T5Gemma 2: Seeing, Reading, and Understanding Longer
Google DeepMind重磅发布T5Gemma 2:让Encoder-Decoder架构在长文本与多模态中强势回归
在Decoder-only架构(如GPT、Llama)几乎统治大语言模型江山的今天,你是否想过:经典的Encoder-Decoder架构真的过气了吗?
ArXiv URL:http://arxiv.org/abs/2512.14856v1
Google DeepMind给出的答案是:绝对没有。
近日,DeepMind发布了T5Gemma 2,这是对其轻量级Encoder-Decoder模型家族的最新升级。它不仅继承了T5的衣钵,更融合了Gemma 3的强大基因,在多模态理解、长文本处理以及多语言能力上展现出了惊人的潜力。更重要的是,它证明了通过巧妙的“改造”,我们完全可以将现有的Decoder-only模型转化为强大的Encoder-Decoder模型。
本文将带你深入解读T5Gemma 2背后的技术细节,看看它是如何通过“移花接木”之术,实现性能的全面飞跃。
核心理念:从Decoder-only到Encoder-Decoder的华丽转身
T5Gemma 2的核心思想非常直接且高效:不要从头开始训练,而是站在巨人的肩膀上。
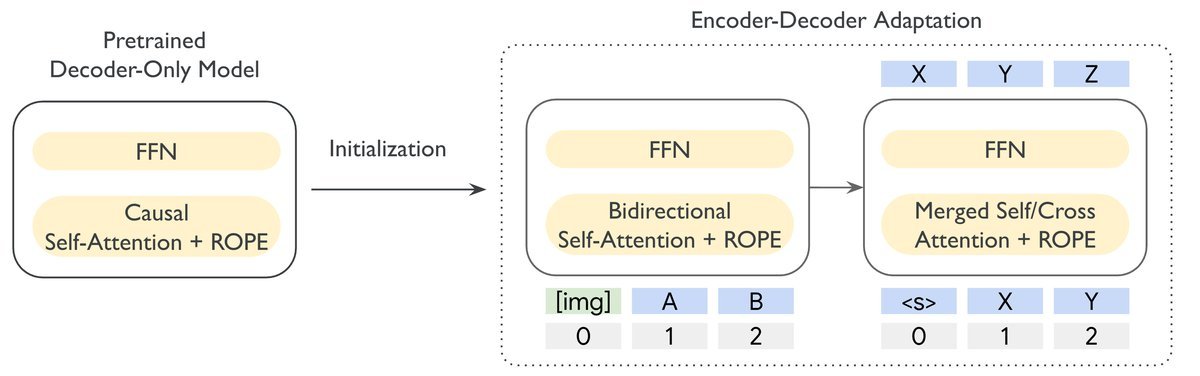
研究团队采用了一种独特的适配配方(Adaptation Recipe),直接利用预训练好的Gemma 3(一个纯Decoder模型)的参数来初始化T5Gemma 2。
具体来说,T5Gemma 2的Encoder和Decoder部分都从Gemma 3的权重中继承而来。然后,利用UL2(Unifying Language Learning)目标进行继续预训练。这种方法不仅节省了从零训练的昂贵成本,还直接继承了Gemma 3在海量数据上学到的知识。
架构创新:更高效、更统一
为了让这种“改装”更顺滑,且模型运行更高效,T5Gemma 2引入了两项关键的架构改进:
1. 绑定词嵌入(Tied Word Embedding)
在传统的Encoder-Decoder模型中,Encoder输入、Decoder输入和Decoder输出通常使用独立的嵌入矩阵。这对于小模型来说,参数冗余非常严重。
T5Gemma 2选择将这三者全部共享。实验表明,这一操作在几乎不损失模型质量的前提下,减少了约10.5%的参数量。这对于移动端或边缘设备上的部署至关重要。
2. 融合注意力机制(Merged Attention)
这是本文的一个亮点设计。通常,Decoder层包含两个独立的注意力模块:
-
Self-Attention:看自己生成了什么。
-
Cross-Attention:看Encoder输入了什么。
T5Gemma 2将这两个模块合并为一个联合模块(Merged Attention)。
\[\mathbf{A}=\text{SoftMax}\left(\frac{\mathbf{Q}\mathbf{K}^{T}}{\sqrt{d\_{h}}}\odot\mathbf{M}\right)\mathbf{V}\]在这个公式中,Key ($\mathbf{K}$) 和 Value ($\mathbf{V}$) 同时包含了当前Decoder的输入 ($\mathbf{X}$) 和Encoder的输出 ($\mathbf{H}$)。
这样做的好处是什么?
