The Illusion of Insight in Reasoning Models
普林斯顿揭秘:模型“顿悟”竟是幻觉?百万推理轨迹拆解“自我修正”真相

DeepSeek-R1-Zero 的横空出世,让一种现象备受瞩目:模型在推理过程中突然输出一句“Wait… let’s re-evaluate”(等等,让我们重新评估一下),然后神奇地修正了之前的错误。这种类似人类“顿悟”(Aha! Moment)的行为,被广泛认为是模型具备内在自我修正(Intrinsic Self-Correction)能力的铁证。
ArXiv URL:http://arxiv.org/abs/2601.00514v1
但这真的是模型“灵光一现”的智慧涌现吗?
普林斯顿大学的一项最新研究,通过分析超过 100 万条推理轨迹,给这种浪漫的想象泼了一盆冷水。研究发现,这种所谓的“顿悟”时刻不仅极其罕见,而且通常是模型推理不稳定的症状,而非真正的自我修正机制。更有趣的是,虽然模型自发的修正往往无效,但如果我们利用“不确定性”去人为触发这种反思,反而能显著提升准确率。
这是一篇关于打破幻觉、回归理性的硬核分析。
什么是“顿悟”时刻?
为了科学地研究这个问题,研究人员首先定义了什么是模型推理中的“顿悟”时刻(Aha! Moment)。它不仅仅是模型改了口,必须同时满足三个苛刻条件:
-
先前的失败:在这一步之前,模型原本的策略是注定要失败的。
-
明显的转变:模型在推理轨迹(Trace)中间出现了可被检测到的策略转移(Reasoning Shift)。
-
性能提升:这种转变直接导致了最终答案从错误变为正确。
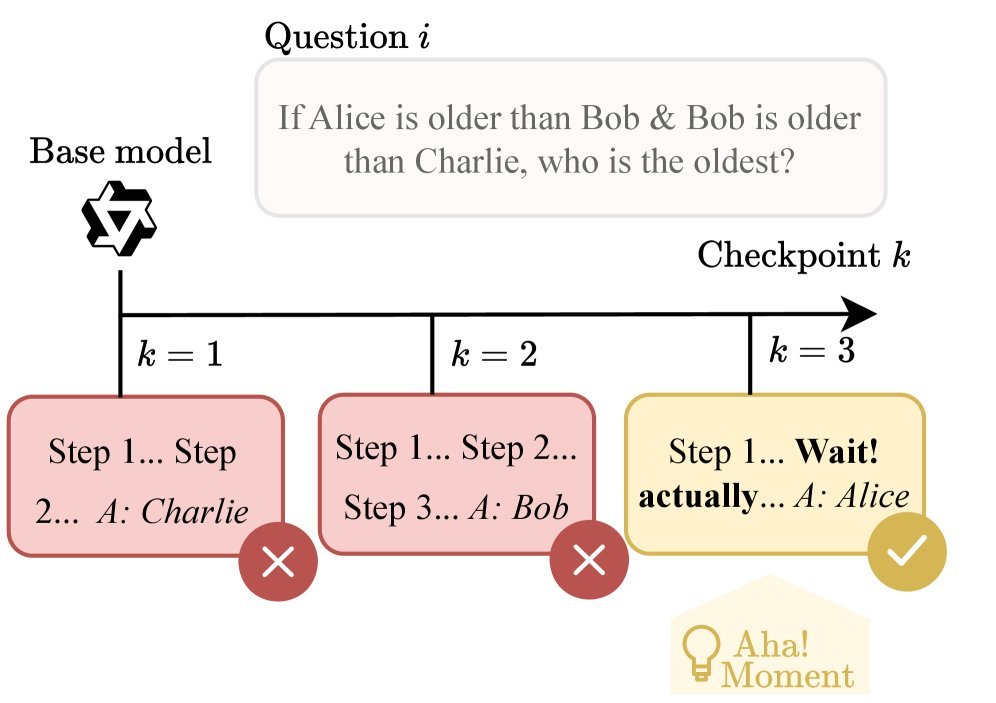
图 1:“顿悟”时刻解剖。图示展示了一个典型的修正过程:模型从错误的策略 $k \in {1,2}$ 突然通过一句“Wait…”转向了正确的策略 $k=3$。
普林斯顿团队并没有只盯着成品模型看,而是从头开始训练。他们使用 GRPO(Group Relative Policy Optimization)算法对 Qwen2.5 和 Llama 模型进行了微调,并在训练的各个阶段(数百个 Checkpoints)收集了超过 100 万条推理轨迹。
测试领域涵盖了三个截然不同的任务:
-
MATH-500:数学问题解决。
-
Cryptic Crosswords:需要横向思维的填字游戏。
-
Rush Hour:需要空间推理的滑块拼图。
残酷的真相:自发的“修正”通常是帮倒忙
通过对这百万条数据的地毯式分析,研究得出了三个颠覆认知的结论(RQ1 & RQ2):
1. 推理转变极其罕见
你以为模型在不断反思?其实并没有。在所有生成的轨迹中,检测到推理转变(Reasoning Shift)的比例仅为 6.31%。真正的“顿悟”(即转变后变对了)更是凤毛麟角。
2. 转变往往意味着更低的准确率
这是最反直觉的一点。数据显示,那些包含“Wait…”、“Actually…”等转折词的推理轨迹,其最终准确率通常低于那些一条路走到黑的轨迹。
