告别硬裁剪!阿里SAPO算法,用“柔性门控”提升LLM训练稳定性与性能

用强化学习(RL)来提升大语言模型(LLM)的推理能力,已是业界共识。但这条路并不好走,训练过程常常像坐过山车,极不稳定。一个核心痛点在于,现有的优化算法,如GRPO和GSPO,普遍采用“硬裁剪”(Hard Clipping)策略来控制更新幅度,这种方法虽然能防止模型跑偏,但也像一把“一刀切”的剪刀,常常错杀有用的学习信号,导致训练效率和最终性能难以两全。
ArXiv URL:http://arxiv.org/abs/2511.20347v1
有没有一种更优雅、更智能的方式来驯服这头“性能猛兽”呢?
来自阿里巴巴的研究团队给出了答案:柔性自适应策略优化(Soft Adaptive Policy Optimization, SAPO)。它用一个平滑的、可控的“柔性门控”取代了生硬的裁剪,实现了训练稳定性与模型性能的双重提升。
SAPO的核心思想:柔性门控
想象一下,传统方法(如GRPO/GSPO)就像一个电灯开关,对于偏离当前策略太远的更新信号,直接“关灯”,梯度瞬间归零。这种做法过于粗暴。
而SAPO则像一个调光器。它引入了一个由温度参数 $\tau$ 控制的Sigmoid函数,构建了一个平滑的门控机制。
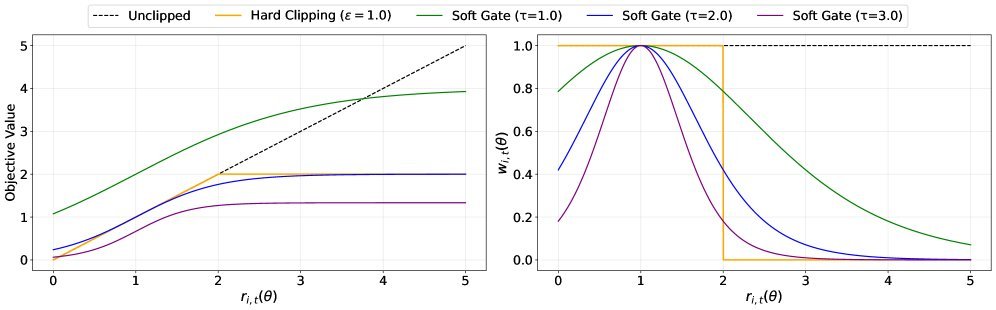
图1:不同优化目标对比。左:代理目标值;右:梯度权重。SAPO(蓝色)的曲线平滑过渡,而GRPO/GSPO(橙/绿)在裁剪点有明显断崖。
从上图可以直观地看到:
-
当更新信号与当前策略接近时(即策略比率 $r_{i,t}(\theta)$ 接近1),SAPO会完整保留梯度,鼓励模型进行有效探索。
-
当信号偏离较远时,SAPO会平滑地衰减其权重,而不是直接掐断。
-
这样既抑制了可能导致不稳定的剧烈更新,又保留了那些“出格”但仍有价值的学习信号,显著提升了样本效率。
其目标函数可以简洁地表示为:
\[\mathcal{J}(\theta)=\mathbb{E}\Bigg[\frac{1}{G}\sum_{i=1}^{G}\frac{1}{ \mid y_{i} \mid }\sum_{t=1}^{ \mid y_{i} \mid }f_{i,t}(r_{i,t}(\theta))\widehat{A}_{i,t}\Bigg]\]其中,核心的门控函数 $f_{i,t}(x)$ 由一个缩放的Sigmoid函数构成,其梯度权重 $w_{i,t}(\theta)$ 呈现出优美的钟形曲线,实现了对梯度的“柔性”控制。
非对称温度:稳定性的秘密武器
SAPO还有一个精妙的设计:非对称温度(Asymmetric Temperatures)。它为正向奖励和负向奖励的Token设置了不同的温度参数 $\tau_{pos}$ 和 $\tau_{neg}$,并且通常让 $\tau_{neg} > \tau_{pos}$。
为什么要这么做?
