SortedRL: Accelerating RL Training for LLMs through Online Length-Aware Scheduling
SortedRL:简单排个序,LLM强化学习训练吞吐量提升近40%,性能最高涨18%

当今的大模型(LLM)要变得更会推理,尤其是解决复杂的数学和逻辑问题时,强化学习(RL)已成为一把不可或缺的利器。然而,这条路并不平坦。一个巨大的瓶颈正拖慢整个进程:RL训练中高达70%的时间,都可能消耗在漫长的文本生成(Rollout)阶段。
ArXiv URL:http://arxiv.org/abs/2603.23414v1
想象一下,GPU集群正在全力运转,但因为一批任务中总有几个“慢郎中”(需要生成超长文本),导致大部分算力只能“干瞪眼”等着,这就是所谓的计算“气泡”。最近,来自微软亚洲研究院等机构的一项研究 SortedRL,提出了一种极为巧妙的策略,仅通过在线“排个序”,就几乎完美地解决了这个难题。
RL训练的“气泡”困境
在典型的LLM强化学习流程中,模型需要先根据提示(prompt)生成一系列解决方案(即Rollout),然后根据这些方案的好坏(奖励)来更新自身参数。问题在于,不同提示生成文本的长度天差地别。
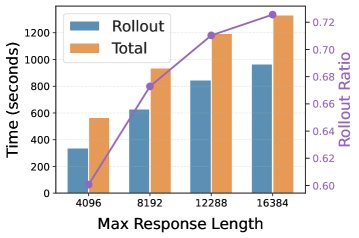
图1(a)清晰地显示,在需要长思维链(CoT)的任务中,Rollout阶段占据了绝大部分训练时间。
如下图所示,在一个批次中,多数任务可能很快完成,但少数任务需要生成极长的文本。由于更新步骤必须等待批次中所有任务都生成完毕,这导致了严重的资源浪费和效率低下,形成了巨大的计算“气泡”。
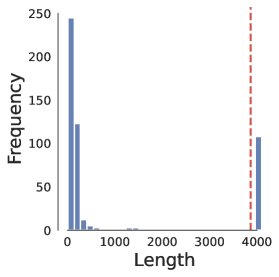
图1(c)展示了生成长度的长尾分布特性,这正是“气泡”问题的根源。
有人可能会问,为什么不直接用大模型推理服务中常见的连续批处理(Continuous Batching)技术呢?因为RL训练要求生成和更新步骤紧密同步,模型参数在不断变化,这使得那些为静态模型设计的优化技术难以直接应用。
SortedRL:化繁为简的在线调度策略
