The Curse and Blessing of Mean Bias in FP4-Quantized LLM Training
FP4训练的诅咒与祝福:简单“减均值”,性能直追BF16

想要训练更经济、更高效的大语言模型(LLM)吗?4比特(FP4)量化训练听起来像个完美的答案,但它却像一匹难以驾驭的野马,常常伴随着训练崩溃的风险。
ArXiv URL:http://arxiv.org/abs/2603.10444v1
过去,研究者们认为问题出在模型激活值的“尖峰”上,并试图用奇异值分解(SVD)等复杂且昂贵的“屠龙之术”来驯服它。
然而,来自复旦大学、牛津大学等机构的最新研究揭示了一个惊人的事实:真正导致不稳定的“元凶”,其实是一个极其简单且普遍存在的现象——均值偏差。
更妙的是,这个发现不仅揭示了问题的根源(诅咒),更带来了一个异常简单的解决方案(祝福)。
LLM训练中的“异常值”幽灵
在LLM内部,数据以高维向量(激活值)的形式流动。一个长期存在的观察是,这些激活值向量的分布极不均衡。
这种现象被称为“各向异性”(Anisotropy)。
它指的是模型内部的激活值能量分布极不均匀:少数几个方向聚集了绝大部分能量,形成“尖峰”;而海量的其他方向则能量微弱,构成了所谓的“长尾”。
在进行FP4这样的低比特量化时,问题就来了。
量化过程需要为一组数值确定一个缩放范围,而这个范围由这组数中的最大值(异常值)决定。
当“尖峰”方向的数值极大时,它会极大地拉伸量化范围。这导致“长尾”中那些虽然数值小但包含丰富语义的维度,被压缩到极少数几个量化档位里,信息大量丢失,最终导致训练不稳定甚至崩溃。
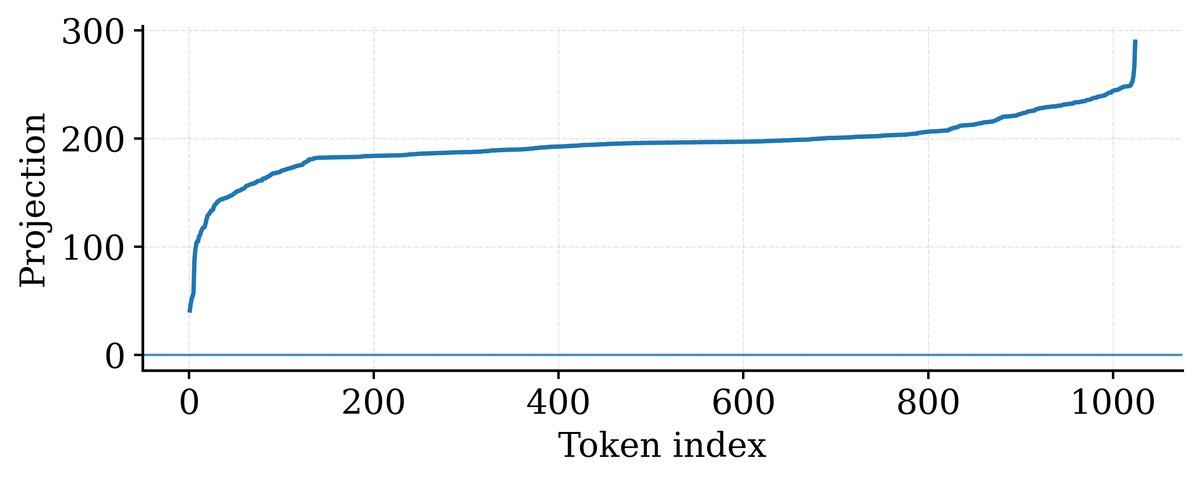
图1:激活值中存在显著的“尖峰”方向
以往的方法,如Metis,试图通过SVD等谱方法来识别并抑制这些“尖峰”,但这些方法计算复杂、内存开销大,与现代硬件加速器的设计理念格格不入。
罪魁祸首:无处不在的“均值偏差”
这篇论文的核心洞察在于,激活值的各向异性并非源于什么神秘的谱结构,其主要驱动力是一个连贯的、秩为1的均值偏差(Mean Bias)。
这是什么意思呢?
