SlideAgent: Hierarchical Agentic Framework for Multi-Page Visual Document Understanding
-
ArXiv URL: http://arxiv.org/abs/2510.26615v2
-
作者: Yiqiao Jin; Sumitra Ganesh; Rachneet Kaur; Srijan Kumar; Zhen Zeng
-
发布机构: Georgia Institute of Technology; J.P. Morgan
TL;DR
本文提出了一种名为 SlideAgent 的分层智能体框架,通过设置全局、页面、元素三个级别的专业智能体,将复杂的多页视觉文档理解任务分解,先构建独立于查询的结构化知识库,再进行针对性推理,从而显著提升了大型语言模型在处理幻灯片等文档时的细粒度理解和推理能力。
关键定义
本文提出或沿用了以下对理解其核心方法至关重要的概念:
- SlideAgent: 本文提出的核心框架,一个用于理解多模态、多页、多布局文档(尤其是幻灯片)的通用智能体 (Agentic) 框架。
- 分层智能体架构 (Hierarchical Agentic Architecture): SlideAgent 的核心结构,它模仿人类信息处理模式,将复杂的推理任务分解到三个专门的级别:
- 全局智能体 (Global Agent): 负责生成文档级别的知识,捕捉整个文档的总体摘要、目标和叙事流。
- 页面智能体 (Page Agent): 负责处理单个页面的内容,生成页面级别的知识,并理解页面之间的关联。
- 元素智能体 (Element Agent): 负责最细粒度的分析,将页面分解为图表、文本块等元素,并提取其空间、结构和语义信息。
- 知识构建 (Knowledge Construction): SlideAgent 的第一阶段,一个与查询无关 (query-agnostic) 的过程。在此阶段,分层智能体们处理输入文档,自顶向下地构建一个包含全局、页面和元素三个层级的结构化知识库 \(K\)。
- 推理阶段 (Inference Stage): SlideAgent 的第二阶段,一个与查询相关 (query-specific) 的过程。在此阶段,系统首先对用户查询进行分类,激活相应的智能体,生成子查询以优化检索,然后各智能体基于检索到的知识进行推理,最后综合所有信息生成最终答案。
相关工作