为了刺破这些“气泡”,SortedRL提出了一种在线长度感知调度(Online Length-Aware Scheduling)策略。其核心思想非常直观:不再让快的等慢的,而是让快的先“跑”!
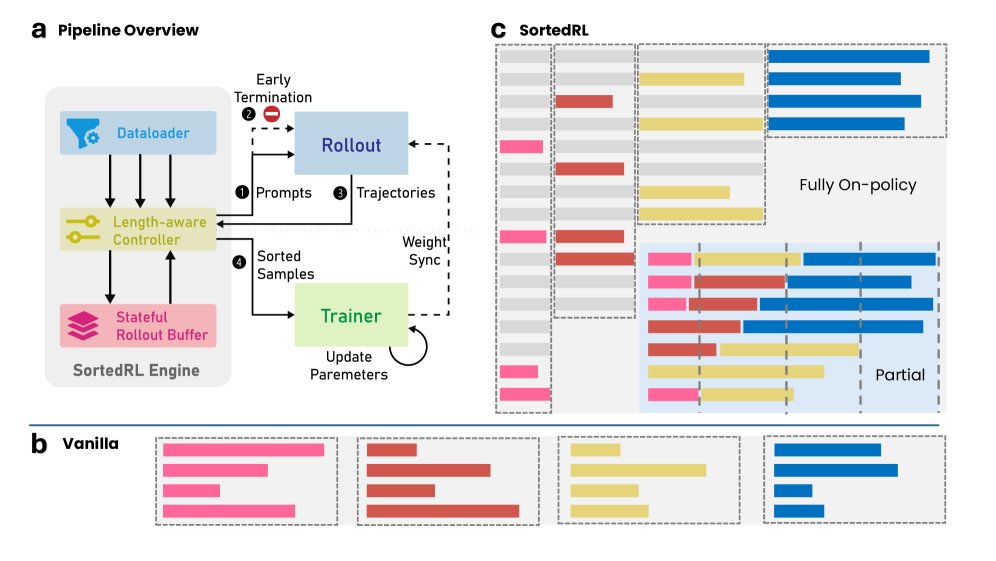
SortedRL通过一个长度感知控制器和状态化Rollout缓冲区,实现了动态、高效的训练流程。
该方法主要包含三大关键设计:
1. 在线长度感知调度
这是SortedRL的灵魂。系统在Rollout过程中实时监控每个任务的生成长度。一旦收集到足够数量的“短”输出,就立即将它们打包送去训练,而不用等待那些仍在生成中的“长”输出。
更妙的是,用这些短样本更新后的模型,会立刻被用来继续生成剩余的长样本。这不仅极大地减少了GPU的空闲时间,还自然而然地形成了一种微课程(Micro-curriculum):模型总是先从简单的(短的)任务学起,再挑战复杂的(长的)任务,这有助于提升学习效率和稳定性。
2. 可控的离策略(Off-policy)采样
SortedRL提供了两种灵活的运行模式:
-
完全在线策略(Fully on-policy)模式:只使用最新模型生成的数据进行训练,保证了训练的稳定性。对于未完成的长任务,会中断其生成,并在下一轮用新模型重新开始。
-
部分离策略(Partial)模式:为了极致的样本效率,该模式会缓存并“回收”上一轮未完成的生成片段及其对应的$log$概率。在下一轮中,模型会从中断处继续生成,从而避免了浪费。
这种设计允许研究者在训练稳定性和计算效率之间做出灵活的权衡。
3. 协同设计的RL基础设施
为了支撑上述调度策略,研究者专门设计了一套RL基础设施。它包含一个长度感知控制器(Length-aware Controller)来管理Rollout过程,以及一个状态化Rollout缓冲区(Stateful Rollout Buffer)来动态协调数据流和模型更新,从而最大化吞吐量。
惊人的实验效果
SortedRL的效果堪称立竿见影,无论在效率还是性能上都取得了显著突破。
效率大幅提升:计算“气泡”几乎消失
在吞吐量测试中,研究者对比了基线方法与SortedRL的两种模式。结果显示,SortedRL的完全在线策略模式和部分离策略模式分别带来了7.57%和39.48%的吞吐量提升。
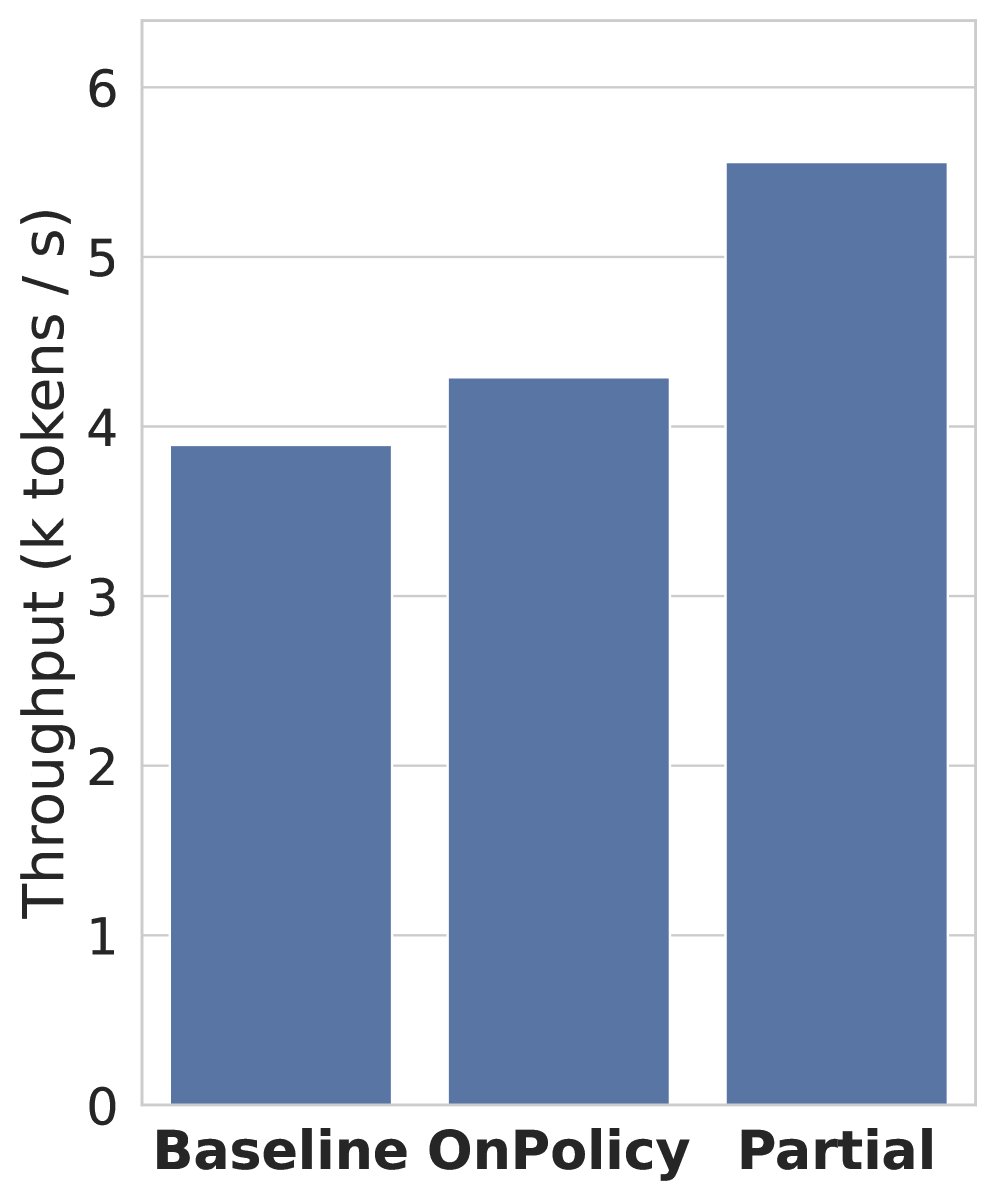
