度 (DaMCL) DaMCL不再关注是否能预测出某个特定的正确词元,而是比较“短上下文”和“全上下文”下,模型预测的下一个词元概率分布是否足够相似。 \(\mathsf{DaMCL}\_{\phi}^{\mathcal{M}}\left(\mathbf{s},\epsilon\right):=\arg\min\_{l\in|\mathbf{s}|}\left\{l\;\;|\;\;\mathcal{M}(\operatorname{\mathbf{p}}\_{\phi}(\mathbf{s}\_{[-l:]})\,;\,\operatorname{\mathbf{p}}\_{\phi}(\mathbf{s}))\leq\epsilon\right\}\) 这里,$\mathcal{M}$是一个衡量两个概率分布差异的度量,研究中使用了Jensen-Shannon距离(JSD)。如果短上下文产生的概率分布与全上下文的足够接近(JSD小于阈值$\epsilon$),我们就认为这个短上下文“够用了”。
DaMCL的巧妙之处在于,它完全摆脱了对“标准答案”的依赖,只需比较模型自身的输出分布,因此可以在推理时动态使用。
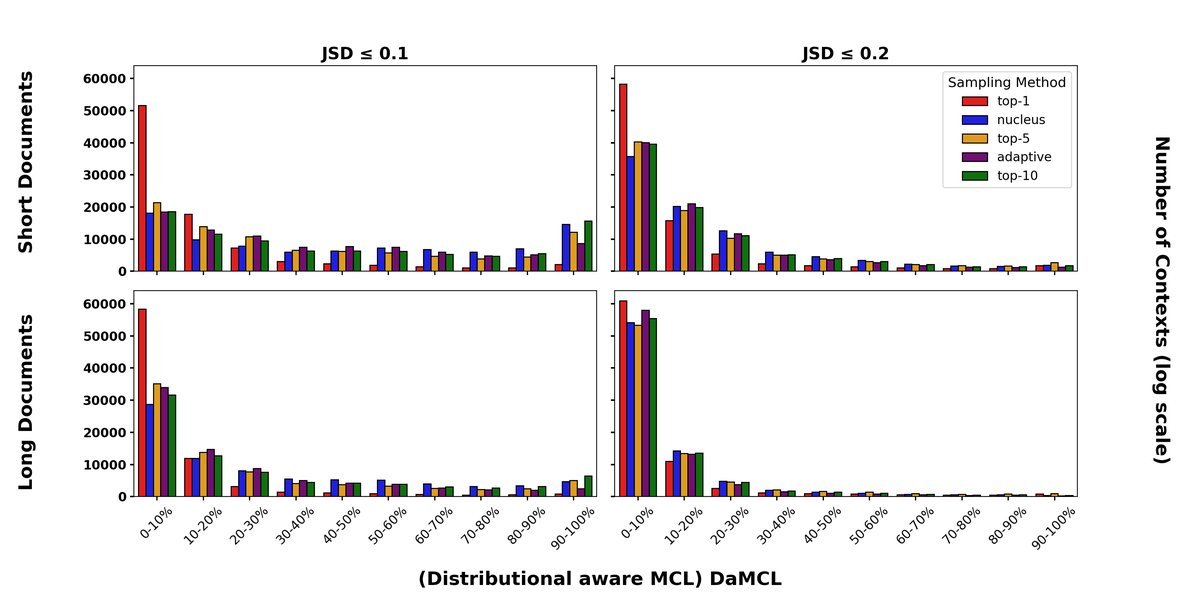
实验再次证实,即使从分布相似性的角度看,短上下文主导的趋势依然存在,尽管相比MCL的极端偏斜有所缓和。这说明,DaMCL是一个有效且可靠的代理指标。
长上下文序列检测器:LSDS
有了DaMCL这个强大的工具,研究者顺势打造了一个“长上下文序列检测器”。
他们定义了一个新指标:长短分布偏移(Long-Short Distribution Shift, LSDS)。它非常简单,就是计算一个固定短上下文(如32个Token)与完整上下文所产生的下一个词元概率分布之间的JSD值。
\[\mathsf{LSDS}\left(\mathbf{s}\right)=\operatorname{JSD}(\operatorname{\mathbf{p}}\_{\phi}(\mathbf{s}\_{[-32:]}),\operatorname{\mathbf{p}}\_{\phi}(\mathbf{s}))\]这个检测器的逻辑是:
-
如果LSDS值很小,说明32个Token提供的信息和全部信息效果差不多,这是一个“短上下文序列”。
-
如果LSDS值很大,说明短上下文信息不足,模型需要回顾更早的内容,这是一个“长上下文序列”。
更棒的是,这个检测器的计算开销极小。对于一个6000 Token的序列,额外的计算耗时仅增加了约6-8%,几乎可以忽略不计。
对症下药:用TaBoo算法纠正短上下文偏见
既然模型在大部分时间里都在处理“简单”的短上下文任务,这可能会导致一种偏见:模型倾向于生成那些基于局部信息就能预测的、更“平庸”的词元,而忽略了那些真正依赖长距离信息的关键内容。
我们能否在检测到“长上下文序列”时,主动“帮助”模型关注那些与长距离信息更相关的词元呢?
