大模型“瘦身”革命:砍掉99.7%注意力连接,内部电路清晰100倍且性能不降!

大型语言模型(LLM)的能力日益强大,但其内部工作机制却像一个难以捉摸的“黑箱”,这极大地限制了我们对它的信任和进一步优化。如果我们能有一种方法,像做手术一样精确“清理”一个已经训练好的大模型,让它的逻辑变得清晰可见,同时又不损失任何性能,那会怎样?
ArXiv URL:http://arxiv.org/abs/2512.05865v1
来自苏黎世联邦理工学院(ETH Zürich)等顶尖机构的一项新研究,就实现了这个看似不可能的目标。他们提出了一种简单的后训练(post-training)方法,能将Transformer模型中高达99.7%的注意力连接“剪掉”,同时保持原有的性能。
更惊人的是,这种极致的稀疏化让模型内部负责特定任务的“神经电路”变得异常简洁,复杂性降低了近100倍!
为什么大模型如此复杂?
要理解这项研究的突破性,我们得先看看问题的根源。在标准的Transformer模型中,注意力机制是全连接的,每个Token都会与其他所有Token计算注意力分数。
这种设计虽然强大,但也导致了信息的“弥散”。即使是处理一个简单的任务,比如两位数加法,模型也可能学会一种极其复杂的、信息分散的计算方式。
如下图(上)所示,一个普通Transformer在解决加法问题时,注意力模式杂乱无章,我们很难看懂它到底在“想”什么。
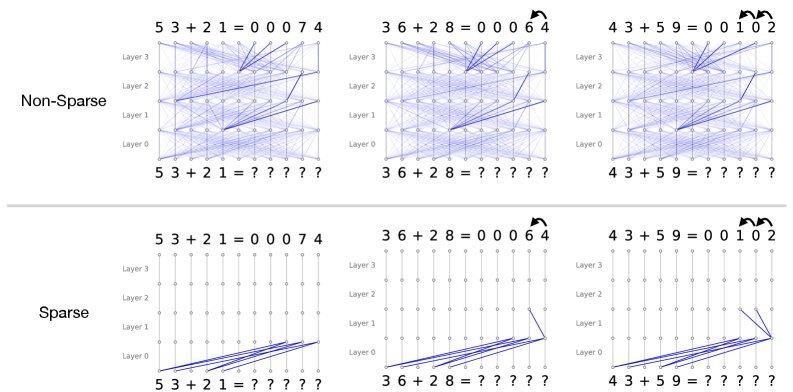
图1:普通模型(上)与稀疏模型(下)在两位数加法任务上的注意力模式对比。稀疏模型(下)的计算逻辑清晰可见:首先对齐要相加的数字,然后在需要时关注进位。
这种复杂性为机制可解释性(Mechanistic Interpretability)——即逆向工程神经网络算法的领域——带来了巨大挑战。而这项新研究的核心思想是:与其费力地解读复杂的模型,不如直接引导模型变得更简单、更具可解释性。
核心方法:约束下的稀疏化手术
研究者提出了一种巧妙的后训练方法,它包含两个关键部分:
1. 稀疏注意力层(Sparse Attention Layer)
该方法对标准的注意力层做了一个小小的改动。在计算注意力权重后,它引入了一个可学习的“门控”矩阵 $A$。这个矩阵的每个元素 $A_{ij}$ 都是通过一个伯努利分布 $Bern(\sigma(q_i^T k_j))$ 采样的二进制值(0或1)。
\[SparseAttention(Q,K,V)=\bigg[A\odot softmax(\frac{QK^{T}}{\sqrt{d_{k}}})\bigg]V\]简单来说,这个门控矩阵就像一个开关网络,它会“硬性地”决定哪些注意力连接是开启的(值为1),哪些是关闭的(值为0)。这相当于一种 $L0$ 正则化,直接减少了连接的数量,而不是像其他方法那样仅仅是降低权重。
2. 约束优化(Constrained Optimisation)
如何确保在变得稀疏的同时,模型性能不下降呢?这就要靠一个精妙的优化策略了。研究者将这个过程设定为一个约束优化问题:
\[\min_{\theta}\sum_{l}\mathbb{E}\big[ \mid A_{l} \mid \big]\qquad s.t.\quad CE\leq\tau\]这里的目标是最小化注意力连接的总数(即 $\sum\mathbb{E}[ \mid A_l \mid ]$),但有一个前提条件:模型的交叉熵损失 $CE$ 必须小于或等于一个预设的阈值 $\tau$(即原始模型的损失水平)。
通过引入拉格朗日乘子 $\lambda$,这个优化问题可以自动平衡“稀疏性”和“性能”。
-
当模型性能很好($CE < \tau$)时,算法会“加大力度”鼓励稀疏,减少更多连接。
-
当模型性能开始下滑($CE > \tau$)时,算法则会“放松要求”,优先保证性能。
这个自适应的过程确保了模型在不牺牲性能的前提下,尽可能地变得稀疏。
实验结果:性能无损,电路锐减
研究团队在GPT-2(1.24亿参数)和LLaMA3-1B(10亿参数)等模型上验证了他们的方法。结果令人振奋。
极致稀疏,性能依旧
如下图所示,经过稀疏化后训练,两个模型的性能(Cross-Entropy Loss)几乎与原始的密集模型持平。
但它们的注意力连接数却急剧下降,平均只有 0.2% 到 0.3% 的连接处于激活状态!
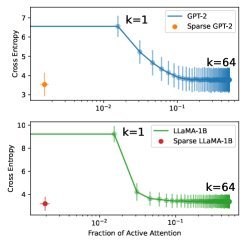
图2:稀疏模型与密集模型在性能和稀疏度上的对比。左图显示,稀疏模型(橙色/绿色实线)在极低的连接比例下保持了与密集模型(蓝色/红色虚线)相当的性能。而简单的Top-k稀疏(蓝色/红色实线)则会导致性能急剧下降。
作为对比,如果简单粗暴地在原始模型上只保留注意力分数最高的Top-k连接(例如Top-1),模型的性能会立刻崩溃。这证明了该研究提出的方法并非简单的筛选,而是在重构模型内部的信息流,使其更高效、更集中。
神经电路清晰百倍
这种局部的注意力稀疏,最终会带来全局“神经电路”的极大简化。
研究者使用了归因补丁(Attribution Patching)等技术来识别对特定任务(如间接宾语识别IOI和大于号判断)至关重要的模型组件(注意力头和MLP)。
他们发现,要解释模型90%的行为:
-
稀疏模型所需的电路连接数,比密集模型少了50到100倍!
-
在全局层面,关键电路的连接数也减少了20到50倍。
这意味着,原本需要数百个组件和成千上万条连接才能完成的任务,现在只需要一个极其紧凑、清晰的子网络就能完成。这对于理解和分析大模型的工作原理,无疑是一次巨大的飞跃。
结论与展望
这项研究为解决大模型“黑箱”问题提供了一个极其强大且实用的新工具。它证明了Transformer模型中的大量计算其实是冗余的,通过简单的后训练“清理”,我们就能在不牺牲性能的前提下,揭示出模型内部更简洁、更模块化的计算结构。
该方法的优势在于其灵活性,它可以作为即插即用的模块应用于任何基于Transformer的架构。未来,我们可以期待这项技术被应用到更大规模的前沿模型上,或许还可以结合LoRA等高效微调技术,进一步降低计算成本。
总而言之,实现可解释性不仅需要更先进的分析技术,也需要从模型设计本身出发。这项工作为我们指明了一个方向:通过引入稀疏性等结构化先验,我们可以构建出天生就更易于理解的AI模型。