当前,多模态大型语言模型 (Multimodal Large Language Models, MLLMs) 在文档理解领域取得了显著进展,但仍面临三大核心瓶颈:
- 整体性处理与细粒度缺失: SOTA 模型一次能处理的图像数量有限,且倾向于将页面作为一个整体进行理解,这导致它们常常忽略用户查询所需的细粒度、元素级别的信息。例如,模型在识别杂乱页面中的图表分段时容易出错,但如果将图表单独裁剪出来,则能正确识别。
- 领域特定视觉语言的理解不足: MLLM 大多在自然图像上预训练,缺乏对金融图表、科学绘图、特定图标等专业视觉语言的接触。因此,它们难以理解颜色方案(如金融报告中红色代表亏损)、图标的抽象含义(如灯泡代表创新)以及空间布局的重要性(如居中元素更重要)。
- 对结构化元数据的依赖: 许多现有系统依赖于文档中干净的元数据(如图表位置、文本层等),但在现实世界中,这些元数据常常因扫描、截图或格式转换而丢失或损坏。而无元数据的方法虽然适用性更广,但性能上存在差距。
本文旨在解决上述问题,特别是如何让模型在不依赖清洁元数据的情况下,对多页、多模态的复杂视觉文档(如幻灯片)进行精准的、跨越页面和元素的细粒度推理。
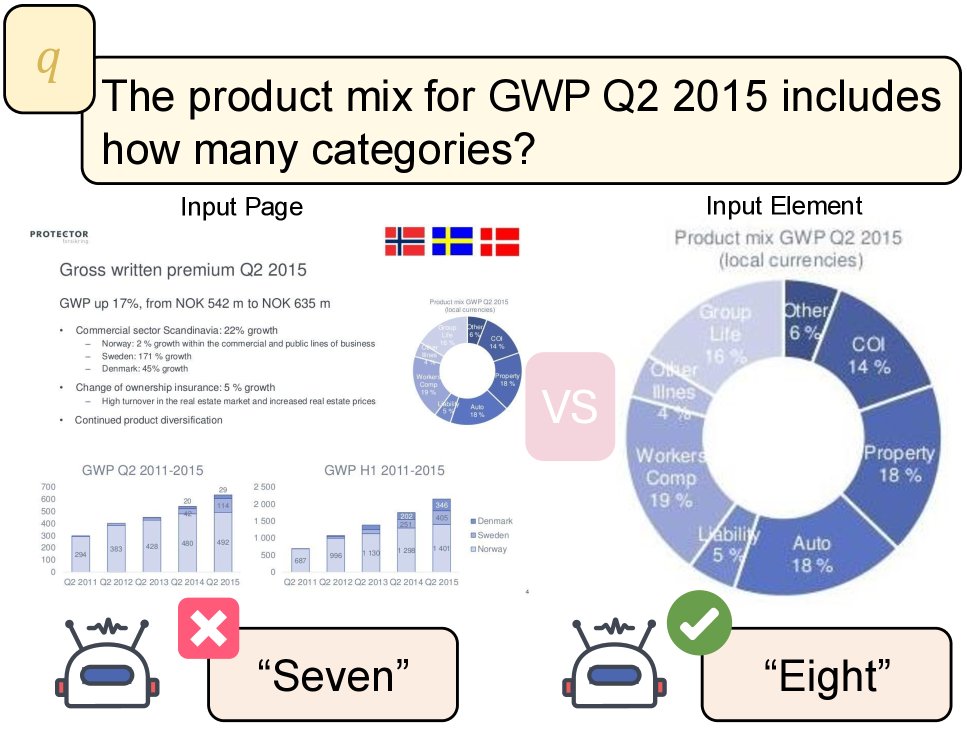
本文方法
SlideAgent 的核心是一个分为两个阶段的分层智能体框架:知识构建和推理。其目标是为给定的多页视觉文档 $\mathcal{P}$ 和一个查询 $q$,生成一个自然的答案 $a$。
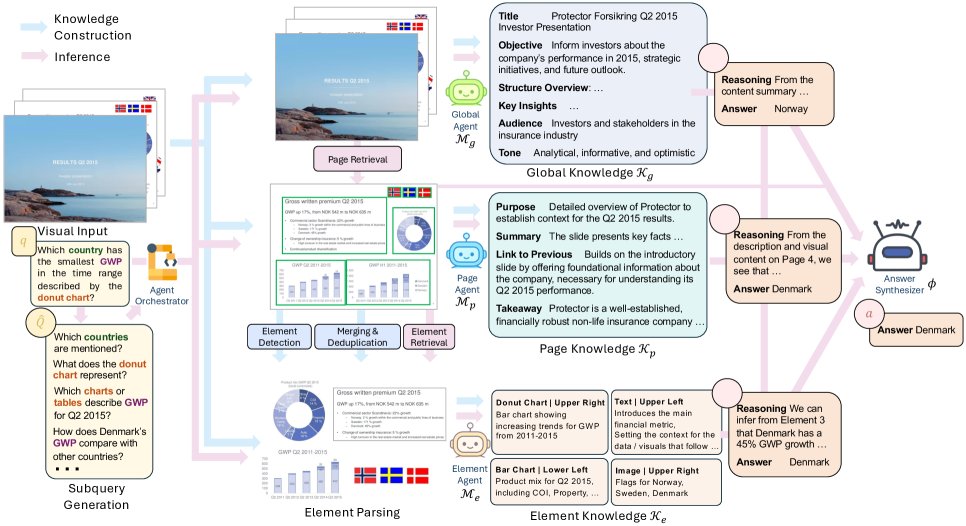
知识构建阶段
此阶段的目标是构建一个与查询无关的、分层的知识库 $\mathcal{K}={\mathcal{K}_{g},\mathcal{K}_{p},\mathcal{K}_{e}}$,它以自顶向下的方式进行。
全局智能体
全局智能体 $\mathcal{M}_{g}$ 通过分析文档的少数几页(如前三页)来生成文档级的全局知识 $\mathcal{K}_{g}$。这份知识捕捉了文档的整体主题、目标和叙事结构,为后续的推理提供了高层次的上下文。
页面智能体
对于文档中的每一页 $p_{i}$,页面智能体 $\mathcal{M}_{p}$ 依次生成页面级知识 $\mathcal{K}_{p}^{i}$。该过程不仅依赖当前页面的视觉内容 $v_{i}$,还以前面生成的全局知识 $\mathcal{K}_{g}$ 和前一页的知识 $\mathcal{K}_{p}^{i-1}$ 作为上下文:
\[\mathcal{K}_{p}^{i}=\mathcal{M}_{p}(v_{i},\mathcal{K}_{g},\mathcal{K}_{p}^{i-1}),\quad i\in[1, \mid \mathcal{P} \mid ].\quad \mathcal{K}_{p}^{0}=\emptyset\]所有页面的知识 $\mathcal{K}_{p}$ 汇总后,会反过来用于精炼全局知识 $\mathcal{K}_{g}$,确保全局视图的完整性。
元素智能体
为了解决 MLLM 在空间推理上的不足,元素智能体引入外部工具来显式地捕捉页面内的空间和结构信息。它首先使用一个布局解析管道 $f$ 将每个页面 $p_i$ 分解为一组元素(文本、图表等),每个元素包含其页码 $i$、文本内容 $e_j$、边界框 $b_j$ 和类型 $t_j$。
然后,元素智能体 $\mathcal{M}_{e}$ 为每个被检测到的元素生成元素级知识 $\mathcal{K}_{e}^{j}$,描述其语义角色、功能目的及其与所在页面的关系:
\[\mathcal{K}_{e}^{j}=\mathcal{M}_{e}(i,v_{i},e_{j},b_{j},t_{j},\mathcal{K}_{g},\mathcal{K}_{p}^{i})\]这种设计使得 SlideAgent 能够保留元素的空间关系,为细粒度的文档理解提供了坚实基础。
推理阶段
此阶段利用已构建的知识库 $\mathcal{K}$ 来回答用户查询 $q$。
查询分类
为了提高效率和准确性,系统首先将查询 $q$ 分类到预定义的类别中(如全局理解、事实查询、多跳推理等)。不同的类别对应不同的问答策略和需要激活的智能体组合。例如,“全局理解”类查询仅激活全局智能体,而“事实查询”则需要页面和元素智能体的协同。
子查询生成与检索
原始查询通常很简短,直接用于检索可能会产生噪声。因此,SlideAgent 会根据查询中的关键词生成更具体的子查询 $\hat{Q}$。原始查询和子查询将共同用于从知识库中检索最相关的页面 $\hat{\mathcal{P}}$ 和元素 $\hat{\mathcal{E}}$。
答案生成与综合
系统引导各级智能体在分层上下文中进行结构化推理,分别生成各自的假设 $h_g$ (全局)、$h_p$ (页面) 和 $h_e$ (元素)。
- 如果所有被激活的智能体生成的答案一致,或者只有一个智能体被激活,系统将直接采用其答案。
