Step-DeepResearch Technical Report
32B模型媲美OpenAI?Step-DeepResearch揭秘:低成本实现专家级深度研究

在大模型向自主智能体(Autonomous Agents)演进的浪潮中,我们经常混淆两个概念:“搜索”与“研究”。搜索通常是针对明确问题的单次查询,而深度研究(Deep Research)则是一个漫长的迭代过程——它需要意图识别、长程规划、跨源验证以及撰写结构化的报告。
ArXiv URL:http://arxiv.org/abs/2512.20491v2
目前的学术基准(如 BrowseComp)往往只关注多跳问答,这导致许多 Agent 实际上更像是一个高效的“网络爬虫”,而非真正的“研究员”。为了填补这一空白,StepFun(阶跃星辰)团队发布了 Step-DeepResearch 技术报告。这项研究最令人兴奋的点在于:它证明了通过精细的数据合成策略和训练流程,一个仅有 32B 参数的中等规模模型,不仅能在中文领域填补评估空白,更能在成本极低的情况下,在深度研究能力上媲美 OpenAI o3-mini 和 Gemini 1.5 Pro 等顶尖闭源模型。
本文将深入解读 Step-DeepResearch 背后的核心技术:它是如何通过“原子能力”构建数据,以及如何通过三阶段训练实现以小博大的。
搜索 $\neq$ 研究:重新定义核心挑战
为什么现有的 Agent 在处理开放式研究任务时表现不佳?核心原因在于任务定义的错位。
传统的评估往往将 Agent 视为一个问答机器,优化的目标是检索的准确率。然而,真实的深度研究(Deep Research)是一个长程决策过程。Step-DeepResearch 将这一过程解构为一组原子能力(Atomic Capabilities):
-
自适应规划(Adaptive Planning):将模糊需求拆解为子任务。
-
深度信息搜寻(Deep Information Seeking):在信息不完整时进行主动拓扑探索。
-
反思与验证(Reflection & Verification):自我纠错,交叉验证多源信息。
-
报告撰写(Reporting):将碎片化信息综合为逻辑严密的论证。
基于这一视角,该研究并未依赖复杂的多智能体编排,而是采用了一种流线型的 ReAct 式单智能体设计,通过端到端的训练将这些能力“内化”到模型中。
数据策略:逆向工程与原子能力合成
Step-DeepResearch 的核心竞争力在于其独特的数据合成策略。为了解决预训练与任务特定决策之间的差距,研究团队没有孤立地构建数据集,而是围绕上述四个原子能力建立了专门的合成流水线。
1. 规划能力的“逆向工程”
如何教模型学会像专家一样规划?研究团队采用了一种巧妙的逆向工程(Reverse Engineering)策略。
他们收集了大量高质量的行业报告、学术综述等文档——这些文档本质上是复杂研究任务的“最终产物”。通过分析这些文档的结构,模型可以反向推导出隐含的规划逻辑。为了保证质量,团队还引入了轨迹一致性过滤,确保模型学习到的执行过程严格符合“后见之明”的完美规划。
2. 基于图谱的深度搜寻
为了增强多跳推理能力,研究者利用 Wikidata5m 和 CN-DBpedia 等知识图谱进行受控子图采样。
有趣的是,他们并没有直接使用原本的三元组生成问题(因为图谱可能过时),而是将三元组作为查询词进行二次搜索验证。基于验证后的信息,Prompt LLM 生成需要多跳搜索的复杂问题 $\langle\text{Query},\text{Answer}\rangle$。此外,还引入了 QwQ-32b 作为难度过滤器:如果一个问题能被 QwQ-32b 直接解决,就被视为“简单问题”剔除,确保训练数据的高难度。