以数学任务为例,包含推理转变的轨迹,其准确率比不包含的平均低了 11.83 个百分点。这说明,当模型开始“犹豫”或“重写”时,通常不是因为它变聪明了,而是因为它乱了。
3. 训练并没有让“顿悟”变多
随着 RL(强化学习)训练的进行,模型的能力确实变强了,但这种“中途修正”的行为频率并没有显著增加,其带来的正面收益也没有明显变化。这意味着,“顿悟”并不是 RL 训练出来的一种高级能力。
图 4:推理转变(Shift)对准确率的影响。在大多数情况下(柱状图位于 0 以下),发生转变的轨迹准确率反而更低。
为什么会这样?不确定性在作祟
既然自发的修正大多是无效的,那这种行为究竟是什么?
研究人员引入了熵(Entropy)作为衡量模型不确定性的指标。分析发现,推理转变往往发生在模型处于高熵(即非常不确定)的状态下。
换句话说,模型输出“Wait…”,并不是因为它“意识到”自己错了,而是因为它在当前的生成的 token 分布上极度混乱。这种转变是推理行为不稳定(Unstable Inference Behavior)的症状,而不是一种深思熟虑的内在机制。
反转:如何把“幻觉”变成“真理”?
虽然模型自发的修正不靠谱,但研究人员发现了一个利用这一现象的绝佳机会(RQ3)。
既然我们知道“高熵”意味着模型在犹豫,那如果我们在这个时候强制推它一把呢?
研究设计了一个干预实验:
-
监控模型生成过程中的熵值。
-
当发现模型处于“高不确定性”状态时,人为地插入一句提示词,例如:“Wait, something is not right, we need to reconsider. Let’s think this through step by step.”(等等,有些不对劲,我们需要重新考虑。让我们一步步想清楚。)
-
强制模型基于这个提示词重新生成后续推理。
结果惊人:这种外部触发(Extrinsic Trigger)的修正极其有效!
在 MATH-500 数据集上,针对高熵样本进行这种干预,模型的准确率提升了 8.41%。
这揭示了一个关键的区别:
-
内在修正(Intrinsic):模型自己瞎折腾,通常是噪音,效果差。
-
外在触发(Extrinsic):在模型迷茫(高熵)时,由外部信号引导其反思,效果好。
总结与启示
这篇论文通过扎实的数据告诉我们:不要过度神话大模型的“拟人化”行为。
DeepSeek-R1-Zero 等模型展现出的“顿悟”,在统计学上更多是一种幸存者偏差——我们只记住了它改对的那几次,却忽略了它在无数次“Wait…”之后依然胡说八道,甚至把对的改错的情况。
核心结论:
-
“顿悟”是幻觉:中途推理转变通常与低准确率相关,是模型不稳定的表现。
-
不确定性是钥匙:虽然自发修正无效,但模型的不确定性(熵)是一个极具价值的信号。
-
干预优于放任:与其期待模型自己“顿悟”,不如构建机制,在检测到高不确定性时,显式地触发反思流程。
这为未来的 Agent 设计和 Process Supervision(过程监督)提供了重要思路:真正的智能可能不在于模型会自己说“等等”,而在于我们知道何时该对它说“等等”。