性能媲美XGBoost,解释性堪比Lasso:斯坦福新作“注意力Lasso”详解

在机器学习领域,我们长期面临一个两难的选择:是选择像 Lasso 这样简单、透明但往往欠拟合的线性模型,还是选择像 XGBoost 或神经网络这样性能强大但如同“黑盒”般的复杂模型?
ArXiv URL:http://arxiv.org/abs/2512.09912v1
如果我告诉你,我们可以鱼与熊掌兼得呢?
斯坦福大学和密歇根大学的研究团队最近提出了一种名为 Supervised learning pays attention 的新方法。他们巧妙地将大语言模型(LLM)中核心的“注意力机制”和“上下文学习”思想,移植到了传统的表格数据监督学习中。
这项技术的核心成果——Attention Lasso,不仅在预测精度上经常超越传统 Lasso 并逼近 XGBoost,更重要的是,它保留了极致的可解释性:它能告诉你,对于每一个具体的预测,哪些训练数据最重要,哪些特征起了决定性作用。
告别“一刀切”:为什么我们需要注意力?
传统的线性模型(如 Lasso)通常假设整个数据集都遵循同一套规律(即只有一组回归系数 $\beta$)。但在现实世界中,数据往往是异质的(Heterogeneous)。
看下面这张图,数据明显分为两个子群,如果强行用一条直线(Lasso)去拟合,结果就是对两个群体的“平均”,导致预测偏差。

通常我们会想到聚类或使用非线性模型(如树模型),但前者需要预先指定簇的数量,后者则牺牲了解释性。
Attention Lasso 的思路非常直观:既然每个测试样本都是独特的,为什么不为它量身定制一个模型呢?
这听起来很像大语言模型的 上下文学习(In-Context Learning, ICL):模型根据当前的输入(Query),在上下文中关注相关的示例,从而做出回答。Attention Lasso 正是把这种思想引入了回归任务。
核心机制:如何为表格数据加“注意力”?
Attention Lasso 的工作流程可以概括为三个步骤:计算注意力权重、拟合局部模型、与全局模型融合。
1. 计算监督注意力权重 (Supervised Attention Weights)
