Tackling the Inherent Difficulty of Noise Filtering in RAG
RAG去噪为何这么难?人大清华揭秘“三元困境”,非线性微调让LLM自带“过滤器”

在构建 检索增强生成(Retrieval-Augmented Generation, RAG)系统时,我们往往面临一个令人头秃的现实:无论检索器(Retriever)优化得多么好,总会有“噪声文档”混入上下文。这些无关信息不仅浪费了宝贵的上下文窗口,更糟糕的是,它们会误导大模型,导致严重的幻觉问题。
ArXiv URL:http://arxiv.org/abs/2601.01896v2
你可能会想:“这有什么难的?直接对LLM进行微调,让它学会‘忽略’这些噪声不就行了吗?”
然而,来自中国人民大学和清华大学的研究团队在最新论文中告诉我们:事情并没有那么简单。 传统的微调方法在处理噪声时存在天然的结构性缺陷,甚至可能“拆东墙补西墙”,破坏模型的推理能力。
今天,我们就来深度解读这项研究,看看他们是如何破解RAG去噪难题的。
为什么检索器总是“过滤”不干净?
首先,我们要理解为什么噪声文档如此难以被彻底剔除。研究人员提出了一个核心概念:三元困境(The Triple-Wise Problem)。
传统的检索模型(如双塔模型)通常基于 Query 和 Document 之间的成对(Pairwise)相似度来工作。但在复杂的推理场景中,判断一个文档是否相关,往往涉及到三个甚至更多的元素。
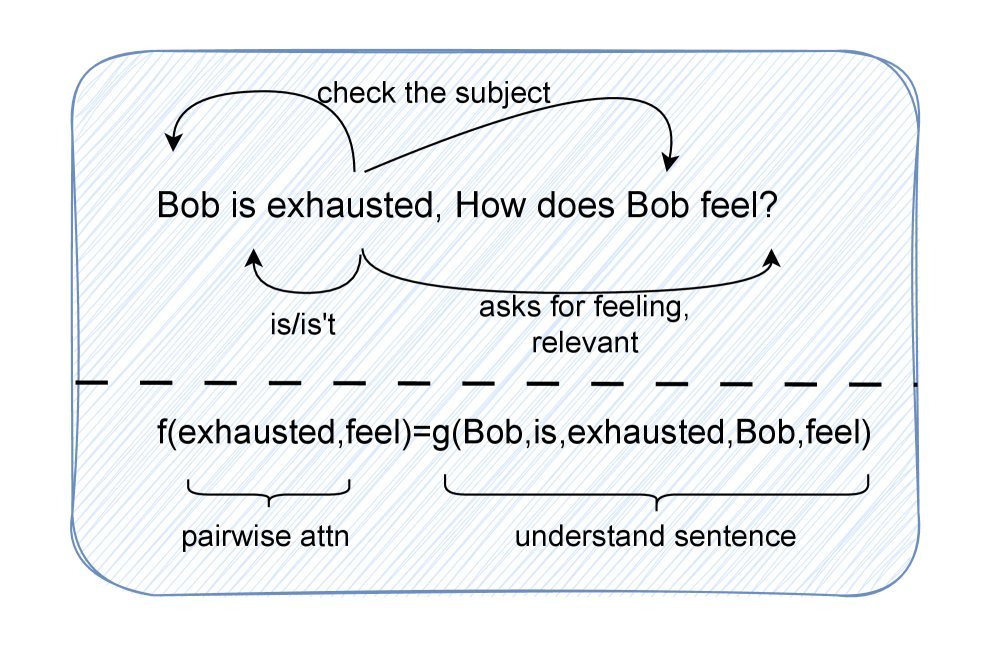
如上图所示,假设 Query 是“Bob感觉如何?”,文档中有一句“Alice和Bob在跑步,Bob精疲力竭”。要判断“精疲力竭(exhausted)”这个词是否相关,模型必须同时连接:
-
Query 中的“Bob”和“feel”。
-
文档中的“Bob”(主语)。
-
文档中的“exhausted”(状态)。
这种三元依赖关系(Triple-wise nature)对于层数较少、结构简单的检索器(Retriever)来说,是极难捕捉的。因此,指望检索器完全过滤噪声是不现实的,压力最终还是给到了 LLM 这边。