3. 闭环反思与验证
为了让模型学会“自我纠错”,研究团队设计了一个“专家模型生成 $\rightarrow$ 结果验证 $\rightarrow$ 多轮反思”的闭环流程。
特别是对于验证环节,他们构建了一个包含验证点提取、证据搜索、逻辑比对的 Multi-Agent 教师工作流,生成数千条 $\langle\text{paragraph},\text{judge-result}\rangle$ 样本。这让模型学会了像人类专家一样,不仅看结论,还要检查结论与证据的逻辑自洽性。
训练流水线:从 Mid-training 到 RL 的进阶之路
Step-DeepResearch 选择 Qwen2.5-32B-Base 作为基座模型,采用了一个渐进式的三阶段训练范式。
第一阶段:Agentic Mid-training(能力注入)
这一阶段介于预训练和微调之间,目的是注入原子能力并适应长上下文。
-
32K Context: 重点注入规划、反思等原子能力。
-
128K Context: 进一步扩展上下文,专注于真实世界的复杂任务,如网页交互和多工具协同。
通过约 150B tokens 的训练,模型在 SimpleQA 和 FRAMES 等基准上的表现稳步提升。
第二阶段:SFT(能力组合)
在 SFT 阶段,重点从单一能力的教学转向端到端的任务执行。数据涵盖了从意图理解到报告生成的全链路轨迹。
值得注意的是,为了满足专业研究的严谨性,SFT 数据中显式加入了 \(\cite{}\) 引用格式约束,强制模型在生成报告时必须有据可查。
第三阶段:强化学习(RL)与 Checklist 判卷
为了突破模仿学习的局限,RL 阶段引入了基于规则(Rubric-based)的奖励模型。
由于高质量的 Deep Research 判卷很难获取,团队采用了一种“两步逆向合成”法生成任务和对应的评分标准。通过 RL,模型在主动规划、反思和跨源验证方面的能力得到了显著增强,学会了如何在复杂的真实环境中进行权衡和决策。
实验结果:以小博大的典范
为了验证效果,研究团队不仅在 Scale AI 的 ResearchRubrics 上进行了测试,还专门构建了针对中文领域的 ADR-Bench。
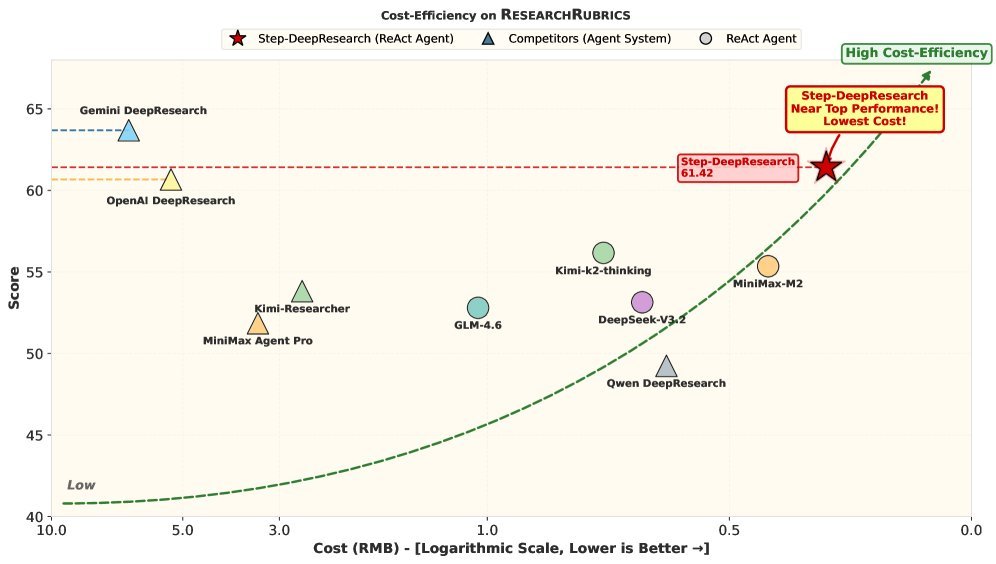
从上图(Figure 1)可以看出 Step-DeepResearch 的强悍表现:
-
性价比之王:在 ResearchRubrics 上,Step-DeepResearch (32B) 取得了 61.42 的高分,这一成绩与 OpenAI DeepResearch 和 Gemini DeepResearch 处于同一梯队,但其推理成本(RMB)却大幅降低,位于图表左上角的“高效前沿面”。
-
中文领域统治力:在 ADR-Bench 的专家评估中(图 b),Step-DeepResearch 在所有维度上的 Elo 评分均领先于同类模型,甚至超越了 Kimi-Researcher 和 MiniMax Agent Pro 等系统。
总结
Step-DeepResearch 的成功向我们展示了一条清晰的技术路径:中等规模模型完全可以通过精细化的数据工程和训练策略,获得专家级的深度研究能力。
它没有盲目追求参数规模,而是回归到研究的本质——规划、搜寻、验证与表达。通过构建原子能力数据和渐进式训练,Step-DeepResearch 不仅打破了“搜索即研究”的迷思,也为行业提供了一个极具性价比的 Deep Research Agent 范本。对于希望在垂直领域部署低成本、高性能 Agent 的开发者而言,这篇技术报告无疑具有极高的参考价值。