SpecAttn: Speculating Sparse Attention
-
ArXiv URL: http://arxiv.org/abs/2510.27641v1
-
作者: Harsh Shah
-
发布机构: Carnegie Mellon University
TL;DR
本文提出了一种名为 SpecAttn 的免训练方法,该方法将推测解码(speculative decoding)与稀疏注意力相结合,通过利用草稿模型(draft model)已计算出的注意力权重来为目标模型(target model)动态预测并选择重要的 Token,从而在不显著牺牲模型性能的前提下,高效实现稀疏注意力并大幅减少键值缓存(Key-Value Cache)的访问。
关键定义
本文主要基于现有的推测解码和稀疏注意力概念,并提出了以下核心技术:
- SpecAttn: 一种新颖的、无需训练的推理加速框架。它巧妙地将在推测解码过程中草稿模型产生的注意力图谱,用于指导更强大的目标模型动态地执行稀疏注意力计算,从而减少计算冗余。
- 层级映射(Layer Mapping): 一种离线匹配机制。通过计算草稿模型与目标模型各层之间注意力分布的 KL 散度(KL divergence)相似度,为目标模型的每一层找到一个注意力模式最相近的草稿模型层。该映射关系在推理时保持固定。
- 免排序 Top-p 核选择(Sorting-Free Top-p Nucleus Selection): 一种高效的 Token 选择算法。该算法利用二分搜索来识别出注意力权重累积概率超过阈值 \(p\) 的最小 Token 集合,避免了传统方法中高开销的排序操作,非常适合在 GPU 上执行。