研究发现,在拥有巨大词表(动辄数十万Token)的LLM中,负向奖励的更新更容易引发不稳定。一个负向更新会试图提升大量不相关Token的概率,这种弥散效应就像在平静的湖面扔下一大把石子,容易激起波澜。
而正向更新则更聚焦,只需提升目标Token的概率。
因此,通过为负向奖励设置一个更高的温度($\tau_{neg} > \tau_{pos}$),SAPO能让其对应的梯度权重衰减得更快,从而更有效地抑制潜在的不稳定因素。
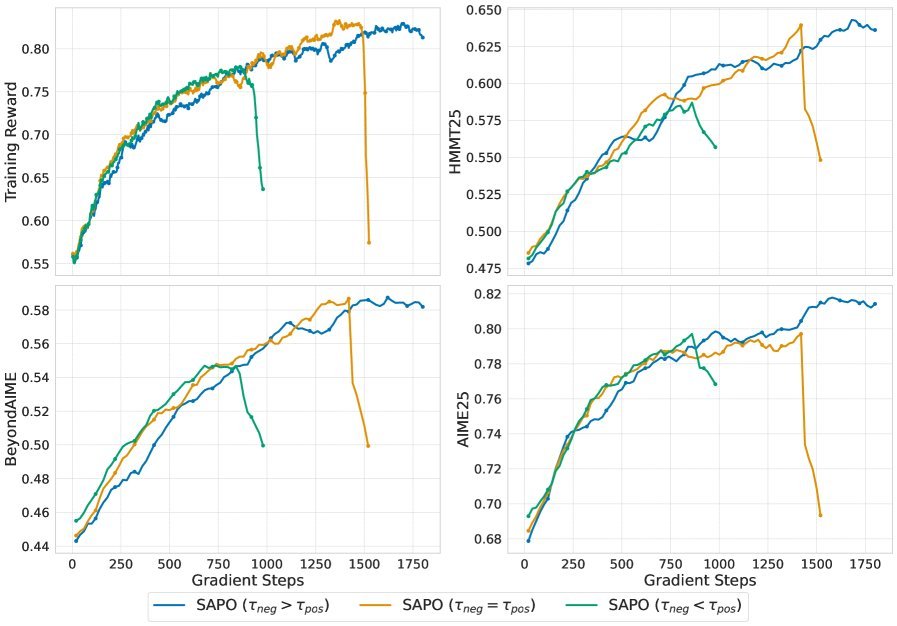
图:不同温度设置下的训练稳定性。当负向温度更高时($\tau_{neg}=1.05$,蓝色),训练最稳定。
实验结果清晰地验证了这一点:当 $\tau_{neg} > \tau_{pos}$ 时,训练过程最为稳定。
兼具序列连贯性与Token自适应性
SAPO巧妙地融合了GSPO和GRPO两类方法的优点。
-
与GSPO的联系:研究证明,在常规情况下(即更新步长较小,序列内Token差异不大),SAPO的平均Token级门控会自然地收敛为一个序列级的平滑门控。这使得SAPO具备了类似GSPO的序列连贯性(sequence-level coherence),但其信任区域是连续的,避免了GSPO硬裁剪带来的脆弱性。
-
对GSPO的超越:当一个序列中出现少数“害群之马”(极端离群的Token)时,GSPO会因为整个序列的策略比率超出范围而放弃对该序列的所有更新。SAPO则展现出Token自适应性(token-level adaptivity),它只会精准地降低离群Token的权重,同时保留序列中其他正常Token的有效梯度,大大提高了样本利用率。
