Structured Hints for Sample-Efficient Lean Theorem Proving
DeepSeek-Prover潜力释放:仅需简单“骨架”提示,性能飙升43%

在AI数学定理证明的赛道上,大家似乎陷入了一种“暴力美学”的军备竞赛:更强的强化学习(Reinforcement Learning, RL)、更庞大的搜索树、成千上万次的采样($k=1024$ 甚至更多)。
ArXiv URL:http://arxiv.org/abs/2601.16172v1
但麻省理工学院(MIT)的一项最新研究提出了一个反直觉的问题:如果不拼算力,而是给模型一点点“结构化”的提示,会发生什么?
答案令人惊讶。研究人员发现,仅仅通过在推理阶段引入简单的“策略骨架”(Tactic Skeletons),就能让顶尖模型 DeepSeek-Prover-V1.5 在极低计算预算下($k=16$),将相对性能提升 43%。
这不仅是性能的飞跃,更是对当前“大力出奇迹”范式的一次精彩反击。
昂贵的“迷茫”:RL模型的软肋
目前的神经定理证明器(Neural Theorem Provers),如 DeepSeek-Prover-V1.5 或 AlphaGeometry,虽然在形式化证明(如 Lean 语言)上取得了惊人的成绩,但它们依然很“脆”。
很多时候,模型并不是因为不懂数学原理而失败,而是倒在了“起跑线”上:
-
生成了无效的语法;
-
幻觉出了不存在的变量;
-
或者在证明空间的迷宫里彻底“迷路”。
即使经过了大规模的强化学习训练,模型依然缺乏一种对证明结构的“直觉”。目前的普遍做法是通过海量采样(比如尝试1024次)来碰运气,但这在资源受限的场景下极其昂贵。
那么,有没有一种方法,既不需要重新训练模型,也不需要燃烧显卡进行暴力搜索,就能解决这个问题?
简单即有效:结构化中间表示
MIT的研究团队提出了一种轻量级的干预手段:结构化中间表示(Structured Intermediate Representation, IR)。
原理非常简单,与其让模型面对一个定理从零开始“瞎猜”,不如强制它按照某种固定的“套路”开局。研究人员定义了一组 15个常用的策略骨架(Tactic Skeletons)。
这些骨架就像是老师给学生的解题提示:
-
“先试试归纳法(induction)”
-
“先试试分类讨论(cases)”
-
“先试试反证法(by_contra)”