- 否则,一个答案综合器 $\phi(\cdot)$ 会被调用,它融合来自所有智能体的推理过程以及检索到的页面视觉信息,生成最终的答案 $a$:
创新点
- 分层分解推理: 最大的创新在于将复杂的文档理解任务分解为全局、页面、元素三个层次,并为每个层次指派专门的智能体。这种分而治之的策略显著降低了问题的复杂度,使得推理过程更具结构性和可解释性。
- 两阶段解耦设计: 将“与查询无关的知识构建”和“与查询相关的推理”分离。这种设计创建了一个可复用的、结构化的知识资产,使得推理过程不仅更高效,而且具有很好的可扩展性。
- 显式空间信息融合: 通过元素智能体和布局解析工具,SlideAgent 显式地捕捉和利用元素的空间位置和结构信息,直接弥补了现有 MLLM 在空间推理能力上的短板。
- 模型无关的框架: SlideAgent 是一个灵活的框架,可以与各种不同的闭源或开源 LLM/MLLM 模型结合使用,具有很强的通用性。
实验结论
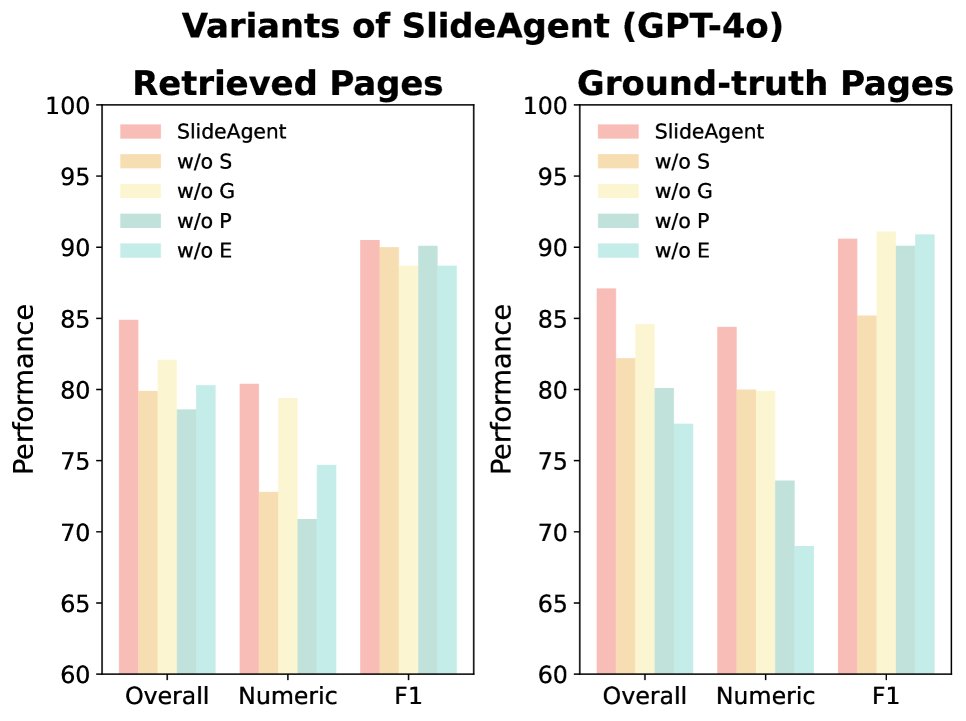
实验结果表明,SlideAgent 框架能显著提升现有大模型在多页视觉文档理解任务上的表现。
核心实验结果
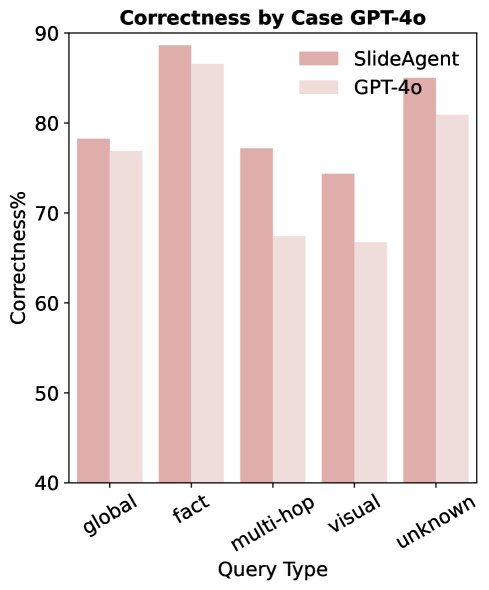
- 端到端性能显著提升: 无论是在闭源模型 (GPT-4o) 还是开源模型 (InternVL3-8B) 上,SlideAgent 都一致性地超越了所有基线方法和其基础模型本身。例如,在 SlideVQA 数据集上,相较于其基础模型 GPT-4o,SlideAgent 带来了 7.9% 的整体准确率提升。值得注意的是,搭载了 SlideAgent 的 GPT-4o 甚至能超越能力更强的原始 LLM(如 Gemini-2.5)。
| 方法 | Overall | Num | F1 |
|---|---|---|---|
| 原始 LLM | |||
| Gemini 2.0 | 72.3 | 66.1 | 81.3 |
| Gemini 2.5 | 83.8 | 77.2 | 90.8 |
| Gemini 2.5 lite | 71.7 | 62.6 | 87.0 |
| Claude 4.1 | 36.3 | 35.4 | 38.9 |
| Claude 3.5 | 31.5 | 30.8 | 37.0 |
| GPT-4o | 77.0 | 69.3 | 90.5 |