相关工作
当前大型语言模型(LLM)推理的主要瓶颈在于自注意力机制的二次方复杂度。现有优化方案可分为两类:
- 系统级优化: 如 vLLM、FlashAttention 等,通过优化的核函数、内存管理和批处理技术来加速计算,但它们仍然执行完整的稠密注意力计算,当序列变长时,延迟问题依然严峻。
- 算法级优化:
- 静态稀疏注意力: 如 Longformer、BigBird,它们采用预设的、与输入内容无关的稀疏模式(如滑动窗口、全局 Token),虽然降低了复杂度,但需要重新训练模型,且模式固定,无法适应不同输入的动态需求。
- 动态稀疏注意力: 如 MInference、Quest 等,它们在推理时根据内容动态剪枝,但通常依赖预定义的头模式或引入额外的预测开销。
同时,推测解码作为一种独立的加速技术,通过小模型生成草稿、大模型验证的方式减少了大模型的调用次数,但并未改变大模型内部的注意力计算成本。
本文旨在解决的问题是:如何将推测解码的免训练优势与稀疏注意力的计算效率相结合,创建一个完全动态的、内容感知的、且无需重新训练的稀疏注意力机制。SpecAttn 通过利用推测解码过程中已有的计算结果(草稿模型的注意力权重),填补了这一空白。
本文方法
SpecAttn 框架的核心思想是利用轻量级草稿模型 ($M_d$) 的注意力模式来近似预测大型验证模型 ($M_v$) 的重要 Token,从而指导 $M_v$ 进行稀疏注意力计算。
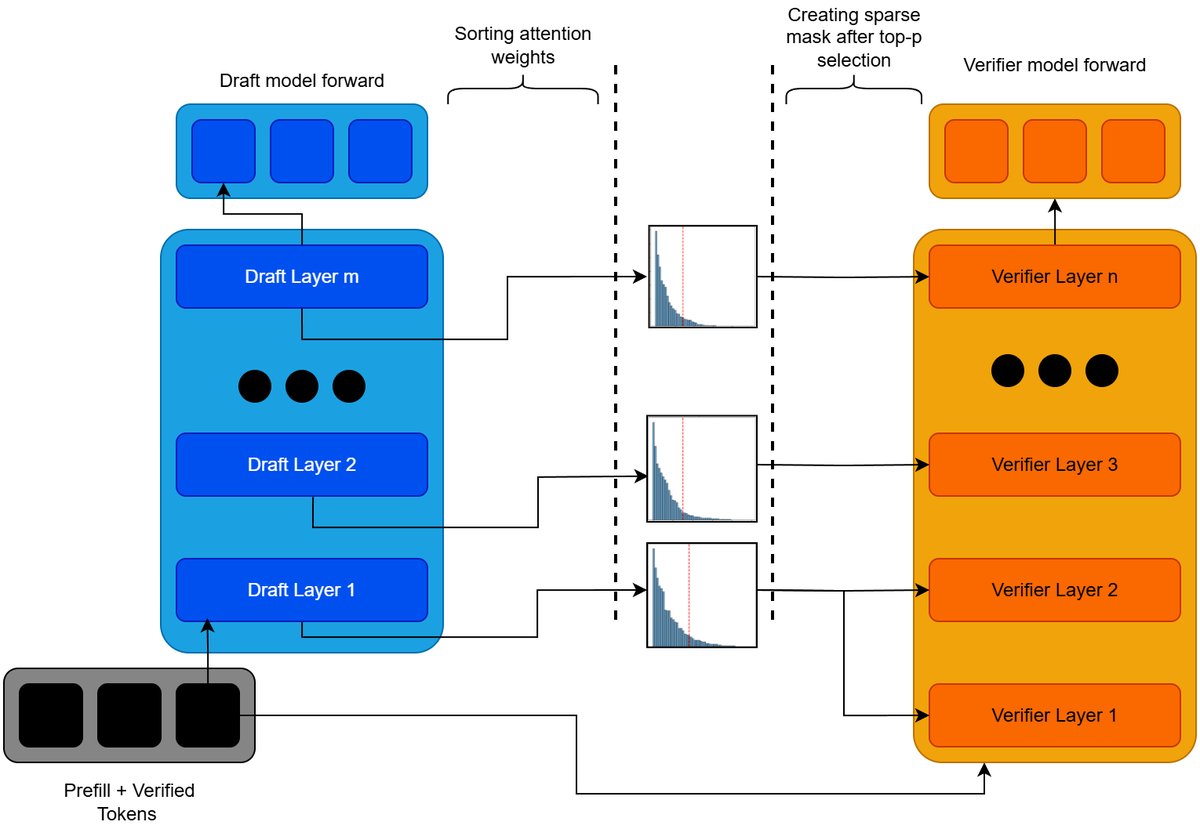
该框架主要包含三个步骤:
层级映射
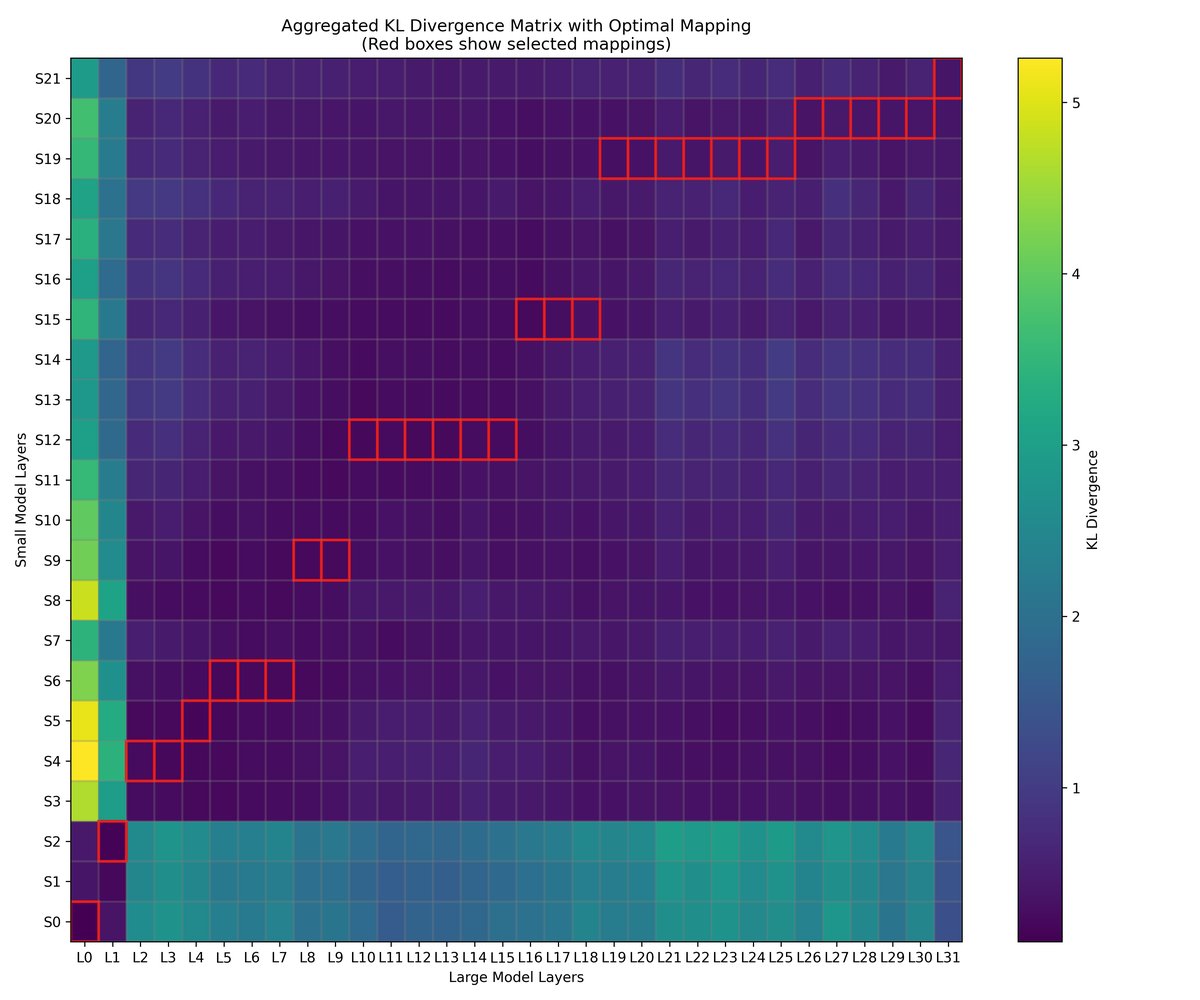
