SkillRouter: Retrieve-and-Rerank Skill Selection for LLM Agents at Scale
颠覆常识!阿里SkillRouter:Agent选对工具,代码比描述重要44%

当下的AI Agent正变得越来越“全能”,它们的背后是一个庞大且不断增长的技能(Skill)生态系统。从代码生成到API集成,成千上万的工具和插件让Agent的能力边界不断拓宽。
ArXiv URL:http://arxiv.org/abs/2603.22455v1
但这带来了一个棘手的问题:Agent的上下文窗口有限,不可能一次性“看到”所有可用的几万个技能。如何在海量技能库中,为用户的特定任务精准地“导航”到最合适的那个?
长久以来,行业内的普遍做法是“渐进式披露”(progressive disclosure):只给Agent看技能的名称和描述,认为这些元数据就足够了。然而,来自阿里的新研究SkillRouter,通过翔实的实验,彻底颠覆了这一常识。
研究的核心发现令人震惊:技能的代码实现本身,才是选择的关键信号。忽略代码,仅依赖名称和描述,会导致模型选择准确率暴跌29-44个百分点!
挑战传统认知:技能元数据足够吗?
目前主流的Agent架构,在面对海量技能时,为了节省宝贵的上下文空间,只会向模型展示技能的名称(name)和描述(description)。这背后隐藏着一个未经检验的假设:这些元数据足以让模型做出正确判断。
SkillRouter的研究者们对此发起了直接挑战。他们构建了一个包含约8万个技能和75个专家验证查询的基准测试集,并进行了一系列严格的对比实验。
实验设置很简单:比较两种输入配置下的模型表现。一种是\(nd\)模式,只使用名称+描述;另一种是\(full\)模式,使用名称+描述+代码实现。
结果怎么样呢?
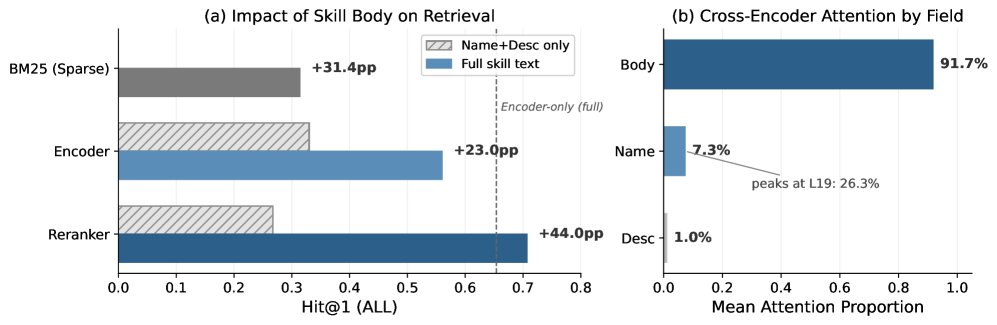
如上图左侧所示,结果堪称“惨烈”:
-
性能全面崩溃:无论是稀疏检索(如$BM25$)、密集检索编码器还是重排模型,一旦移除技能的代码实现(\(body\)),其性能都出现了灾难性下滑,准确率(Hit@1)下降了29到44个百分点。
-
传统方法失效:经典的$BM25$算法在\(nd\)模式下准确率直接归零。因为用户查询和技能的名称、描述之间几乎没有词汇重叠。
-
大模型也无能为力:即便是80亿参数的\(Qwen3-Emb-8B\)模型,在只看\(nd\)数据时,其表现也远不如一个只用了0.6B参数但看了\(full\)数据的模型。这说明,再大的模型也无法凭空弥补关键信息的缺失。
这一发现雄辩地证明,依赖名称和描述来选择技能,就像是“盲人摸象”,根本无法抓住技能的核心功能。
模型在看哪里?91.7%的注意力都在代码上
为了探究模型内部的工作机制,研究者进一步分析了重排模型(cross-encoder)的注意力分布。他们想知道,当模型同时看到名称、描述和代码时,它到底在“看”哪里?
