SonicMoE: Accelerating MoE with IO and Tile-aware Optimizations
SonicMoE:64张H100顶96张用,MoE训练显存暴降45%

DeepSeek V3、Qwen2.5-MoE 等模型的爆火,让 混合专家模型(Mixture of Experts, MoE)成为了大模型扩展的“版本答案”。大家都在追求更细粒度的专家(Fine-grained Experts)和更高的稀疏度,试图在不增加计算量的前提下榨干模型性能。
ArXiv URL:http://arxiv.org/abs/2512.14080v1
然而,天下没有免费的午餐。当专家变得越来越小、越来越碎时,GPU 却开始“叫苦连天”:显存占用飙升,IO 瓶颈卡死计算单元,原本高效的 GEMM 运算因为数据填充(Padding)浪费了大量算力。
来自普林斯顿大学、Together AI 和 UC Berkeley 的研究团队推出了 SonicMoE,这是一套软硬协同的 MoE 加速方案。它不仅让 MoE 训练的显存占用减少了 45%,更在 NVIDIA H100 上实现了 1.86倍 的吞吐提升。最夸张的是,使用 SonicMoE 的 64 张 H100,其训练吞吐量竟然能媲美使用现有最强方案(ScatterMoE)的 96 张 H100!
这不仅仅是优化,这是给你的 GPU 集群省下了几百万美元。
细粒度 MoE 的“富贵病”
MoE 的发展趋势很明显:专家越来越多,但每个专家的个头越来越小(细粒度),同时每次激活的专家数量保持不变(高稀疏度)。
这种设计虽然提升了模型效果,但对硬件极不友好:
-
显存爆炸:前向传播产生的激活值(Activation)通常与激活的专家数量成线性关系。专家分得越细,需要缓存的显存就越多。
-
IO 瓶颈:细粒度意味着 GPU 需要频繁地从不同位置搬运数据(Gather/Scatter),导致计算单元经常处于“等数据”的空转状态。
-
算力浪费:GPU 喜欢整齐划一的矩阵运算。当分配给某个专家的 Token 数量不是 GPU 处理块(Tile)的整数倍时,就需要填充 0(Padding),这些无效计算就是纯纯的浪费。
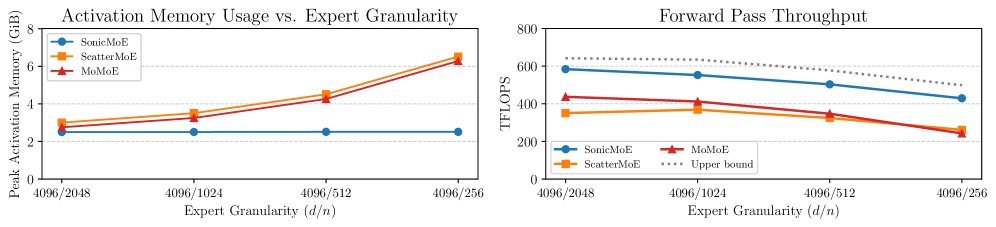
图 1:SonicMoE(蓝色)不仅将显存占用压到了最低且保持恒定(左图),还在计算吞吐上逼近了硬件理论上限(右图)。
核心大招一:极致的显存“抠门”艺术
通常,为了计算反向传播(Backward Pass)中的梯度,我们需要在前向传播时把中间结果(激活值)存下来。在现有的 MoE 内核(如 ScatterMoE)中,存下来的数据量会随着专家粒度的变细而线性增长。
SonicMoE 的思路非常刁钻:既然存不下,那就不存了,算的时候再凑!
