告别LayerNorm?CMU提出Derf:仅用简单函数,多模态性能全面超越
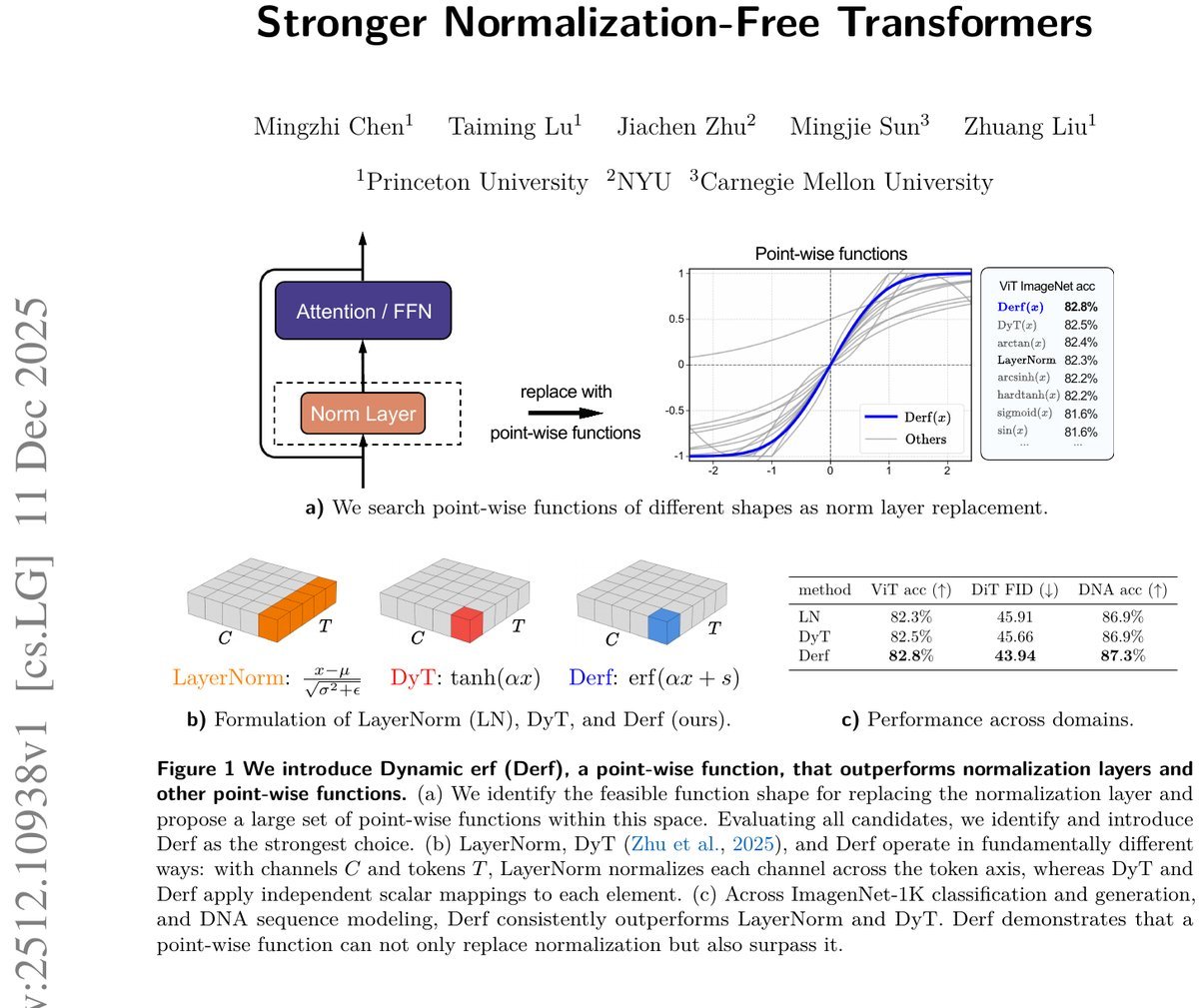
在深度学习的殿堂里,归一化层(Normalization Layers)如 LayerNorm 和 RMSNorm 长期以来被视为不可或缺的“承重墙”。它们通过调整激活值的分布,稳定了训练过程,加速了模型收敛。
ArXiv URL:http://arxiv.org/abs/2512.10938v1
然而,这堵墙真的坚不可摧吗?
来自卡内基梅隆大学(CMU)、纽约大学和普林斯顿大学的研究团队给出了否定的答案。继之前的 Dynamic Tanh (DyT) 之后,他们通过大规模搜索,发现了一种名为 Derf 的简单点对点函数。令人惊讶的是,这个简单的函数不仅能完全替代复杂的归一化层,还在视觉、语音、DNA序列建模等多个领域的任务中,性能全面超越了 LayerNorm、RMSNorm 和 DyT。
这是否意味着,我们即将迎来一个“无归一化”(Normalization-Free)的 Transformer 新时代?