简单来说,在处理一个批次(batch)的文本时,所有Token的激活值在特征维度上存在一个共同的、非零的平均分量。
这个均值偏差并非偶然,它在LLM中被系统性地产生和放大:
-
词频起源:在输入端,高频词(如“的”、“是”)和低频词的词嵌入向量本身就存在统计偏差,形成了初始的均值分量 $ \mu_{\text{embed}} $。
-
非线性放大:像GeLU这样的非线性激活函数,其期望输出 $ \mathbb{E}[\phi(z)] $ 大于零,会进一步放大均值分量。
-
残差累积:Transformer中的残差连接 $ \mu_{l+1}=\mu_{l}+\Delta\mu_{l} $,会将每一层产生的均值偏差不断累加,使其在更深层变得越来越显著。
在高维空间中,即使每个维度的均值偏差 $ \bar{\mu} $ 很小,其整体向量的范数也会被维度 $ H $ 放大,即 $ \ \mid \mu\ \mid _{2}\sim\sqrt{H}\,\bar{\mu} $。
这意味着,这个看似不起眼的均值分量,随着网络加深和训练推进,会成长为一个能量巨大的“巨人”。
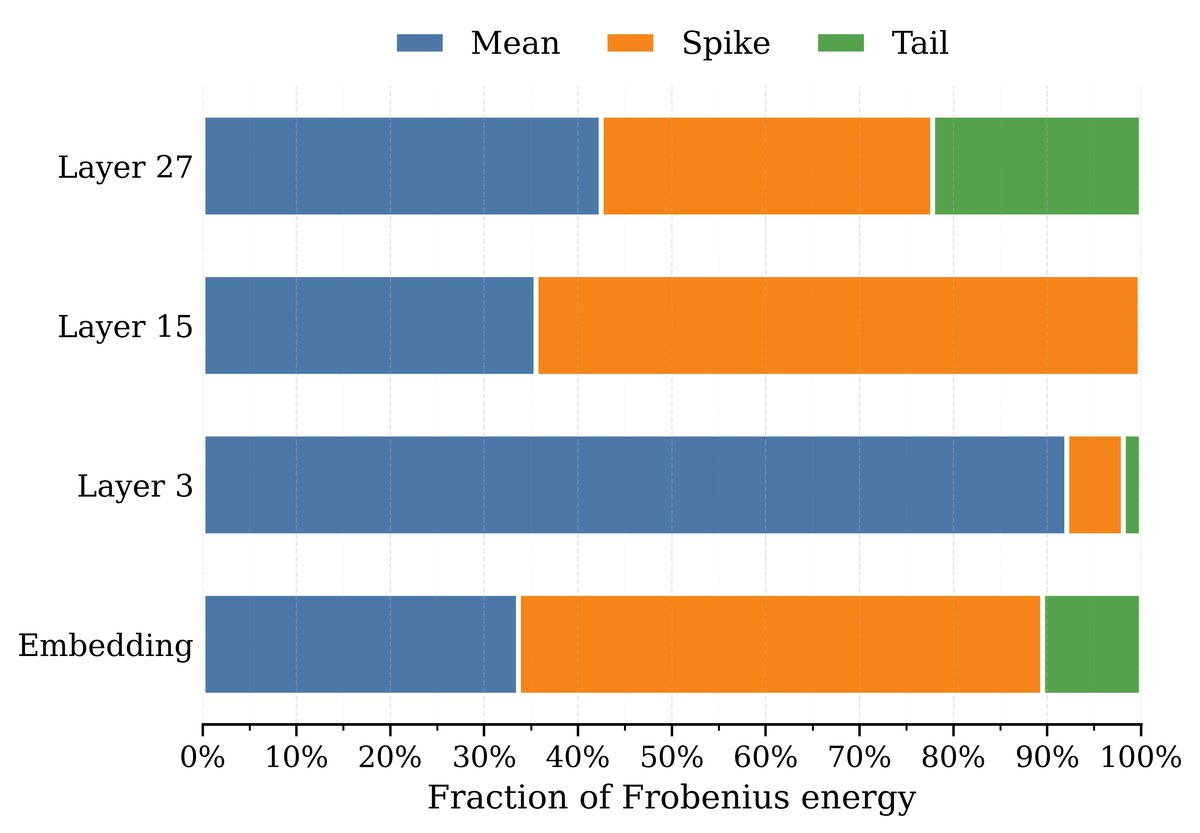
图2:随着训练(从10k步到170k步)和网络加深,均值偏差(Mean)在总能量中的占比越来越高
均值偏差如何制造“极端”异常值
论文通过一个精巧的实验,无可辩驳地证明了均值偏差是激活值异常值的“主谋”。
研究者将激活矩阵 $ X $ 分解为三个正交的部分:
\[X=\underbrace{\mathbf{1}\mu^{\top}}_{M(\text{mean})}+\underbrace{U_{k}\Sigma_{k}V_{k}^{\top}}_{X_{\text{spike}}}+\underbrace{X_{\text{tail}}}_{\text{residual}}\]-
$ M(\text{mean}) $:均值偏差分量。
-
$ X_{\text{spike}} $:去除均值后,能量最强的1%的“尖峰”分量。
-
$ X_{\text{tail}} $:剩余的“长尾”分量。
然后,他们分析了激活值中最大的0.1%的异常值,其能量究竟来自哪个部分。
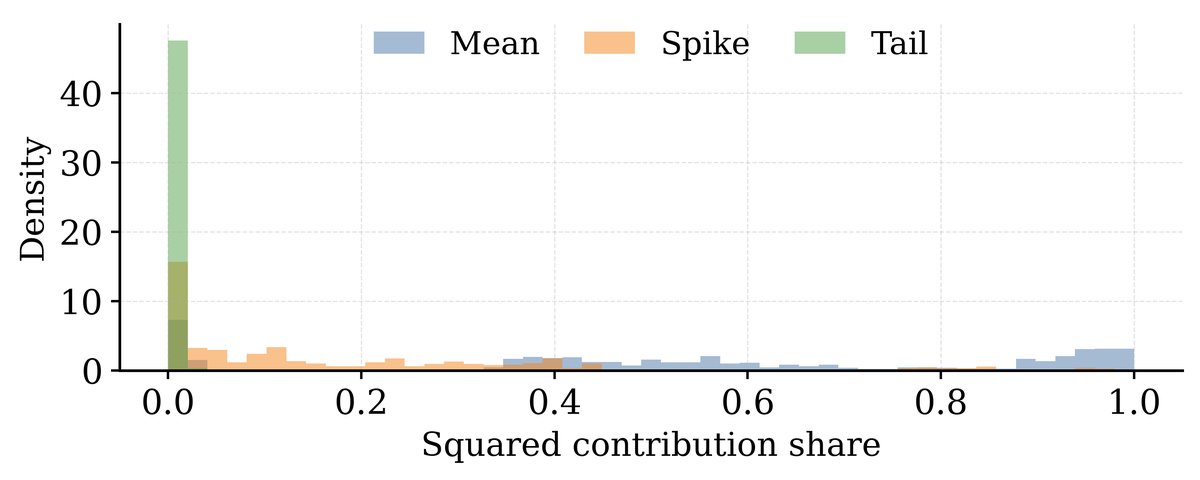
图3:在训练后期(170k步)的深层网络(第27层)中,前0.1%的异常值(Top 0.1% Outliers)的能量绝大部分(橙色部分)都归因于均值偏差(Mean Component)
结果一目了然。在训练的后期阶段,无论是在浅层还是深层,均值偏差分量都是构成极端异常值的主要来源。
理论分析也给出了支撑(定理1、2、3)。简单来说,一个确定性的均值偏差 $ \mu_j $ 产生的异常值数量是 $ \Theta(l) $ 级别的($ l $ 是序列长度),而随机噪声产生的异常值数量则是指数级稀少的。
这彻底颠覆了以往的认知:我们苦苦寻找的“异常值幽灵”,原来就是这个潜伏在数据中的“平均数”。
Averis:化诅咒为祝福的简单魔法
既然问题的根源是均值偏差,那么解决方案也变得异常简单:在量化之前,把它减掉就行了!