研究团队重新设计了反向传播算法。他们发现,通过精巧的计算图重构,可以避免缓存那些体积巨大的中间变量(如聚合后的 $X$ 或输出 $Y$)。相反,他们只缓存最原始的输入 $X$ 和必要的路由元数据。
虽然这听起来像是增加了计算量(重计算),但由于省去了巨大的显存读写开销,整体效率反而更高。结果就是,无论你的专家切分得多么细,SonicMoE 的显存占用都保持恒定,比基线方法节省了 20%-45% 的显存。
核心大招二:IO 与计算的“无缝衔接”
在 H100 (Hopper) 和未来的 Blackwell 架构 GPU 上,算力极其强大,以至于内存搬运(IO)往往跟不上计算速度。
SonicMoE 充分利用了新一代 GPU 的硬件特性,设计了 IO-aware Kernel。它能够将繁重的内存读取操作(从 HBM 到 SRAM)与矩阵乘法计算(GEMM)进行流水线重叠(Overlap)。
简单来说,就是趁着 GPU 计算单元还在忙着算上一波数据时,内存单元已经悄悄把下一波数据搬到了门口。这种“打时间差”的策略,使得 SonicMoE 在前向传播上比高度优化的 DeepGEMM 快了 43%,在反向传播上更是比 ScatterMoE 快了 83%。
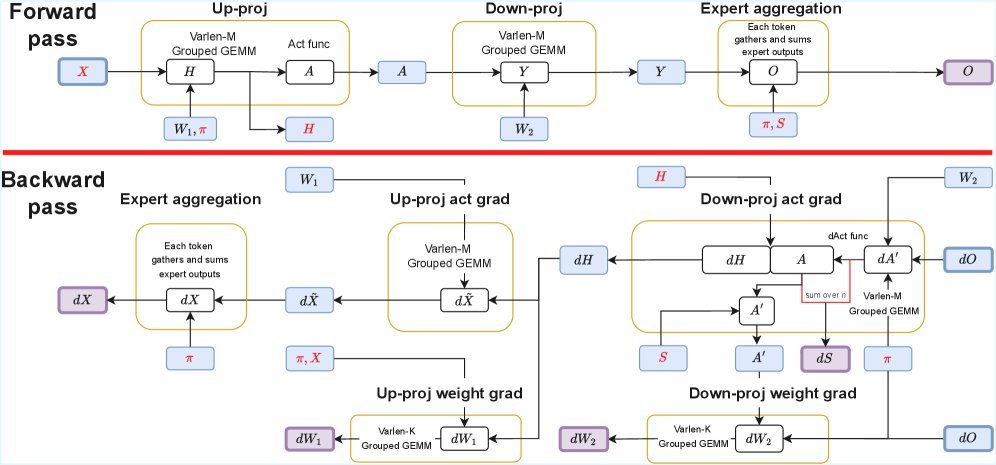
图 2:SonicMoE 的内核工作流。通过高度模块化的设计,将 IO 操作隐藏在计算背后。
核心大招三:Token Rounding —— 拒绝填充浪费
这是本文最有趣的一个创新点。
在 MoE 中,Token 会被路由到不同的专家。由于路由是动态的,分给某个专家的 Token 数量往往是参差不齐的。而 GPU 进行分组矩阵运算(Grouped GEMM)时,通常以 128 或 64 个 Token 为一个处理块(Tile)。如果一个专家分到了 130 个 Token,为了凑整,就得补上 126 个空 Token,这 126 次计算全是浪费。
SonicMoE 提出了一种 Token Rounding (TR) 路由策略。
它的逻辑是:与其被动填充,不如主动凑整。 算法会强制将分配给每个专家的 Token 数量“取整”到 Tile Size 的倍数。
-
如果某个专家分到的 Token 稍微多了一点,就丢弃几个(通常是权重最低的)。
-
如果稍微少了一点,就从别的专家那里“借”几个或者补几个。
你可能会问,这样不会影响模型精度吗?实验表明,这种微调对模型效果的影响微乎其微,但在高稀疏度场景下,它能消除几乎所有的 Padding 浪费。
在 1.4B 参数的稀疏训练设置下,仅靠这一招,端到端的训练吞吐量就提升了 16%。
总结
SonicMoE 是一次典型的“软硬协同设计”的胜利。它没有盲目堆砌算力,而是深入剖析了 MoE 在新一代硬件上的痛点:
-
用算法重构解决了显存瓶颈。
-
用流水线掩盖解决了 IO 瓶颈。
-
用Token 取整解决了算力浪费。
对于正在训练 DeepSeek V3 级别 MoE 模型的团队来说,SonicMoE 提供的开源内核无疑是一个巨大的福音。毕竟,在这个算力紧缺的时代,能用 64 张卡干出 96 张卡的活,谁能不心动呢?