更直观的是“气泡率”的下降。基线方法的计算气泡率高达74%,而SortedRL的两种模式分别将其压缩到了惊人的5.81%和3.37%!这意味着GPU的有效利用率得到了极大提升。
性能显著增强:更强的数学与逻辑推理
在逻辑推理任务上,使用LLaMA-3.1-8B模型,SortedRL仅用减少40.74%的样本就达到了与基线相同的性能水平,展现了卓越的样本效率。
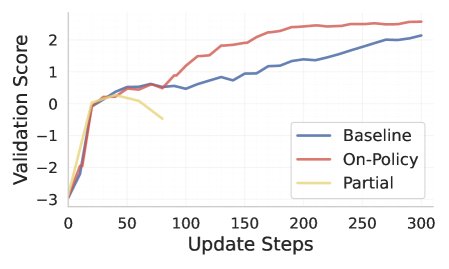
SortedRL(绿色实线)更快地达到了高分,并且模型更早开始探索生成更长的、更复杂的推理路径。
在更具挑战性的数学问题上(如AIME 24、Minerva等),研究团队使用Qwen-2.5-32B模型进行了测试。在消耗相同训练数据的情况下,SortedRL带来的性能提升在3.9%到18.4%之间。特别是在高难度的AIME 2024竞赛题上,准确率提升超过了18%!
| Benchmark | Baseline | SortedRL (On-Policy) | SortedRL (Partial) |
|---|---|---|---|
| MATH500 | 46.80 | 49.40 (+2.60) | 48.60 (+1.80) |
| Minerva | 34.00 | 36.80 (+2.80) | 35.80 (+1.80) |
| OlympiadBench | 18.00 | 18.60 (+0.60) | 19.80 (+1.80) |
| AIME 2024 | 10.31 | 12.21 (+1.90) | 11.25 (+0.94) |
表格1:在多个数学基准测试中,SortedRL的两种模式均优于基线。
结论
SortedRL用一种极其优雅和简单的方式,解决了长期困扰LLM强化学习训练的效率瓶颈。它通过在线感知和调度生成长度,不仅将计算“气泡”几乎完全消除,大幅提升了硬件利用率和训练吞吐量,还通过隐式的课程学习机制,实现了更高的样本效率和最终性能。
这项工作证明,有时解决复杂系统问题的答案,可能就隐藏在对问题根源的深刻洞察和一次巧妙的“排序”之中。对于未来想要训练更强推理能力、需要更长思维链的大模型而言,SortedRL无疑提供了一条更高效、更经济的路径。