在推理时,系统不再是随机采样,而是按照一个固定的时间表,轮流用这15种骨架作为前缀去“引导”模型生成证明。
这一过程可以用公式表示为 $P_{\theta}(y \mid x, s)$,其中 $x$ 是定理,$s$ 就是强制植入的策略骨架。这相当于在推理开始前,就帮模型“锁定”了一个高层级的证明策略,大大缩小了搜索空间。
实验结果:低成本下的性能飞跃
为了验证这种方法的有效性,研究人员在 miniF2F-test 基准上进行了测试。
关键在于,这次测试有着极其严格的“穷人版”限制:
-
采样次数极少:每个定理只允许尝试 $k=16$ 次(通常SOTA模型会用到上千次)。
-
长度限制:最大生成长度限制在 1024 个 Token。
结果显示,这种简单的“骨架引导”带来了立竿见影的效果:
-
通过率暴涨:基线模型的通过率为 15.16%,而加上结构化提示后,通过率跃升至 21.72%。相对提升幅度达到了惊人的 43.2%。
-
绝对优势:在成对比较中,结构化方法解出了19道基线模型解不出的题,而反之只有3道。这说明该方法不是在做“拆东墙补西墙”的权衡,而是实打实的全面提升。
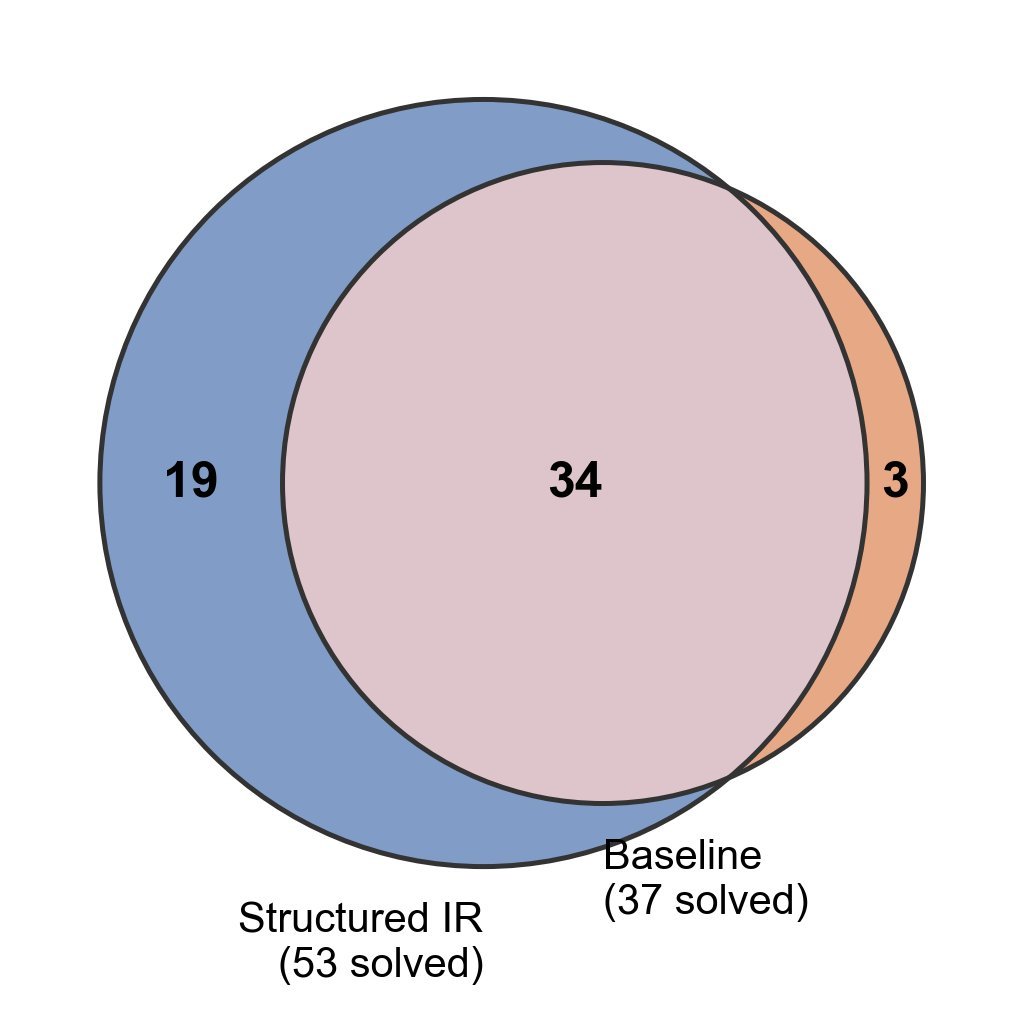
图1:成对分析显示,结构化提示(Structured IR)在解决独特问题上具有压倒性优势(19 vs 3)。
为什么有效?赢在起跑线
研究人员进一步分析了失败案例的错误日志,发现了一个有趣的现象:结构化方法并没有改变错误的类型分布。
换句话说,当模型失败时,它犯的错(如语法错误、类型不匹配)和基线模型是一样的。
这揭示了性能提升的真正原因:更高的“命中率”。
通过强制模型使用有效的策略骨架(如 \(induction\) 或 \(cases\))作为开局,相当于给模型提供了一个“热启动”(Warm Start)。这避免了模型在证明的一开始就走入死胡同。只要骨架选对了,模型凭借其本身强大的补全能力,就能顺势完成证明。
总结与启示
这项研究给AI社区带来了一个重要的启示:在追求模型规模和算力堆叠的同时,不要忽视了先验知识(Priors)的力量。
即使是经过最强RL训练的模型,在面对复杂的推理任务时,依然可能因为缺乏结构化引导而“不知所措”。通过在推理阶段引入廉价的、基于规则的简单引导(如本文的15个策略骨架),我们可以在不增加任何训练成本的前提下,显著释放模型的潜力。
对于那些显卡资源有限,无法进行大规模 $k=1024$ 搜索的研究者和开发者来说,这种“四两拨千斤”的技术路线,无疑极具吸引力。