Sigmoid Head for Quality Estimation under Language Ambiguity
告别Softmax“分票”困境:Sigmoid Head无需人工标注,精准量化大模型置信度

大模型(LLM)经常会让我们面临一个棘手的悖论:有时候它一本正经地胡说八道(幻觉),有时候它明明说对了,给出的置信度(Probability)却很低。
ArXiv URL:http://arxiv.org/abs/2601.00680v1
为什么模型会对自己正确的回答“缺乏自信”?
这篇来自卡尔斯鲁厄理工学院(KIT)的研究揭示了背后的元凶:Softmax函数的“零和博弈”机制。当面对自然语言中常见的“一义多词”现象(歧义性)时,Softmax强行将概率分散给了多个正确的同义词,导致每个正确词的得分都被稀释了。
为了解决这个问题,该研究提出了一种名为 Sigmoid Head 的轻量级方案。它不需要任何人工标注的质量数据,仅通过改变输出层的激活函数和一种巧妙的负采样策略,就能显著提升模型对自己输出质量的评估能力(Quality Estimation, QE),在跨领域任务中甚至击败了受监督的强基线模型 COMET-Kiwi。
核心痛点:Softmax 的“分票”陷阱
在传统的语言模型训练中,我们通常假设每个位置只有一个“标准答案”(One-hot encoding)。但自然语言充满了歧义(Ambiguity),同一个意思可以用“Start”,也可以用“Begin”。
然而,现有的模型架构存在两个导致“歧义引致的自信不足”(Ambiguity-Induced Underconfidence)的结构性缺陷:
-
Softmax 的归一化约束:Softmax 强制所有词的概率之和为 1。如果有两个同样完美的候选词(例如 $P(\text{Start})$ 和 $P(\text{Begin})$),它们必须瓜分概率,导致两者的得分都不高(比如各 0.4)。这给用户传达了一个错误信号:模型对哪个都不太确定。
-
训练数据的单一性:训练数据通常只提供一个参考答案(Reference),模型被训练为将概率集中在这一个词上,而抑制其他所有词(哪怕它们也是对的)。
