反驳“LLM死路论”!斯坦福提出AGI“缺失层”,用一个公式定义通往AGI之路

关于大型语言模型(LLM)的未来,AI领域正上演一场激烈的辩论。一派认为,只要不断扩大模型规模,AGI(通用人工智能)的曙光就在眼前;而另一派,以LeCun等巨擘为代表,则尖锐地指出:LLM不过是“模式匹配器”,结构上无法实现真正的推理和规划,是通往AGI的一条死路。
ArXiv URL:http://arxiv.org/abs/2512.05765v1
这场争论的核心究竟是什么?斯坦福大学的一篇重磅论文《The Missing Layer of AGI》给出了一个振聋发聩的答案:我们可能都搞错了重点。LLM不是死路,而是通往AGI不可或缺的基石。我们缺少的,是驾驭这股强大力量的“协调层”。
LLM是死路?不,你可能混淆了大海和渔网
论文提出了一个绝妙的比喻来阐明其核心观点。
将LLM想象成一片浩瀚的海洋,里面充满了各种各样的模式、知识和潜在行为。这是智能的“系统1”,一个庞大、无意识的模式仓库。
当我们向LLM提问时,就像是向这片大海里撒网。
如果只是随意一撒(无引导的生成),我们大概率只能捞到最常见的“鱼”,也就是模型预训练数据中最普遍、最可能的回答。这正是LLM产生“幻觉”或给出平庸答案的原因。

而真正的推理和规划,则像是一次目标明确的“捕鱼”行动。我们需要精良的渔具:诱饵(Baiting)和渔网(Filtering)。
-
诱饵:通过上下文、示例、工具输出等“语义锚点”,吸引我们想要的“特定鱼群”(目标概念)。
-
渔网:通过约束和验证,过滤掉无关的杂鱼,确保捕获的是我们真正需要的目标。
这套渔具,就是论文所说的“缺失层”——协调层(Coordination Layer)。它扮演着智能的“系统2”角色,负责选择、约束和组合大海中的模式,从而实现目标导向的行为。
因此,问题不在于海洋(LLM)本身,而在于我们是否拥有足够好的渔具和捕鱼技巧。
UCCT理论:用一个公式定义“推理”的相变
为了让这个“协调层”不只是一个哲学概念,研究者提出了一个名为统一上下文控制理论(Unified Contextual Control Theory, UCCT)的数学框架。
UCCT的核心观点是,从无目标的模式匹配到有目标的推理,并非一个渐进的过程,而是一个类似物理学中“相变”的突变过程。就像水在0℃会瞬间结冰一样,当外部引导的强度跨过一个临界点时,LLM的行为也会发生质的飞跃。
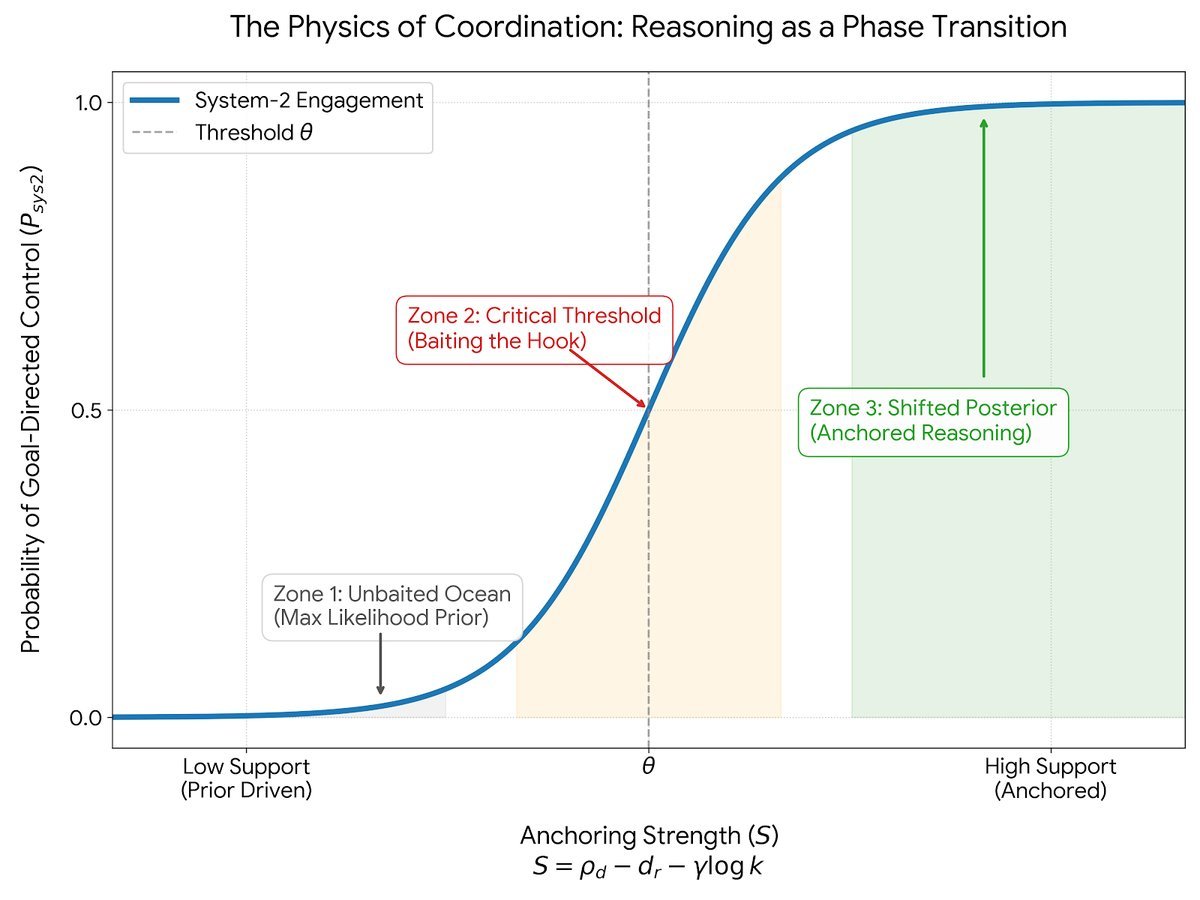
这个相变过程可以用一个简洁的锚定强度(Anchoring Strength)公式来描述:
\[S = \rho_{d} - d_{r} - \gamma\log k\]这个公式看起来很学术,但每个部分都对应着非常直观的概念:
-