这是该方法最精髓的部分。对于一个新的测试点 $\mathbf{x}^*$,我们需要知道训练集中哪些样本 $\mathbf{x}_i$ 与它最“相似”。
传统的核回归(Kernel Regression)使用欧氏距离来衡量相似度,但这往往忽略了特征与目标变量 $y$ 之间的关系。Attention Lasso 使用了一种监督相似度。
具体来说,它通常利用随机森林(Random Forest)生成的邻近度矩阵来定义相似性。只有当两个样本在预测 $y$ 时共享有用的特征和交互作用时,它们才被认为是相似的。这使得权重 $\mathbf{w}^*$ 能够真正反映数据与其结果之间的内在联系。
2. 拟合“私人定制”的局部模型
一旦有了针对测试点 $\mathbf{x}^*$ 的权重 $\mathbf{w}^*$,算法就会基于这些权重对训练数据进行加权,然后拟合一个局部的 Lasso 模型。
这意味着,对于每一个测试点,我们都得到了一组独特的回归系数 $\hat{\beta}^*$。
3. 全局与局部的融合
为了防止局部模型过拟合,并保持模型的稳定性,最终的预测结果 $\hat{y}^*$ 是全局基础模型(Base Model)和局部注意力模型(Attention Model)的加权混合:
\[\hat{y}^* = (1-m)\hat{y}^*_{\text{base}} + m\hat{y}^*_{\text{attn}}\]其中,$m$ 是通过交叉验证选择的混合参数。
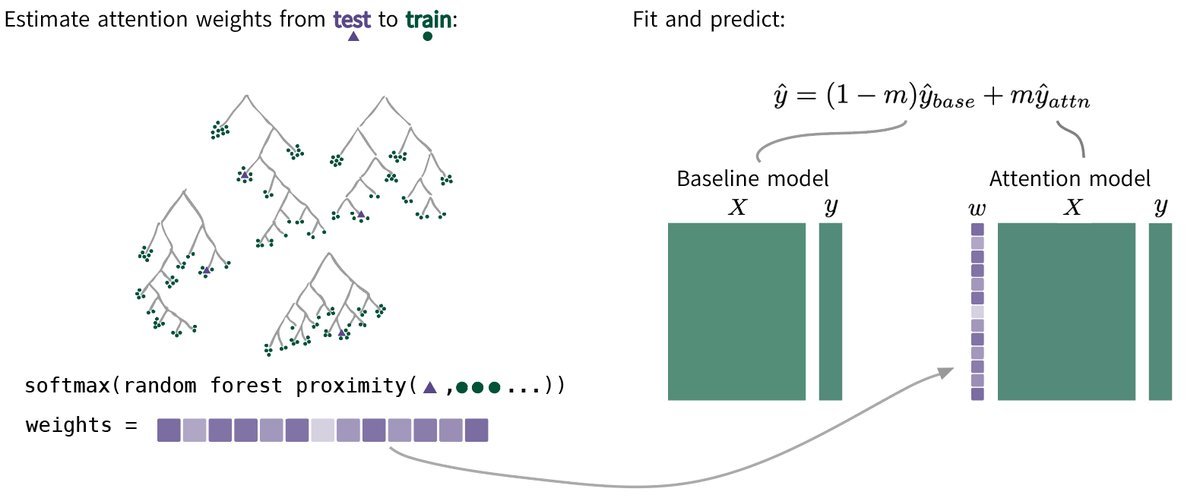
上图展示了这一过程:对于输入的测试样本(Input),系统通过注意力机制(Attention)从训练数据(Values)中提取相关信息,生成局部预测,最后与全局预测结合。
极致的可解释性
Attention Lasso 最吸引人的地方在于它提供了一种逐样本(Instance-level) 的解释能力。
对于任何一个预测结果,你都可以回答两个关键问题:
-
哪些特征最重要? 因为每个测试点都有自己的 Lasso 系数,你可以直接看到在该点的预测中,哪些特征的系数非零且较大。