答案是肯定的。研究团队为此设计了一种名为TaBoo(Targeted Boosting)的解码算法。
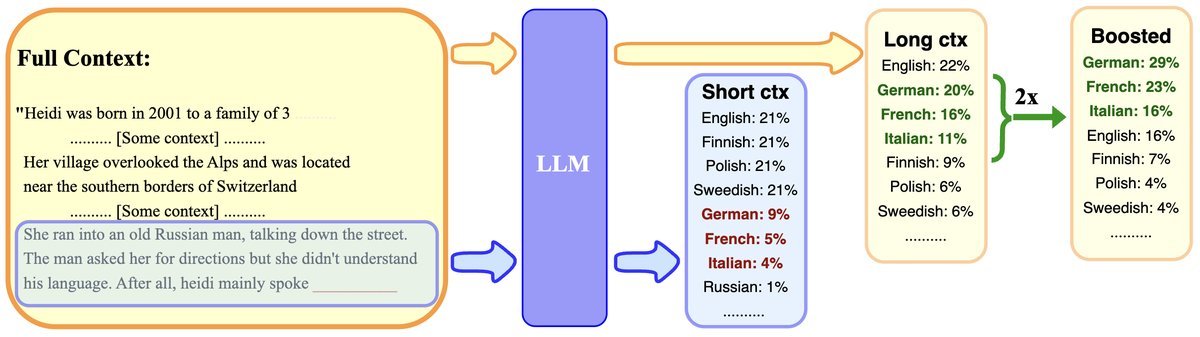
TaBoo算法的核心步骤如下:
-
识别长上下文相关词元:首先,需要找到那些因获得完整上下文而受益最多的词元。研究者定义了长短概率漂移(Long-Short Probability Shift, LSPS),即一个词元在完整上下文和短上下文下的概率差值。
\[\mathsf{LSPS}\left(t \mid \mathbf{s}\right)=\left[\operatorname{\mathbf{p}}\_{\phi}(\mathbf{s})\right]\_{t}-\left[\operatorname{\mathbf{p}}\_{\phi}(\mathbf{s}\_{[-32:]})\right]\_{t}\]LSPS值越高的词元,就越依赖于长距离信息。
-
实施定向增强:
-
检测:首先使用LSDS检测器判断当前序列是否需要长上下文。
-
增强:如果需要,TaBoo会识别出LSPS值高的“长上下文相关词元”集合。
-
调整:在最终生成时,算法会提升(Boost)这些被识别出的词元的概率,让它们更有可能被选中。
-
这个过程就像给模型戴上了一副“智能眼镜”:平时处理简单任务时关闭,一旦检测到复杂、需要长远眼光的任务,就立刻开启,高亮那些隐藏在远方上下文中的关键线索。
实验结果
在多个需要长上下文理解的问答数据集上,TaBoo算法的表现非常出色。
| 模型 | 数据集 | Vanilla Nucleus (F1) | CAD (F1) | TaBoo (F1) |
|---|---|---|---|---|
| LLaMA-3-8B | NarrativeQA | 20.3 | 21.9 | 21.8 |
| LLaMA-3-8B | QASPER | 29.5 | 30.5 | 31.3 |
| Qwen2-7B | NarrativeQA | 22.8 | 23.4 | 23.9 |
| Qwen2-7B | QASPER | 34.6 | 35.1 | 35.7 |
表格内容根据论文Table 1简化,展示了F1分数的对比。
如上表所示,TaBoo在绝大多数模型和数据集组合上,其F1分数都超过了标准的Nucleus采样和之前的增强方法CAD。这证明了通过动态检测和定向增强来纠正短上下文偏见是一条非常有效的路径。
总结与展望
这项来自Google DeepMind的研究,为我们揭示了大型语言模型在处理上下文时的一个基本特性——“短上下文主导”。
它告诉我们,一味追求无限长的上下文窗口可能并非最高效的路径。更智能的方法或许是:
-
精确识别:动态判断模型何时真正需要长上下文。
-
高效利用:在需要时,有针对性地引导模型关注和利用长距离信息。
该研究提出的LSDS检测器和TaBoo增强算法,为实现“上下文感知”的智能生成迈出了坚实的一步。这不仅为优化当前模型的推理效率提供了新思路,也为未来设计更高效的训练方法和更精准的评测基准指明了方向。
也许,让模型学会“抬头看路”和“低头看书”的智能切换,比给它一本无限厚度的书更为重要。