传统微调的“致命伤”:线性更新的局限性
既然检索器靠不住,我们自然希望 LLM 能拥有“火眼金睛”,在阅读上下文时自动忽略噪声。通常的做法是使用 低秩适应(LoRA)等技术对 LLM 进行微调。
但在论文中,作者通过数学推导揭示了一个惊人的结论:标准的线性微调无法同时兼顾“去噪”和“推理”。
在标准的注意力机制微调中,我们通常是给原始权重 $W$ 加上一个增量 $\Delta W$。新的注意力分数计算如下:
\[attn^{\prime}({\mathbf{x}}\_{i},{\mathbf{x}}\_{j})={\mathbf{x}}\_{i}^{T}({\mathbf{W}}+\Delta{\mathbf{W}}){\mathbf{x}}\_{j}\]这就带来了一个两难的权衡(Trade-off):
-
为了去噪:你需要让 $\Delta W$ 对噪声 Token 产生极大的负值,把它们的注意力分数压到接近 0。
-
为了推理:对于那些相关的 Token,你需要保留它们之间细腻的相对权重关系,以便模型进行复杂的推理。
遗憾的是,由于 $\Delta W$ 是线性作用于所有 Token 的,如果你强行增大 $\Delta W$ 来“压死”噪声,往往会破坏相关 Token 之间原本微妙的注意力分布,导致模型推理能力下降。简单来说,你为了关掉背景噪音,把主角的声音也给搞失真了。
破局之道:非线性注意力矫正
为了解决这个问题,作者提出了一种新颖的微调方法。核心思想非常直观:既然线性更新做不到,那就引入非线性机制。
他们设计了一种非线性矫正函数(Non-linear Rectification Function),将微调的目标解耦。新的注意力计算公式变成了这样:
\[attn^{\prime}({\mathbf{x}}\_{i},{\mathbf{x}}\_{j})={\mathbf{x}}\_{i}^{T}{\mathbf{W}}{\mathbf{x}}\_{j}+g({\mathbf{x}}\_{i}^{T}\Delta{\mathbf{W}}{\mathbf{x}}\_{j})\]这里的 $g(x)$ 是一个精心设计的激活函数(类似于 $\tanh$ 或 Sigmoid 的变体)。它的作用就像一个智能的“噪声门”:
-
对于噪声 Token:当 $\Delta W$ 产生负值时,函数会迅速饱和,产生一个极大的惩罚项,直接将该 Token 的注意力权重“归零”。
-
对于相关 Token:函数保持在较为平缓的线性区域,允许模型对相关信息进行微调,而不破坏其原有的相对重要性。
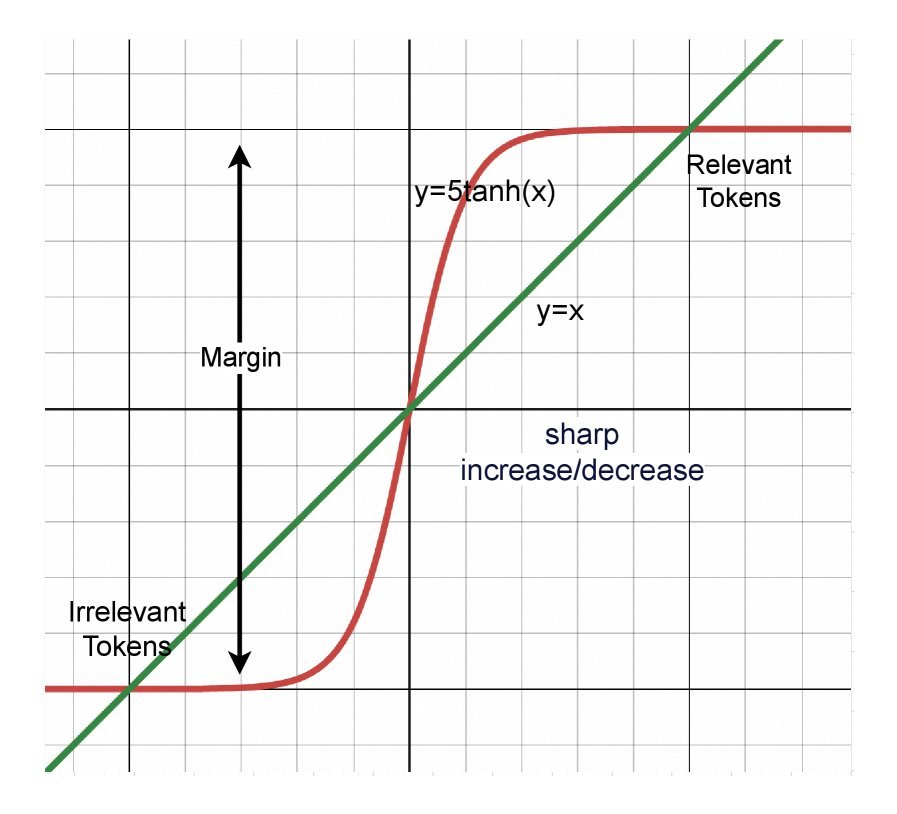
如上图所示,这种方法成功地将“去噪”和“特征提取”两个任务分离开来,打破了线性更新的桎梏。
实验结果:显著的鲁棒性提升
研究团队在 Natural Questions (NQ)、TriviaQA、HotpotQA 等多个基准数据集上进行了广泛测试。实验设置非常硬核:故意在检索结果中混入干扰文档,看模型会不会被带偏。
结果显示,使用了该非线性微调方法的模型(Ours),在面对噪声时表现出了极强的鲁棒性。
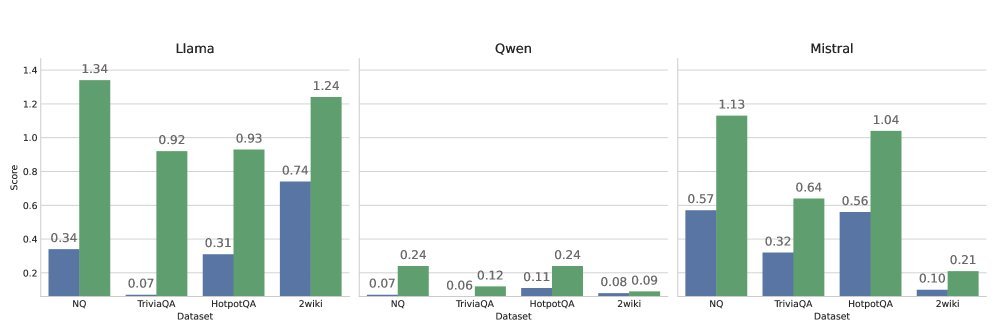
更有趣的是图 3 的可视化结果(Attention Gap)。它展示了模型对“答案 Token”和“其他 Token”的注意力分数差值。
-
Vanilla(原始模型):即使微调后,两者差距也不大,说明模型还是容易分心。
-
Ours(本文方法):两者差距显著拉大。这意味着模型学会了果断地“关注”正确信息,同时“无视”干扰信息。
总结
这篇论文给 RAG 系统的开发者们提了一个重要的醒:
-
不要过度迷信检索器的过滤能力,噪声是 RAG 的固有属性。
-
想通过微调让 LLM 变“聪明”,不能只靠堆数据。传统的线性微调(如标准 LoRA)在处理噪声过滤任务时存在理论上限。
-
通过引入非线性注意力矫正,我们可以让 LLM 真正具备“选择性忽视”的能力,在嘈杂的文档海洋中精准捕获关键信息。
对于正在落地 RAG 应用的开发者来说,这种修改注意力计算方式的微调思路,或许是提升系统抗干扰能力的下一个关键突破口。