Statistical Reinforcement Learning in the Real World: A Survey of Challenges and Future Directions
RL不该只会打游戏:哈佛联合帝国理工发布“现实世界落地”三步走指南

当DeepMind的AI在围棋盘上碾压人类,或者在《GT赛车》中跑出超人类的圈速时,我们很容易产生一种错觉:强化学习(RL)已经无所不能了。但当你转过头,试图将同样的算法应用到医疗健康、在线教育或公共政策时,现实往往会给你一记响亮的耳光。
ArXiv URL:http://arxiv.org/abs/2601.15353v1
为什么在模拟器里大杀四方的RL,一到现实世界就“水土不服”?
哈佛大学、帝国理工学院等顶尖机构的研究团队联合发布了一篇重磅综述,直击这一痛点。他们指出,现实世界缺乏完美的模拟器,且环境时刻在变,这导致了RL落地的巨大鸿沟。为了填补这一空白,论文提出了一套全新的“统计强化学习”框架,将RL的落地拆解为三个关键阶段。
游戏与现实的“巨大鸿沟”
在深入技术细节之前,我们需要明白为什么现实世界的决策如此困难。
在游戏或模拟器中,Agent(智能体)可以试错无数次——撞车了可以重开,输了可以重来。但在现实中,数据是昂贵的,甚至是危险的。医生不能为了探索最佳治疗方案而随意给病人尝试高风险药物;自动驾驶汽车也不能为了学习避障而在真实道路上碰撞。
论文犀利地指出了阻碍RL落地的两大核心挑战:
-
有限的交互机会:由于伦理、成本或时间限制,Agent无法像在游戏中那样进行海量的探索。
-
环境的剧烈变化:游戏规则通常是固定的,但现实世界是动态的。社会趋势、用户习惯、甚至医疗技术都在不断演变,昨天训练好的模型,明天可能就失效了。
为了解决这些问题,作者们不再将RL视为一个单纯的“训练-部署”过程,而是提出了一个包含部署内(Online)、部署间(Offline)和持续改进的闭环系统。
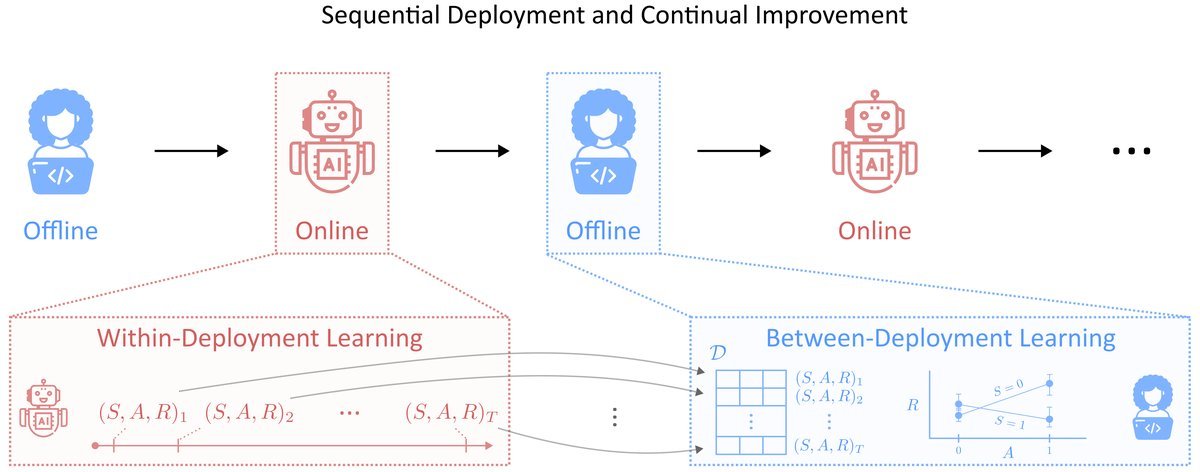
核心框架:RL落地的“三步走”战略
如上图所示,这篇论文将RL的现实应用构建为一个循环往复的生命周期:
-
部署内的在线学习(Online Learning):系统上线后,如何在保证安全和性能的前提下,利用有限的数据进行实时优化?
-
部署间的离线分析(Offline Analyses):在两次部署的间隙,如何利用已有的历史数据进行统计推断,为下一次迭代做准备?
-
持续的部署-再部署循环(Continual Improvement):如何设计一连串的部署计划,使得系统能够适应不断变化的环境,实现长期的性能提升?
这听起来很像软件工程的DevOps,但在RL语境下,每一步都充满了统计学的挑战。
关键技术一:在“数据饥渴”中寻找平衡
在部署阶段,最大的敌人是数据稀缺。当数据量不足时,复杂的深度RL模型往往表现极差,甚至不如简单的规则。
这就引出了统计学中经典的偏差-方差权衡(Bias-Variance Tradeoff)。在数据有限的早期阶段,我们可能需要故意引入一些“偏差”——比如使用更简单的模型、引入正则化,或者利用先验知识来限制Agent的探索范围。虽然这限制了模型的上限,但能极大地降低“方差”,避免Agent做出离谱的决策。
论文还提到了一个非常前沿的方向:利用大语言模型(LLMs)进行辅助。
LLM拥有海量的通识知识,可以作为RL Agent的“大脑”或“热启动”工具。在医疗干预或教育对话中,LLM可以利用其上下文理解能力,在没有足够RL训练数据的情况下,先提供一个“还不错”的基准策略,或者帮助Agent理解非结构化的文本数据(如病历、学生提问)。这相当于让RL Agent不再是“白板”出生,而是带着常识上路。
关键技术二:自适应实验与干预
为了让RL真正服务于人,论文详细探讨了两种应用场景:
-
自适应实验(Adaptive Experiments):这类似于升级版的A/B测试。比如在在线教育中,系统不是固定地将学生分配到不同的教学组,而是根据实时的反馈,动态调整分配概率,让更多的学生尽快享受到更有效的教学方法。
-
自适应干预(Adaptive Interventions):这更进了一步,比如适时自适应干预(JITAIs)。在数字健康领域,系统需要决定何时给用户发送运动提醒。这不仅仅是一次性的分配,而是一个连续的决策序列。每一个决策都会影响用户的下一个状态(比如心情、心率),这正是RL最擅长的序列决策问题。
结语:从“算法”到“系统”
这篇综述最大的价值在于,它将强化学习从纯粹的“算法竞赛”拉回了“系统工程”的视角。
在现实世界中,我们不仅需要一个能跑高分的算法,更需要一套能够处理数据稀缺、适应环境变化、并且能通过“在线-离线”循环不断进化的统计学框架。对于致力于将AI技术落地的工程师和研究者来说,理解这种统计强化学习(Statistical RL)的思维模式,或许比单纯追求SOTA模型更为关键。
RL的未来,不在于在模拟器里跑得有多快,而在于能否在充满不确定性的现实世界中,稳健地走出每一步。