-
参数更少:减少了6.5%的总参数量。
-
结构更统一:使得Decoder的结构与Gemma 3原本的Decoder结构差异更小,从而让参数初始化更加容易和稳定。
视觉与长文本:补齐短板
T5Gemma 2不仅仅是一个文本模型,它还是一个多模态长文本专家。
-
视觉能力:它直接复用了Gemma 3中的SigLIP视觉编码器(400M参数),并将其冻结。图像被转换为256个Token喂给Encoder。这意味着,原本纯文本的Gemma 3模型,经过这套流程改造后,摇身一变具备了强大的看图能力。
-
长文本能力:通过位置插值(Positional Interpolation)技术,T5Gemma 2支持高达128K的上下文窗口。更有趣的是,Encoder-Decoder架构在长文本建模上展现出了独特的优势——Encoder的双向注意力机制能更好地全局理解长输入,而Cross-Attention则能精准地从长上下文中“检索”出相关信息。
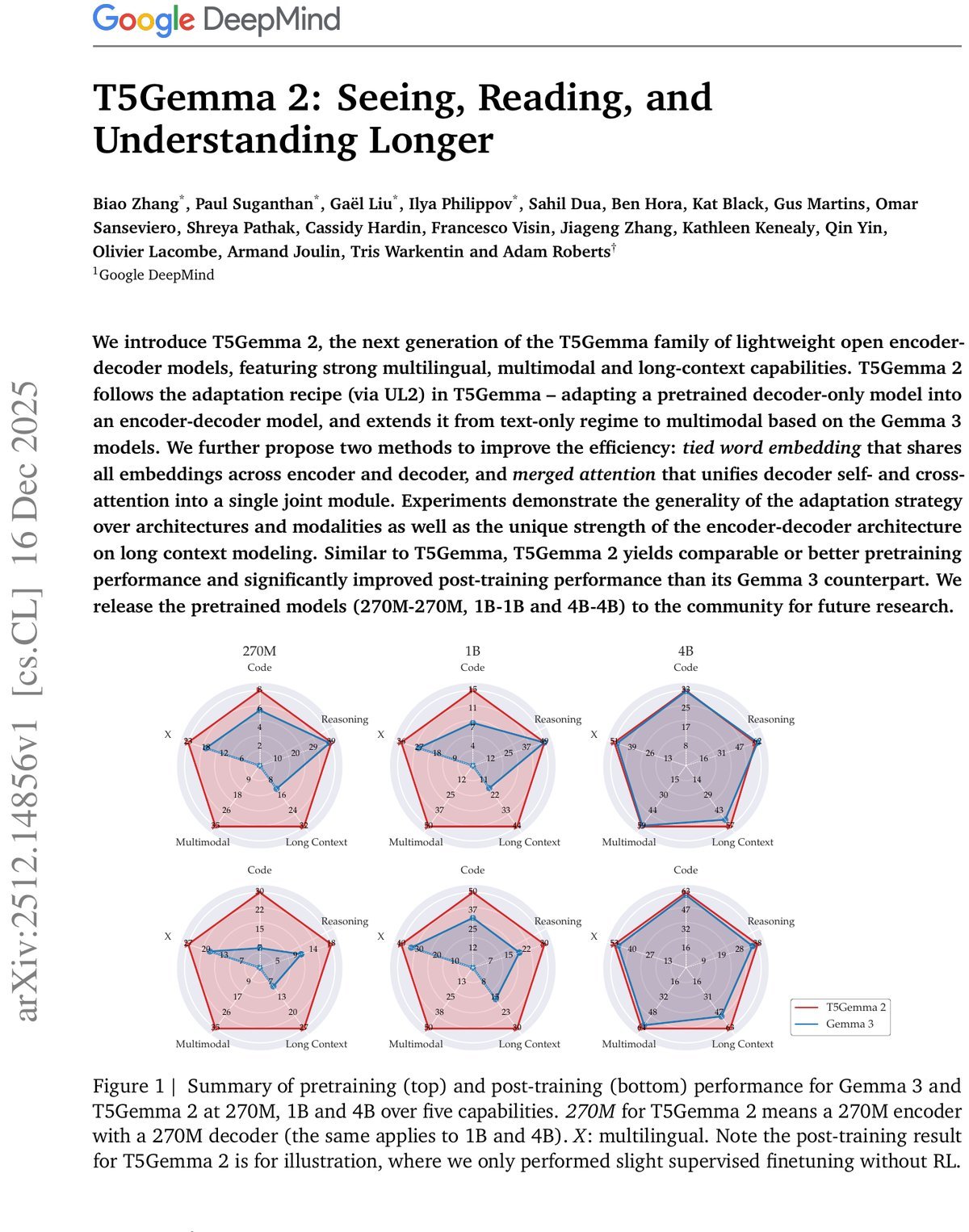
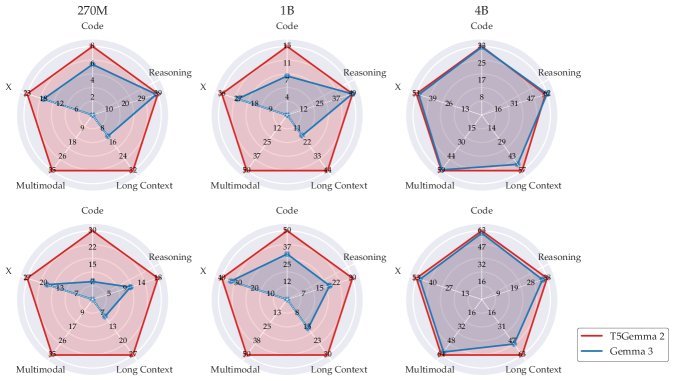
实验结果:青出于蓝而胜于蓝
研究团队发布了270M、1B和4B三个尺寸的模型。实验结果令人振奋:
-
多模态惊喜:即使是基于纯文本Gemma 3改造的270M和1B版本,在多模态任务上也表现出色。
-
长文本优势:尽管预训练时序列长度仅为16K,但模型外推至128K时依然稳健,性能甚至优于原生Gemma 3。
-
后训练提升:在仅进行轻量级微调(SFT)而未使用强化学习(RL)的情况下,T5Gemma 2的综合表现依然超越了经过复杂后训练的Gemma 3。
总结
T5Gemma 2的发布向社区传递了一个明确的信号:Encoder-Decoder架构在生成式AI时代依然大有可为。
它不仅证明了我们可以低成本地将Decoder-only模型“改造”为Encoder-Decoder模型,更展示了这种架构在处理多模态信息和超长上下文时的天然优势。对于需要精准理解长文档、同时处理图文信息的应用场景,T5Gemma 2无疑提供了一个极具吸引力的开源新选择。
目前,Google DeepMind已经开源了全部三个尺寸的预训练模型,你准备好试一试了吗?