由于草稿模型和验证模型的层数和结构可能不同,需要建立两者层级之间的对应关系。本文提出一种基于 KL 散度的离线匹配方法。 对于验证模型的第 $j$ 层和草稿模型的第 $i$ 层,其注意力分布分别为 $A^{v}_{j}$ 和 $A^{d}_{i}$。两者间的相似度定义为:
\[S_{i,j}=-D_{KL}(A^{v}_{j} \mid \mid A^{d}_{i})=-\sum_{k=1}^{L}A^{v}_{j}[k]\log\frac{A^{v}_{j}[k]}{A^{d}_{i}[k]}\]对于验证模型的每一层,选择一个能使其相似度最大化的草稿模型层作为映射。为了保证层级对应关系的合理性,映射过程遵循单调递增的原则,即验证模型的较深层只能映射到草稿模型的较深或同一层。该问题可通过动态规划有效解决。
免排序 Top-p 核选择
在确定了层级映射后,利用草稿模型对应层的注意力分布来为验证模型选择要关注的 Token。传统 Top-p 选择需要对权重进行排序,在 GPU 上开销较大。本文采用了一种免排序的算法,其本质是一个二分搜索过程,寻找一个最小的注意力阈值 $\theta_{mid}$,使得所有注意力得分高于该阈值的 Token 的注意力权重之和大于等于总注意力权重的 \(p\) 倍。 具体来说,对于验证模型的每一层 $j$,从其映射的草稿模型层 $f(j)$ 中提取注意力权重,然后通过该算法找到一个 Token 子集 $\mathcal{T}_j$,满足:
\[\sum_{k\in\mathcal{T}_{j}}a_{f(j),k}\geq p\]其中 $p$ 是一个预设的阈值(如 $p=0.95$),用于平衡计算效率和模型性能。这个过程确保了只关注最重要的 Token,从而实现了动态的内容感知剪枝。