破局之道:Sigmoid Head
为了解决上述问题,论文提出在预训练模型之上,额外训练一个用于质量评估(QE)的模块——Sigmoid Head。
1. 架构:从竞争到独立
研究者保持原有的 Transformer 参数不变,只是增加了一个额外的非嵌入层(Unembedding Head)。最关键的改动是:将输出激活函数从 Softmax 换成了 Sigmoid。
\[P_{\theta^{\prime}}(y_{i}\mid\mathbf{x},\mathbf{y}_{<i})=\sigma(\mathbf{z}^{\text{qe}}_{i})\]Sigmoid 允许每个 token 独立打分。这意味着,在理想情况下,模型可以同时给“Start”和“Begin”打出接近 1 的高分,而不再需要它们互相“抢夺”概率。
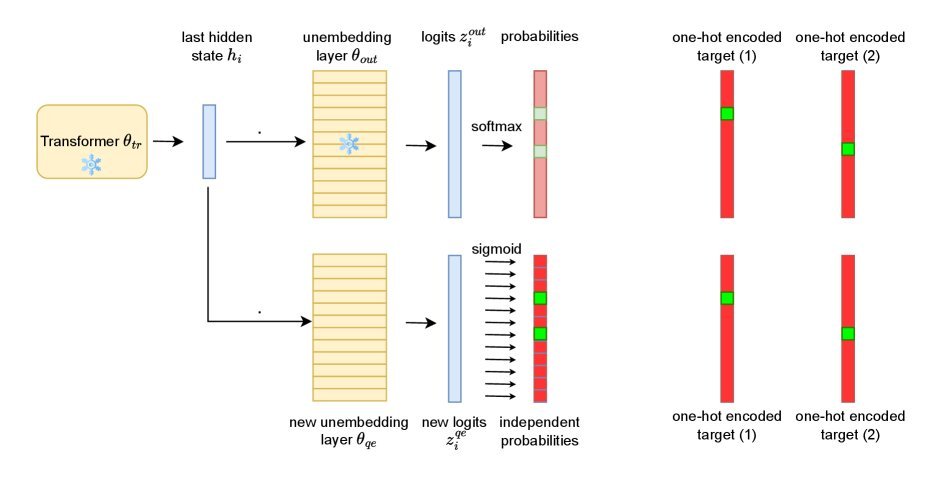
图 1:在预训练模型上扩展的 Sigmoid Head 架构。原有的 Softmax Head 保持不变,新增的 Sigmoid Head 负责输出独立的质量分数。
2. 训练策略:聪明的负采样
既然 Sigmoid Head 是为了区分“好词”和“坏词”,那么如何定义“坏词”(负样本)就成了关键。如果随机采样负样本,或者直接把除了标准答案之外的词都当成负样本,那么模型又会重蹈覆辙,错误地惩罚那些正确的同义词。
为了解决这个问题,研究者利用了预训练模型本身包含的知识。他们发现,在原模型 Softmax 分布中概率较高的那些词(Dominant Tokens),往往就是潜在的正确同义词。
因此,该研究提出了一种基于歧义感知的负采样策略:
在训练 Sigmoid Head 时,负样本 $\mathcal{N}_{i}$ 从词表中采样,但显式排除掉标准答案 $y_{i}^{\ast}$ 和原模型认为的高概率“优势词”集合 $\mathcal{D}_{i}$。
\[\mathcal{N}_{i}=\mathcal{V}\setminus\left(\{y_{i}^{\ast}\}\cup\mathcal{D}_{i}\right)\]这样,模型就被迫去区分“真正的错误”和“正确答案”,而不会误伤那些“虽然不是标准答案,但也很有道理”的词。
