SimpleMem: Efficient Lifelong Memory for LLM Agents
SimpleMem:让Agent记忆成本暴降30倍!F1提升26.4%的“语义无损压缩”新架构

在大模型(LLM)Agent 的长期交互中,开发者往往面临一个两难的“记忆困境”:如果保留全部对话历史,不仅 Token 成本爆炸,还会因为大量无意义的闲聊(Context Inflation)导致模型注意力分散,产生“迷失中间”现象;如果试图通过推理来压缩记忆,反复的调用又会带来极高的延迟和计算开销。
ArXiv URL:http://arxiv.org/abs/2601.02553v1
如何在不丢失关键信息的前提下,让 Agent 拥有高效、廉价且精准的长期记忆?
来自加州大学伯克利分校等机构的研究团队提出了一种全新的解决方案——SimpleMem。这是一种基于语义无损压缩(Semantic Lossless Compression)的高效记忆框架。它不依赖暴力的上下文扩展,而是像人类记忆一样,对信息进行“新陈代谢”。实验表明,SimpleMem 在基准测试中将推理时的 Token 消耗减少了惊人的 30倍,同时将 F1 分数提升了 26.4%,完美平衡了性能与效率。
核心理念:拒绝“流水账”,拥抱“结构化”
现有的记忆系统大多处于两个极端:要么是“被动记录者”,机械地存储所有原始对话;要么是“昂贵的过滤器”,通过复杂的迭代推理来清洗数据。
SimpleMem 选择了第三条路。它受到认知科学中互补学习系统(Complementary Learning Systems, CLS)理论的启发,构建了一个三阶段的流水线,旨在最大化固定上下文窗口内的信息密度。
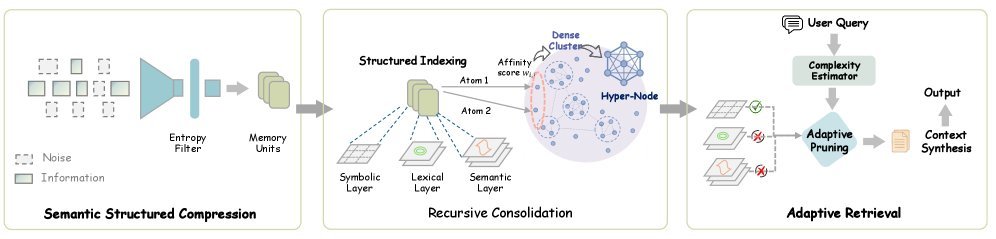
图 1:SimpleMem 架构概览。包含语义结构化压缩、递归记忆整合和自适应查询感知检索三个核心阶段。
第一阶段:语义结构化压缩(给记忆“脱水”)
在对话中,大量的 Token 其实是低熵噪音(如“好的”、“我知道了”)。SimpleMem 的第一步就是主动过滤和重构信息。
该阶段引入了语义结构化压缩(Semantic Structured Compression)。它不仅仅是简单的摘要,而是包含了一系列精细的预处理操作:
-
熵感知过滤:系统会计算输入内容的“信息熵”。只有当一段对话包含足够的新信息(高语义效用)时,才会被保留;低价值的冗余内容会被直接丢弃。
-
指代消解与时间归一化:这是 SimpleMem 的一大亮点。原始对话中的“他同意了”会被改写为“Bob 同意了”;“下周五”会被转换为绝对时间戳“2025-10-24”。这确保了每个记忆单元(Memory Unit)在脱离原始语境后,依然是独立、完整且可解释的。
通过这一步,原始的非结构化对话流被转化为紧凑的、独立的事实单元。
第二阶段:递归记忆整合(记忆的“抽象化”)
如果只是把压缩后的事实堆积起来,随着时间推移,检索库依然会变得臃肿。SimpleMem 引入了递归记忆整合(Recursive Memory Consolidation),这是一个异步的后台进程。
系统不会机械地累积相似的经历,而是会将相关的记忆单元递归地整合成更高层级的抽象表示。
例如,系统不会存储十条“用户早上 8 点喝了拿铁”的记录,而是将其合并为一个抽象模式:“用户习惯在早上喝咖啡”。这种机制极大地减少了语义冗余,使得记忆库的拓扑结构始终保持紧凑,检索复杂度不会随着交互时长的增加而线性爆炸。
第三阶段:自适应查询感知检索(按需“取餐”)
在检索环节,传统的 RAG(检索增强生成)通常采用固定的 Top-k 策略,这往往导致要么信息不足,要么 Token 浪费。
SimpleMem 提出了自适应查询感知检索(Adaptive Query-Aware Retrieval)。系统会根据当前查询的复杂度(Query Complexity)动态调整检索范围:
-
简单查询:对于简单的事实询问,系统仅检索少量高层级的抽象记忆或元数据摘要,最小化 Token 使用。
-
复杂查询:对于需要多跳推理的复杂问题,系统会自动扩大检索范围,包含更多相关的细粒度细节。
其检索深度的动态调整公式如下:
\[k\_{dyn}=\lfloor k\_{base}\cdot(1+\delta\cdot C\_{q})\rfloor\]其中 $C_{q}$ 代表查询复杂度。这种机制确保了每一分算力都花在刀刃上。
实验结果:以小博大,效率惊人
研究团队在专门测试长期对话依赖能力的 LoCoMo 基准上进行了评估。结果显示,SimpleMem 展现出了压倒性的优势。
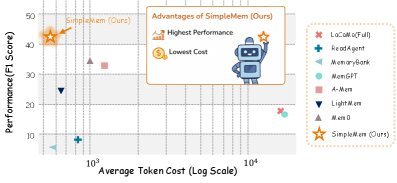
图 2:性能与效率的权衡。SimpleMem 位于理想的左上角区域,以极低的 Token 消耗(约 550 tokens)实现了极高的准确率。
-
性能飙升:相比于 Mem0、LightMem 等强基线,SimpleMem 的平均 F1 分数提升了 26.4%。在 GPT-4.1-mini 模型上,其表现甚至超过了使用基线记忆系统的更大参数模型。
-
成本暴降:得益于高效的压缩和自适应检索,SimpleMem 将推理时的 Token 消耗降低了 30倍。
-
长程推理能力:在多跳推理(Multi-Hop Reasoning)任务中,SimpleMem 表现尤为出色,证明了其“分子化”的记忆表示能有效连接离散的事实,无需昂贵的迭代检索。
总结
SimpleMem 的核心价值在于它重新定义了 Agent 的记忆管理方式——从被动的“存储容器”转变为主动的“代谢系统”。
通过语义结构化压缩过滤噪音,通过递归整合提取抽象模式,再通过自适应检索精准构建上下文,SimpleMem 证明了:在 LLM Agent 的长期记忆设计中,少即是多(Less is More),但前提是必须存得“精”、取“准”。
对于正在构建长期伴侣 Agent 或复杂任务处理 Agent 的开发者来说,SimpleMem 提供了一个极具参考价值的高效架构范本。