-
哪些训练样本最相关? 通过查看注意力权重,你可以找出训练集中哪些样本对当前的预测贡献最大。这就像大模型告诉你它参考了哪些文档一样。
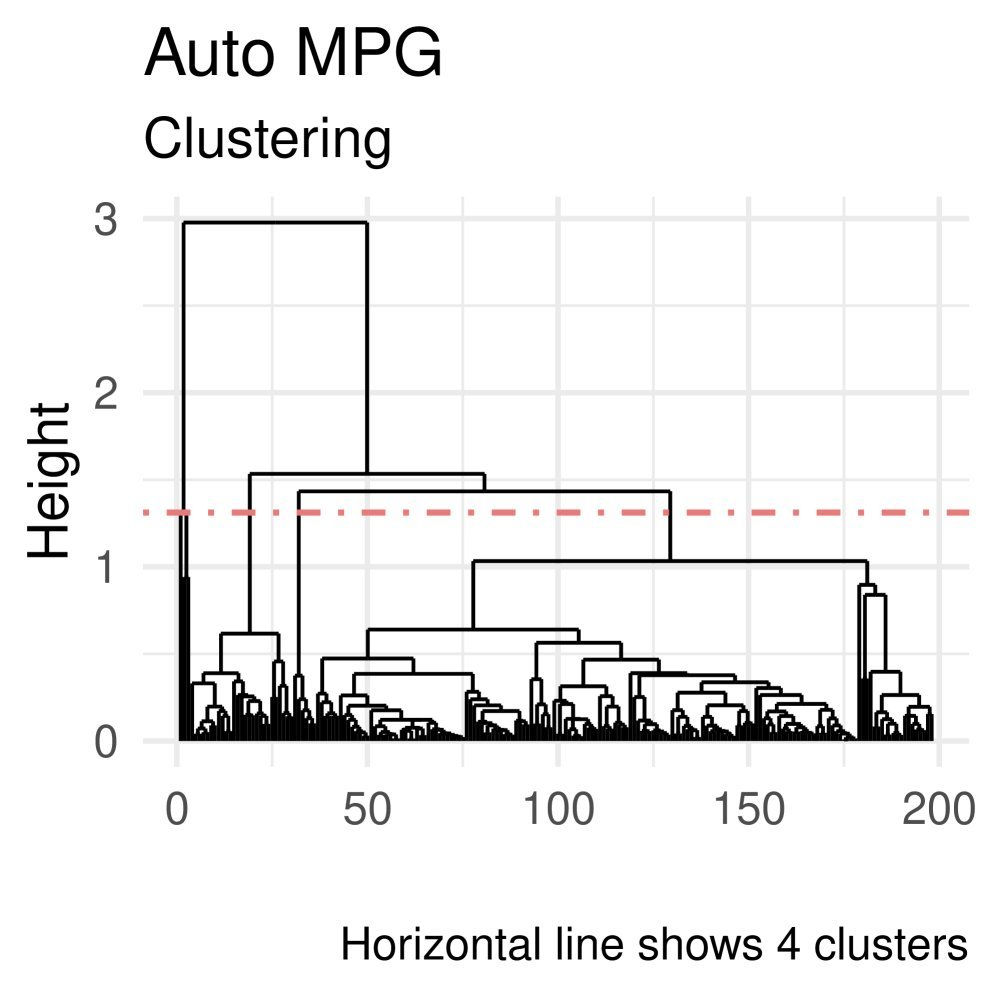
下图展示了在不同数据集上,Attention Lasso 学习到的系数聚类情况。这不仅展示了特征的重要性,还揭示了数据内部潜在的子群结构。
实验表现:简单即是美
研究人员在 UCI 机器学习库的多个数据集以及模拟数据上进行了测试。结果显示,Attention Lasso 的表现非常强劲。
在与 Lasso、XGBoost、LightGBM、随机森林和 KNN 的对比中,Attention Lasso 的预测平方误差(PSE)通常显著优于标准 Lasso,并且在许多情况下与复杂的树模型(如 XGBoost)不相上下,甚至更好。
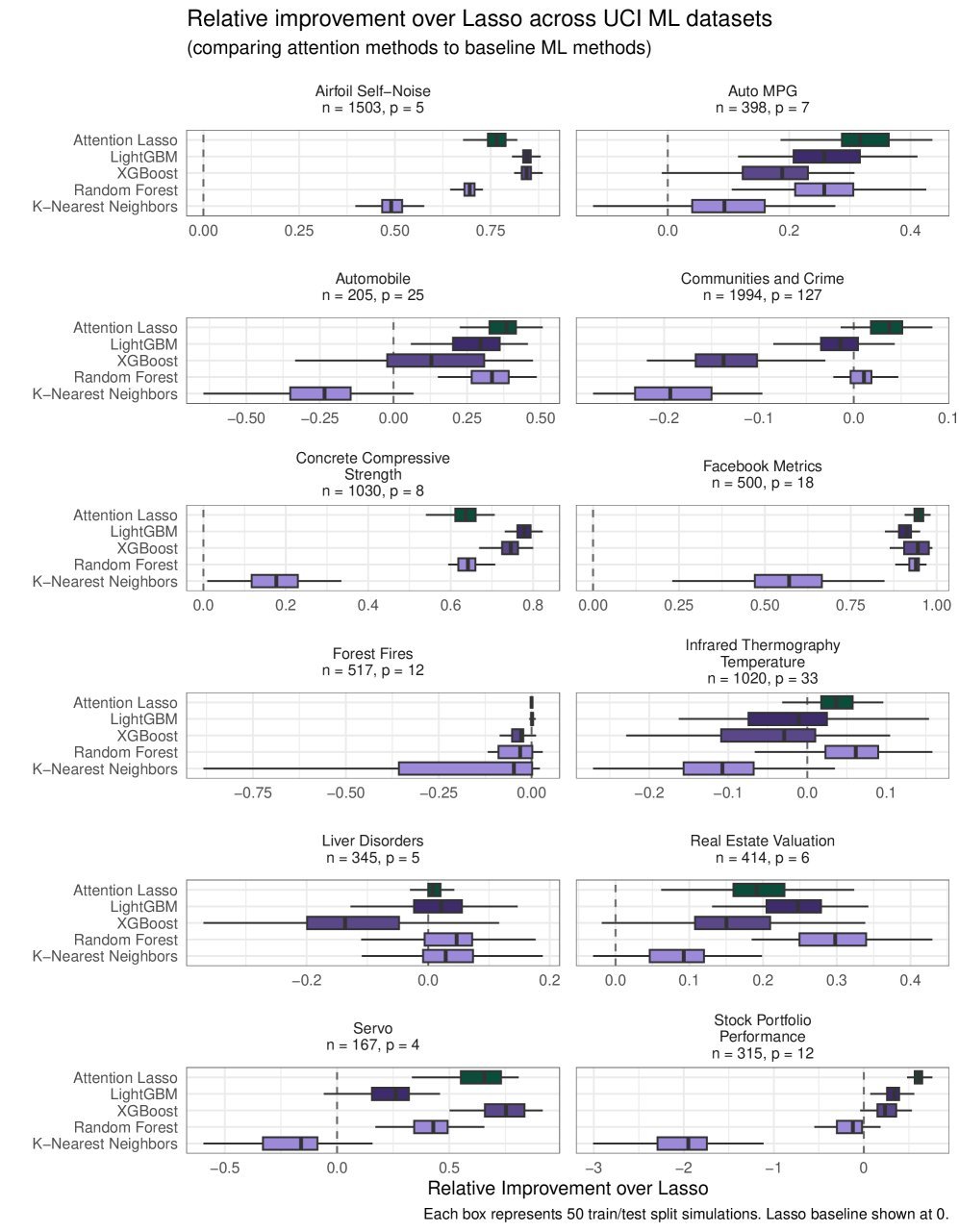
上图展示了相对 Lasso 的性能提升百分比(越往右越好)。可以看到,Attention Lasso(红色条)在绝大多数数据集上都取得了正向收益,且经常处于领先梯队。
扩展:时序与空间数据
这种“注意力”思想不仅限于独立的表格数据。论文还展示了如何将其扩展到:
-
时间序列:通过时间滞后(Lag)定义“邻居”,让模型关注历史上相似的时间段。
-
空间数据:利用空间坐标定义邻域。
例如在质谱成像数据的分类任务中,Attention Lasso 不仅准确区分了肿瘤组织和正常组织,还能通过系数可视化,清晰地展示出不同区域的分子特征差异。
总结
Supervised learning pays attention 这篇论文为我们提供了一个极具启发性的思路:大模型的“注意力”机制并不神秘,它本质上是一种灵活的加权方式。
将这种机制引入传统的统计学习方法中,我们得到了一种既能适应数据异质性、又能保持模型简单可解释的新工具。对于那些在金融、医疗等高风险领域工作,既追求精度又必须解释模型决策的数据科学家来说,Attention Lasso 无疑是一个值得尝试的强大武器。