稀疏注意力计算
确定了需要关注的 Token 集合后,本文将生成的稀疏掩码(mask)转换为压缩稀疏行(Compressed Sparse Row, CSR)格式,并调用 Flashinfer 库中的稀疏注意力核函数来执行计算。这只会在选定的键值对之间进行注意力计算,从而大幅减少了计算量和内存访问。
实验结论
实验使用 Llama-2-7B 作为验证模型,Llama-2-70M 作为草稿模型,在单个 NVIDIA RTX 4090 GPU 上进行。
- 模型质量(Perplexity): 在 PG-19 数据集上,与其他稀疏注意力方法相比,SpecAttn 在相似的稀疏度下表现出色。当 \(p=0.95\) 时,SpecAttn 减少了 78.4% 的 KV 缓存读取,而困惑度(Perplexity)仅相对增加了 15.29%,显著优于 Quest 等方法。
| 方法 | Perplexity | Perp. 差异 | 相对增加 | KV 减少 |
|---|---|---|---|---|
| 全注意力 | 6.435 | - | - | - |
| Quest (Top 32 chunks) | 186.242 | +179.807 | +2794.32% | 77.4% |
| Quest (Top 64 chunks) | 7.823 | +1.389 | +21.58% | 77.4% |
| SpecAttn (p=0.95) | 7.419 | +0.984 | +15.29% | 78.4% |
| SpecAttn (p=0.97) | 6.720 | +0.285 | +4.43% | 68.8% |