-
对GRPO的优势:相对于GRPO在Token级别进行“全有或全无”的硬裁剪,SAPO的平滑缩放机制显然更加稳健和信息丰富,避免了梯度突变,让优化过程如丝般顺滑。
实验效果:更稳、更高、更强
无论是在受控的数学推理任务实验中,还是在Qwen3-VL系列模型的大规模实战训练里,SAPO都表现出了卓越的性能。
在对Qwen3-30B-A3B模型的微调实验中,与GSPO和GRPO-R2相比,SAPO不仅训练过程更稳定,避免了过早的性能崩溃,而且在相同的计算预算下取得了更高的最终性能(Pass@1)。
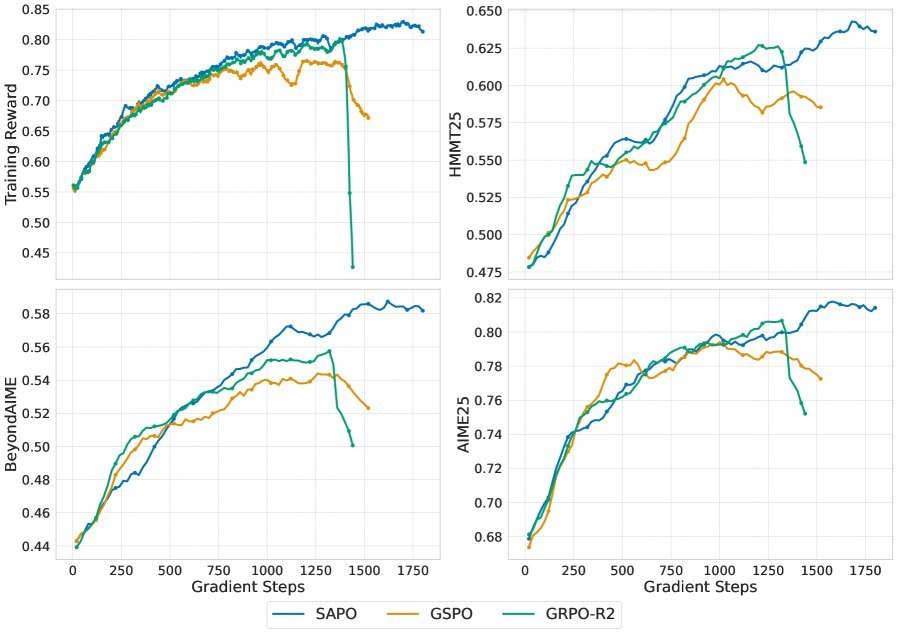
图:在数学推理任务上,SAPO(蓝色)的训练奖励和验证性能持续稳定增长,显著优于早期崩溃的GSPO和GRPO-R2。
更重要的是,SAPO成功应用于Qwen3-VL系列模型的训练,覆盖了从稠密到MoE架构、从文本到多模态的各种复杂场景,展现出了一致的性能增益。
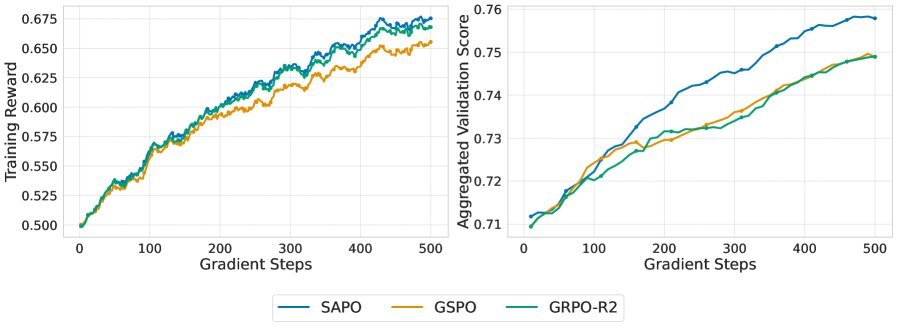
图:在Qwen3-VL大规模训练中,SAPO(蓝色)同样实现了持续的性能改进,优于基线方法。
结语
SAPO通过引入平滑的、温度控制的柔性门控,并采用非对称温度设计,成功解决了LLM强化学习中长期存在的稳定性与效率权衡难题。它不仅在理论上优雅,更在实践中证明了其作为一种更可靠、可扩展且高效的优化策略的巨大潜力。
这项工作表明,用更平滑、自适应的机制取代传统的硬裁剪,是未来提升大模型RL训练鲁棒性和有效性的一个光明方向。