上图右侧的注意力分析结果一目了然:
-
代码是绝对焦点:高达91.7%的注意力权重都集中在技能的\(body\)(代码实现)上。
-
名称是次要线索:\(name\)字段获得了7.3%的注意力。
-
描述几乎被忽略:\(description\)字段的注意力仅占1.0%,其信息价值似乎完全被代码内容所覆盖。
更有趣的是,注意力在不同网络层之间还会动态变化。模型在底层网络中首先理解代码内容,在中层网络中将代码功能与技能名称进行关联匹配,最后在高层网络中再次回归代码细节,做出最终的决策。
这些发现给Agent系统设计带来了直接启示:任何负责技能选择的组件,无论是检索器还是重排器,都必须能够访问到技能的完整代码实现。
SkillRouter:轻量高效的“两阶段”解决方案
基于以上洞察,该研究提出了一个专为大规模技能路由设计的实用管线——SkillRouter。它是一个总参数量仅为1.2B(0.6B编码器 + 0.6B重排器)的“检索-重排”(retrieve-and-rerank)架构,小巧的体积使其可以轻松部署在消费级硬件上。
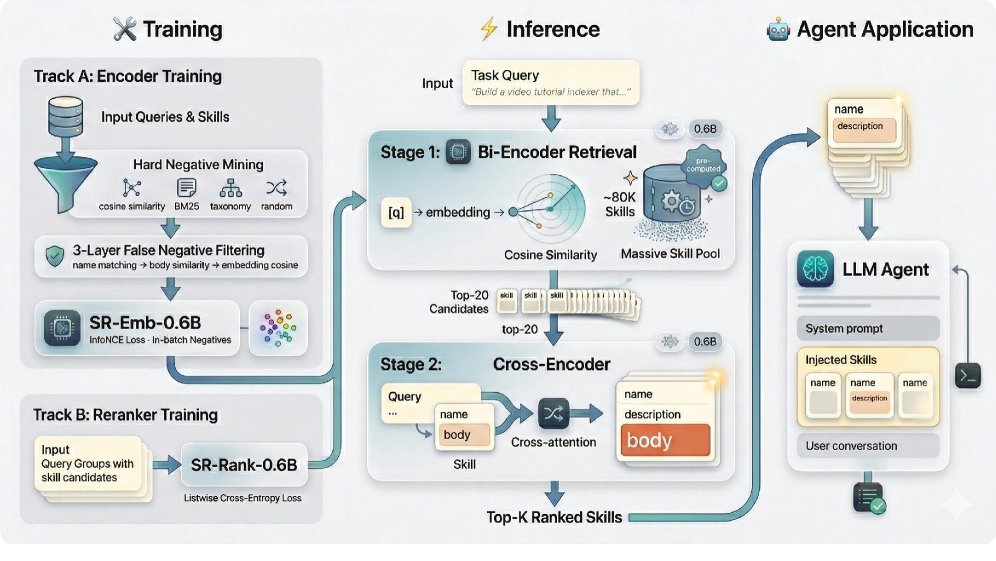
SkillRouter的工作流程分为两步:
-
第一阶段:Bi-Encoder粗筛
一个轻量级的0.6B双编码器(bi-encoder)\(SR-Emb-0.6B\)首先上场。它会快速扫描整个包含约8万个技能的技能池,基于完整的技能文本(名称+描述+代码)计算相似度,并迅速召回最相关的Top-20个候选技能。
-
第二阶段:Cross-Encoder精排
接着,一个0.6B的跨编码器(cross-encoder)\(SR-Rank-0.6B\)会对这20个候选技能进行精细化的重排序。它通过将用户查询和每个候选技能的完整文本进行深度交互(cross-attention),最终输出最精准的排序结果。
整个流程清晰高效,先用轻量模型进行“海选”,再用稍复杂的模型进行“决选”,在保证精度的同时,极大地提升了处理大规模技能库的效率。
实验效果:小模型也能超越大模型
SkillRouter的表现如何?实验结果证明了其设计的优越性。
| 模型 | 参数量 | 平均Hit@1 |
|---|---|---|
| BGE-Large-v1.5 (zero-shot) | 335M | 60.0% |
| text-emb-3-large (zero-shot) | Propri. | 62.0% |
| Qwen3-Emb-8B (zero-shot) | 8B | 64.0% |
| SR-Emb-0.6B (fine-tuned) | 0.6B | 65.4% |
| SkillRouter (SR-Emb-0.6B + SR-Rank-0.6B) | 1.2B | 74.0% |
| SkillRouter-8B (SR-Emb-8B + SR-Rank-8B) | 16B | 76.0% |
从上表(节选自论文表格)可以看出:
-
小模型战胜大模型:经过专门微调的0.6B检索器\(SR-Emb-0.6B\),其Top-1准确率(65.4%)已经超过了参数量是其13倍的8B零样本模型\(Qwen3-Emb-8B\)(64.0%)。这充分说明,针对性的数据和训练比单纯的模型规模更重要。
-
完整的SkillRouter性能卓越:完整的1.2B SkillRouter管线最终达到了74.0%的Top-1准确率,在所有紧凑型和零样本基线中表现最佳。
-
方法可扩展:同样的训练方法应用在8B模型上,可以将准确率进一步提升至76.0%,证明了该方法的普适性。
成功的秘诀:高质量训练与巧妙设计
SkillRouter的成功并非偶然,其背后是高质量的训练策略和巧妙的损失函数设计。
-
高质量数据生成:研究团队使用GPT-4o-mini为每个技能生成了贴近真实用户场景的查询,构建了高质量的训练数据集。
-
假阴性过滤(False Negative Filtering):在开源社区中,很多技能功能相似但名称不同。在对比学习中,这些技能容易被误判为“负样本”,从而干扰训练。SkillRouter设计了一个三层过滤管线,剔除了约10%的“假阴性”样本,使模型学习得更准确。
-
Listwise损失函数:在重排阶段,研究发现使用列表式交叉熵损失(Listwise Cross-Entropy Loss)比传统的点式损失(Pointwise Loss)效果好得多,准确率提升了惊人的30.7个百分点。因为前者能更好地学习候选技能之间的相对顺序,这对于排序任务至关重要。
总结
SkillRouter这项研究不仅为构建更强大的LLM Agent提供了坚实的理论依据和实用的技术方案,更重要的是,它挑战并修正了行业内一个长期存在的“想当然”的设计假设。
它告诉我们:细节决定成败。对于AI Agent而言,技能的“说明书”(名称和描述)固然重要,但真正定义其能力的,是那一行行具体的“代码实现”。只有让模型深入到代码层面去理解和匹配,才能在浩如烟海的技能库中,为用户的每一个需求,找到那个最精准的答案。