| 多模态RAG与智能体方法 | |||
| ViDoRAG | 71.2 | 60.5 | 90.7 |
| SlideAgent (GPT-4o) | 84.9 | 81.8 | 89.8 |
| 性能提升 (Impr.) | +7.9 | +12.5 | -0.7 |
在给定真实答案页面(Oracle Setting)时,SlideAgent 依然能大幅提升基础模型的性能,特别是在数值推理上。
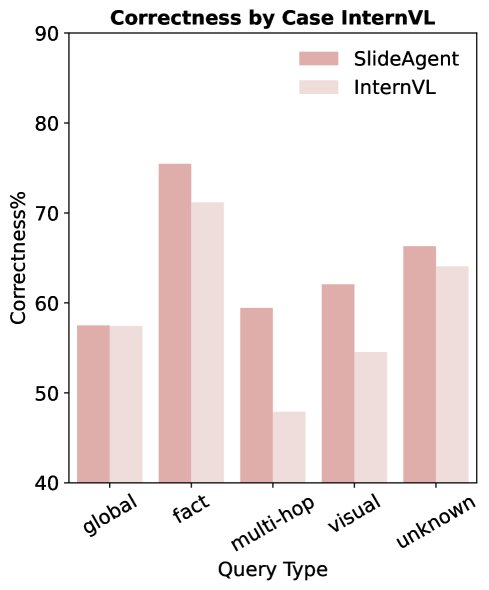
- 在复杂推理任务上优势明显: SlideAgent 在需要多跳推理 (multi-hop reasoning) 和视觉/布局理解 (visual/layout reasoning) 的问题上表现尤为出色,准确率分别提升了 9.8 和 7.7 个百分点。这证明了其分层结构和元素级分析对于解决复杂逻辑链和空间关系问题至关重要。
- 知识构建有效性验证: SlideAgent 在第一阶段生成的结构化知识和子查询,能有效提升后续检索器的性能。实验表明,无论是基于文本的检索器还是多模态检索器,在使用 SlideAgent 生成的辅助信息后,其页面检索的准确率(MRR, Recall@k 等指标)均有提升,尤其对文本检索器的提升最大。
| 检索器类型 | 检索器 | MRR | Recall@1 | nDCG@1 | Recall@3 |
|---|---|---|---|---|---|
| 文本检索器 | SFR | 70.1 | 56.1 | 60.9 | 75.8 |
| w/ SlideAgent | 76.5 | 59.9 | 69.4 | 77.3 | |
| 多模态检索器 | COLPALI | 82.1 | 68.2 | 75.5 | 78.9 |
| w/ SlideAgent | 82.9 | 70.4 | 76.2 | 88.6 |
SlideAgent 生成的知识能显著提升页面检索性能。
- 消融研究证明各组件的重要性: 消融实验显示,移除页面智能体对模型性能的损害最大,这凸显了它在连接全局上下文和元素级细节、支持跨页推理方面的关键作用。
总结
实验全面验证了 SlideAgent 框架的有效性。通过将复杂的文档理解任务进行分层分解,并为每个层次配备专门的智能体,SlideAgent 能够系统性地弥补现有大模型在细粒度理解、空间推理和多跳逻辑方面的不足,从而在处理幻灯片等多页视觉文档时取得稳定且显著的性能提升。