| SpecAttn (p=0.99) | 6.467 | +0.032 | +0.50% | 44.3% |
- 计算加速:
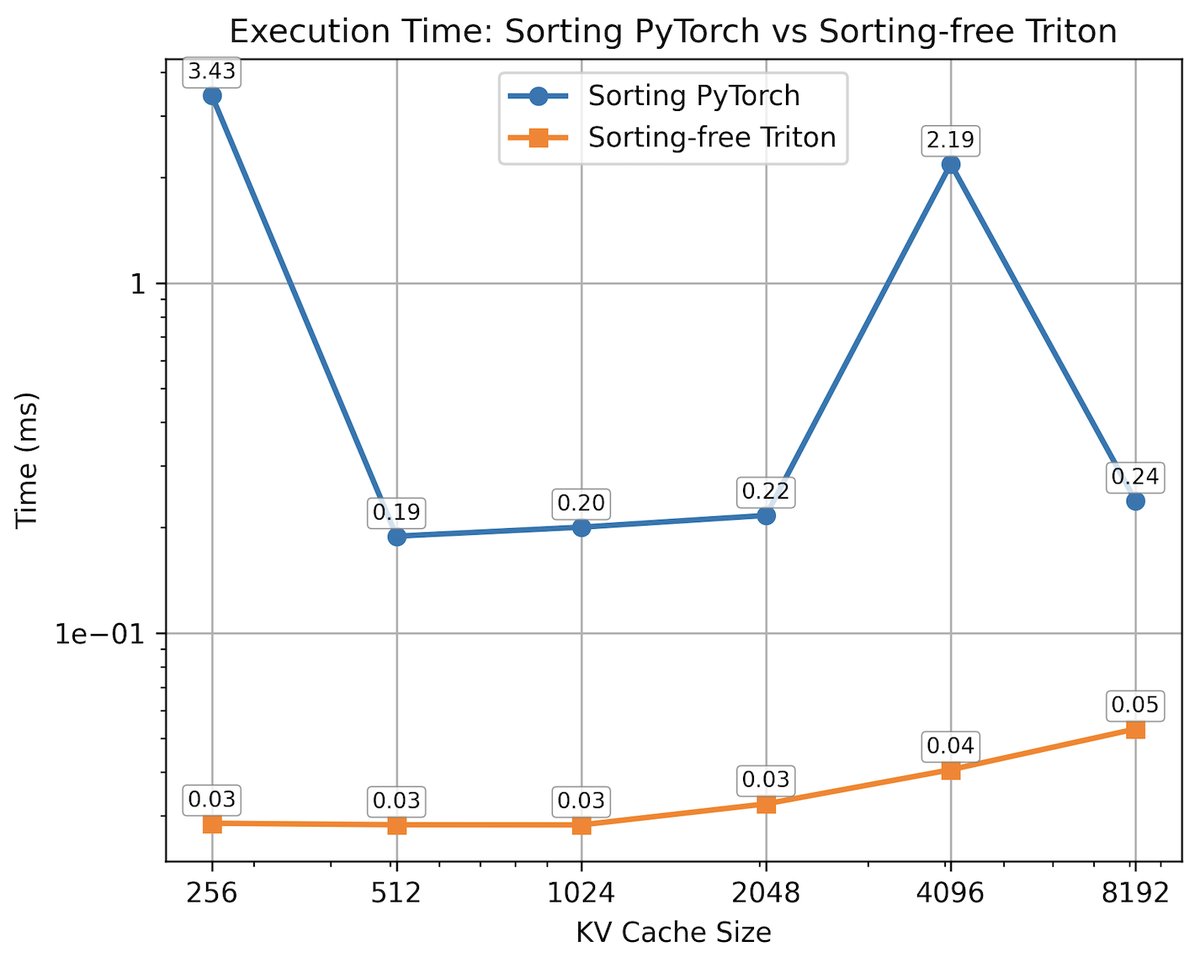
- 掩码生成: 免排序的 Triton 核函数相比基于 PyTorch 排序的实现,在掩码生成阶段获得了至少 4 倍的加速。
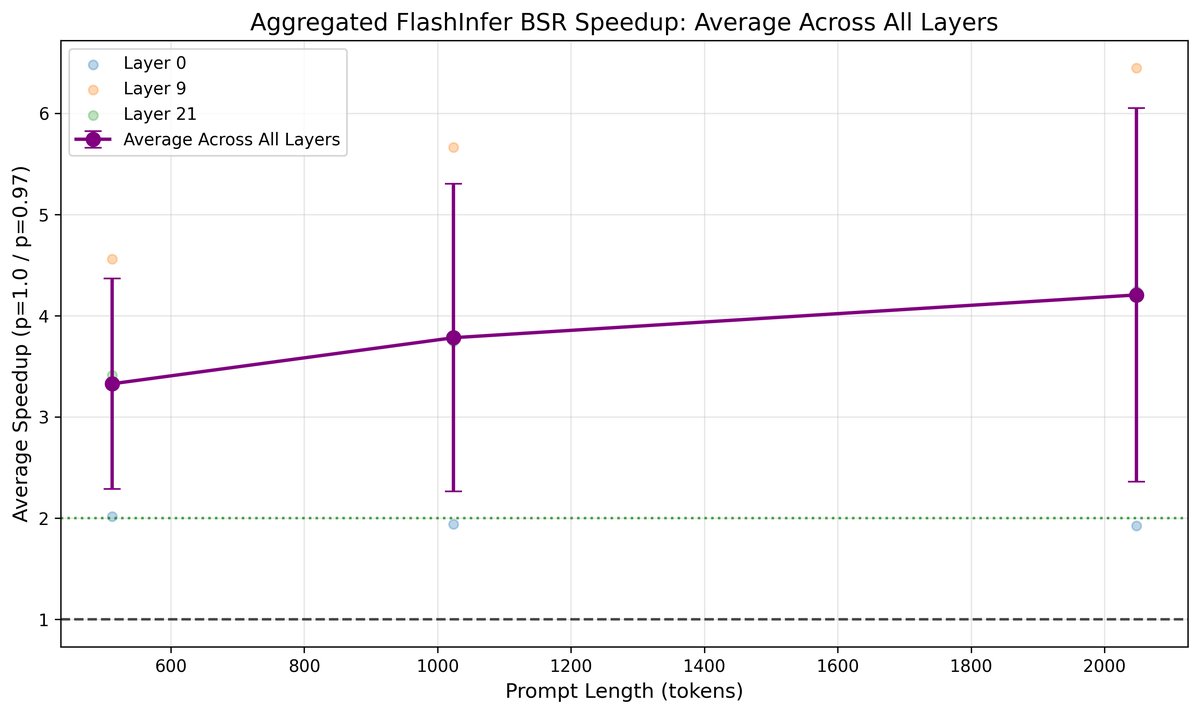
- 注意力计算: 随着上下文长度增加,稀疏注意力的加速效果越发明显。在上下文长度为 2048 时,\(p=0.97\) 的 SpecAttn 相比全注意力计算获得了超过 4 倍的加速。
- 端到端吞吐量: 在当前实验设置下,SpecAttn 的端到端延迟略高于使用全注意力的推测解码。这主要是因为掩码生成过程引入了额外开销。然而,从注意力计算的加速趋势看,随着上下文长度进一步增加,注意力计算节省的时间将有望补偿并超过掩码生成的开销,从而实现端到端的净收益。
| 方法 | Tokens/秒 ($\uparrow$) | KV 减少 ($\uparrow$) |
|---|---|---|
| 无推测解码 (flashattn) | 42.00 | - |
| 推测解码 (全注意力) | 64.95 | - |
| SpecAttn (p=0.97) | 59.95 | 68.8% |
- 最终结论: 本文成功证明了 SpecAttn 框架的可行性与有效性。它通过一种免训练、内容感知的方式,显著减少了 LLM 推理中的 KV 缓存访问和注意力计算量,同时将对模型生成质量的影响控制在可接受范围内,为长上下文场景下的 LLM 高效推理提供了一个极具前景的方向。