该研究提出了一个名为Averis(Averaging-Induced Residual Splitting,均值诱导的残差分裂)的方法。
其核心思想是:
-
前向传播:对于输入激活矩阵 $ \mathbf{X} $,先计算其沿Token维度的均值向量 $ \mu_{\mathbf{X}} $。然后,将 $ \mathbf{X} $ 分解为均值部分 $ \mathbf{1}\,\mu_{\mathbf{X}} $ 和残差部分 $ \mathbf{X}_{\mathrm{R}} = \mathbf{X}-\mathbf{1}\,\mu_{\mathbf{X}} $。最后,对均值向量和残差矩阵分别进行FP4量化,再执行计算。
\[\hat{\mathbf{Y}}\;=\;\mathbf{1}\,(\bar{\mu}_{\mathbf{X}}\bar{\mathbf{W}})\;+\bar{\mathbf{X}}_{\mathrm{R}}\,\bar{\mathbf{W}}\] -
反向传播:对于输出梯度矩阵 $ \mathbf{D} $,也采用同样的方式进行均值-残差分解和独立量化。
这个方法的美妙之处在于其极致的简洁和高效。
它只需要标准的均值计算(Reduction)和逐元素减法操作,完全避免了SVD等昂贵的谱分解,并且所有操作都能在GPU上高效执行。
实验效果:显著缩小的性能差距
研究者在0.6B参数规模的Qwen模型上进行了实验,对比了BF16全精度训练、标准FP4量化训练以及使用了Averis的FP4训练。
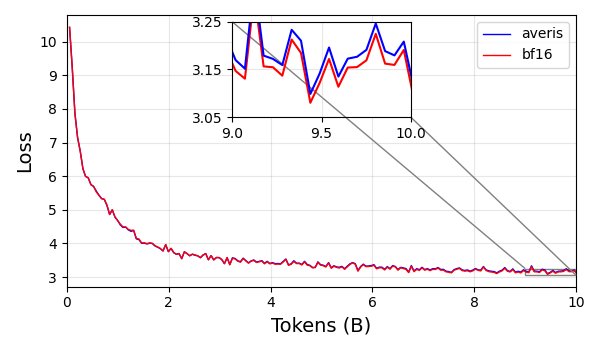
图4:训练损失曲线。Averis (FP4+Ours, 绿色) 显著优于朴素的FP4(蓝色),大幅缩小了与BF16基线(橙色)的差距
从训练损失曲线可以看出,Averis方法极大地提升了FP4训练的稳定性,其损失曲线紧紧跟随着BF16基线,而朴素的FP4训练则表现不佳。
在下游任务的评测中,Averis同样恢复了大部分因朴素FP4量化而损失的性能。
结论
这项研究深刻地揭示了LLM低比特训练不稳定的核心症结——激活值中的均值偏差。
这个均值偏差既是“诅咒”,因为它放大了动态范围,破坏了低比特量化的稳定性;但它同时也是“祝福”,因为它结构简单(秩为1),提供了一个极其廉价的“抓手”来解决问题。
通过Averis这个简单而优雅的“减均值”操作,该研究为实现稳定、高效的低比特LLM训练铺平了道路,让我们离普惠的、绿色的大模型时代又近了一步。