寻找完美的替代者:从 DyT 到 Derf
归一化层虽然好用,但它依赖于统计数据的计算(如均值和方差)。为了摆脱这种依赖,之前的研究提出了 DyT(Dynamic Tanh),利用 $\tanh$ 函数的饱和特性来模拟归一化的效果。
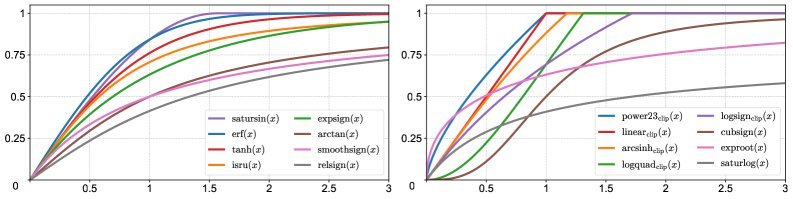
但 DyT 就是终点吗?研究人员并不满足。他们决定通过大规模搜索,寻找一个更完美的函数设计。
为了指导这次搜索,研究团队首先深入剖析了点对点函数(Point-wise functions)影响训练稳定性的四个核心属性:
-
零中心性(Zero-centeredness):输出应围绕零点分布。实验表明,偏离零点过大会导致训练发散。
-
有界性(Boundedness):函数输出必须限制在一定范围内。无界函数(如线性函数)容易导致信号爆炸。
-
中心敏感性(Center Sensitivity):函数在零点附近必须对输入变化敏感。因为大多数激活值集中在零附近,如果此处梯度平坦,信号将无法有效传播。
-
单调性(Monotonicity):保持输入输出的相对顺序,避免梯度符号翻转。
基于这四大原则,研究人员对大量候选函数进行了筛选和测试。
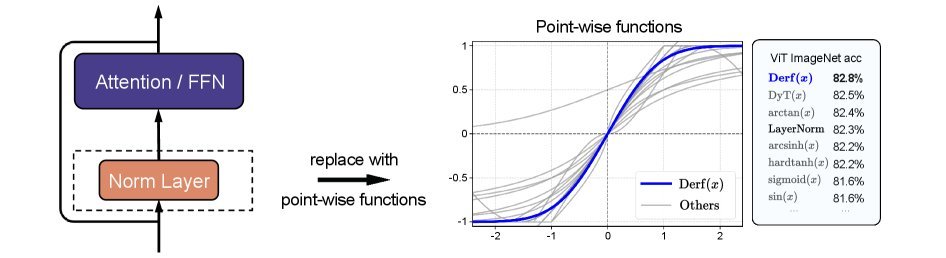
冠军诞生:Derf 的数学之美
在众多的候选者中,基于高斯误差函数(Error Function, erf)的设计脱颖而出。研究人员将其命名为 Derf(Dynamic erf)。
其数学形式非常简洁:
\[\mathrm{Derf}(x)=\gamma\,\mathrm{erf}(\alpha x+s)+\beta\]其中:
-
$\mathrm{erf}(x)$ 是重缩放的高斯累积分布函数。
-
$\alpha$ 是可学习的缩放参数。
-
$s$ 是可学习的位移参数。
-
$\gamma$ 和 $\beta$ 则是类似于传统归一化层中的仿射参数。
与 LayerNorm 需要计算当前输入的统计量不同,Derf 仅仅是一个带有可学习参数的固定映射,计算效率更高,且完全独立于 Batch 或 Token 的统计信息。

实验结果:全方位的胜利
Derf 的表现究竟如何?研究团队在视觉、生成模型、语音和基因组学等多个领域的标准基准上进行了严苛的测试。结果显示,Derf 几乎实现了“降维打击”。
-
视觉识别 (ViT):在 ImageNet-1K 任务上,使用 Derf 的 ViT-Base 模型比 LayerNorm 版本高出 0.5% 的 Top-1 准确率,比 DyT 高出 0.2%。
-
图像生成 (DiT):在扩散模型 DiT 中,Derf 显著降低了 FID 分数(越低越好),生成质量明显优于 LayerNorm 和 DyT。
-
语音与DNA建模:在 wav2vec 2.0 和 HyenaDNA 等模型中,Derf 同样展现出了更低的验证损失和更高的准确率。
深度洞察:是拟合得更好,还是泛化得更强?
Derf 为什么能赢?这是一个非常有趣的问题。
直觉上,我们可能会认为 Derf 具有更强的拟合能力,能让模型在训练集上表现得更好。然而,研究人员通过计算“评估模式下的训练损失”发现了一个反直觉的现象:
Derf 的训练损失实际上比 LayerNorm 要高!
这意味着,Derf 并没有让模型死记硬背训练数据。相反,它的优势在于更强的泛化能力(Stronger Generalization)。Derf 就像一个优秀的正则化器,它限制了模型的过拟合倾向,从而在测试集和验证集上取得了更好的成绩。
总结
这篇论文不仅提出了一个性能优越的新算子 Derf,更重要的是,它系统性地揭示了无归一化架构设计的核心原则。
Derf 的成功证明了,复杂的归一化统计量并非深度学习的必需品。通过精心设计的点对点函数,我们完全可以在保持甚至提升性能的同时,简化模型架构。对于追求极致性能和架构简洁性的开发者来说,Derf 无疑是一个值得尝试的“新武器”。