实验结果:无需标注,胜过监督学习
研究者在机器翻译(MT)、复述生成和问答任务上进行了广泛测试。
1. 告别“盲目自信”与“过度谦虚”
通过对比不同设置下的预测分数与真实质量(下图),我们可以清晰地看到:
-
标准 Softmax(图 a):严重低估质量,高分区域几乎是空的。
-
随机负采样(图 b):盲目自信,几乎所有词都给满分。
-
排除优势词的 Sigmoid Head(图 f):预测分数与真实质量呈现出最佳的线性关系。
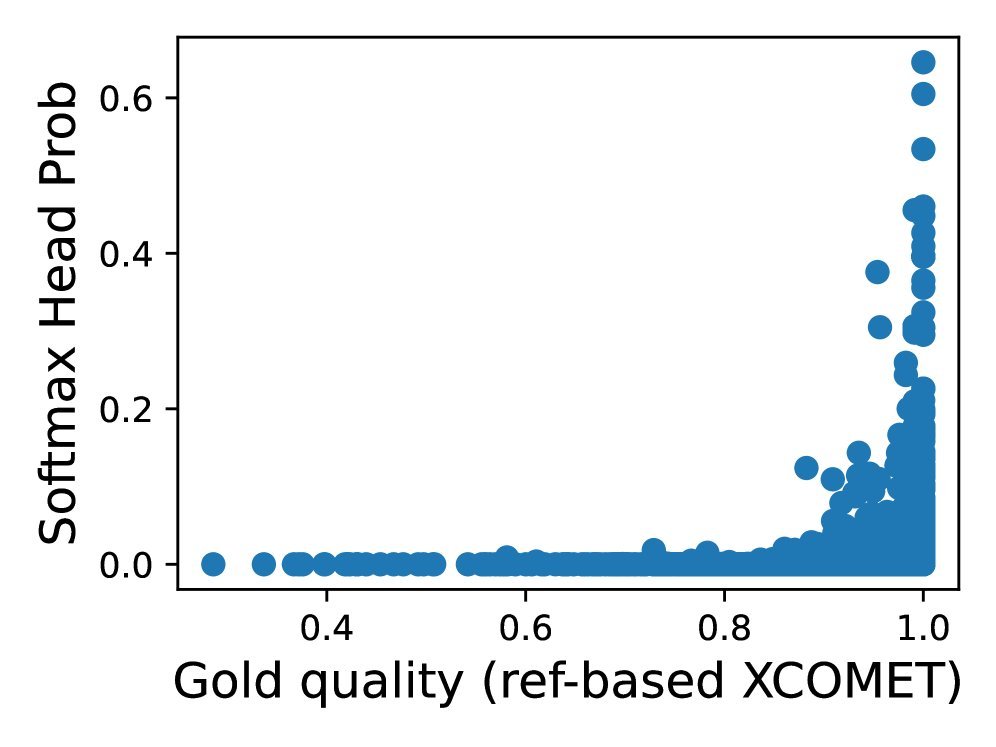
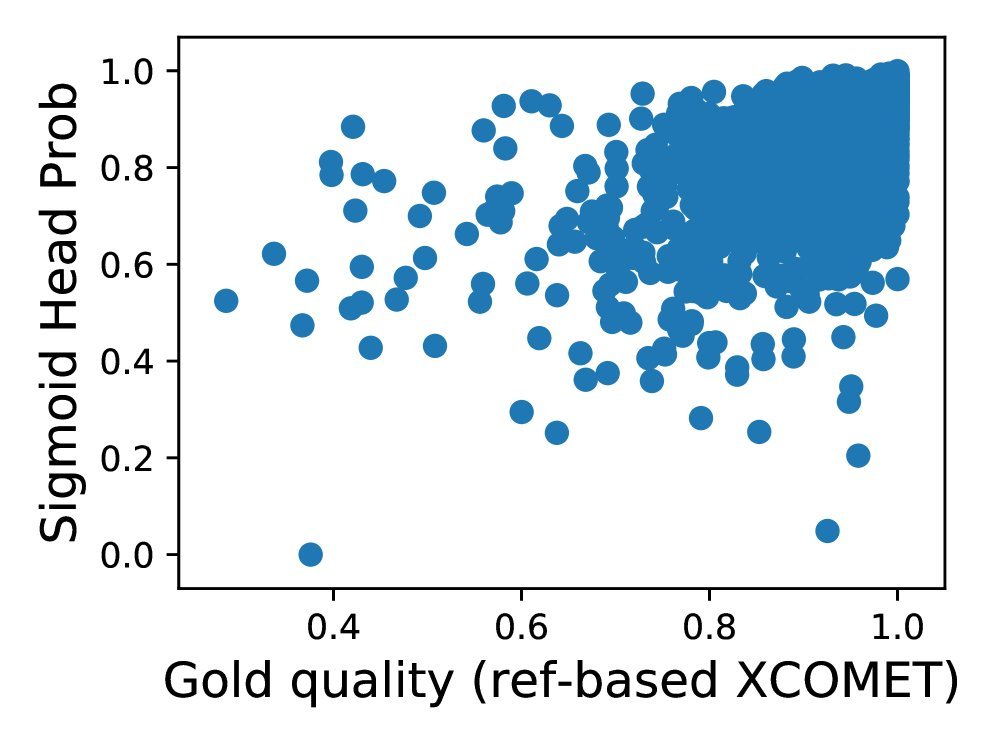
图 2:真实质量分数 vs. 预测质量分数。(a) 标准 Softmax 明显低估了高质量输出;(f) 采用本文策略的 Sigmoid Head 展现了最佳的一致性。
2. 跨领域鲁棒性
在机器翻译任务中,Sigmoid Head 产生的概率信号显著优于原始 Softmax。
更令人印象深刻的是,在生物医学领域的翻译测试(BioMQM)中,Sigmoid Head 击败了受监督的 COMET-Kiwi 模型。
-
COMET-Kiwi:依赖大量人工标注数据训练,但在面对未见过的领域(Out-of-domain)时表现下降。
-
Sigmoid Head:完全无监督(不需要人工质量标注),仅利用原有的文本数据训练,因此展现出了更强的泛化能力。
总结与启示
这项研究告诉我们,大模型“由于歧义而导致的自信不足”是一个架构层面的问题,简单的 Softmax 并不适合作为质量评估的工具。
Sigmoid Head 提供了一个优雅且高效的解法:
-
简单:只是一个额外的线性层 + Sigmoid 激活。
-
高效:训练和推理都非常轻量级。
-
独立:无需昂贵的人工标注数据(Human-labeled data)。
对于正在构建 RAG 系统或需要对模型输出进行可靠性校验的开发者来说,用 Sigmoid Head 替代传统的 Log-probability,或许是提升系统鲁棒性的一条捷径。