$S$ (Anchoring Strength):最终的锚定强度得分。当$S$超过某个任务的临界阈值$\theta$时,系统就从“模式匹配”切换到“推理”状态。
-
$\rho_{d}$ (Effective Support):有效支持度。可以理解为你的“诱饵”有多香。上下文、示例和检索到的信息越是清晰、一致,这个值就越高,越能吸引到正确的“鱼”。
-
$d_{r}$ (Representational Mismatch):表征不匹配度。你的目标和LLM的“本能”(预训练知识)有多大冲突。如果你想让模型把“减号”当“加号”用,这个冲突值就会很高,锚定难度就大。
-
$\gamma\log k$ (Adaptive Regularizer):自适应正则化项。这代表了“捕鱼的成本”。$k$是你的“锚定预算”,比如上下文的长度、检索的文档数量。这个惩罚项意味着,我们不能无限制地堆砌上下文,因为过多的信息可能会稀释信号,增加噪声。高效的智能必须在有限的资源下解决问题。
简单来说,UCCT理论告诉我们:推理 = 强有力的引导 - 内部知识的冲突 - 使用过多信息的成本。
只要我们能让锚定强度$S$足够高,LLM就能被“驯服”,从一个随波逐流的“模式海洋”变成一个可以精确控制的“推理引擎”。
MACI架构:如何构建“协调层”
理论必须落地。论文基于UCCT,提出了一个名为MACI(Modulated Agent Coordination Infrastructure)的系统架构蓝图,展示了如何具体构建这个“协调层”。
MACI不是一个单一的模型,而是一个由多个Agent(智能体)组成的协作系统,它实现了“捕鱼”的全过程:
-
行为调制辩论(Behavior-modulated Debate):这相当于“撒诱饵”。系统会派出多个Agent,围绕一个问题进行辩论。这种辩论不是漫无目的的,而是被“锚定信号”所调制的。当系统发现分歧或不确定性时,它会引导Agent去探索更多可能性或寻求外部证据。
-
苏格拉底式评审(Socratic Judging):这是“筛选渔网”。一个独立的“评审”Agent(论文中称为CRIT)负责评估辩论的质量。它不关心最终答案是什么,而是评判论证过程是否合理、证据是否充分、逻辑是否严谨。这确保了捕获的“鱼”是高质量的。
-
事务性记忆(Transactional Memory):这是“鱼舱”。系统拥有一个记忆模块,可以记录和管理辩论过程中的状态、结论和验证结果。这使得多步推理、错误修正和状态回滚成为可能。
通过这套机制,MACI将单个LLM的生成能力,提升到了一个可控、可验证、更可靠的系统级推理能力。
结论:AGI之路,穿过LLM而非绕过
这篇论文最核心的贡献,是为当前关于LLM的激烈争论提供了一个全新的、更具建设性的视角。
它告诉我们,与其争论LLM是不是AGI的终点,不如将LLM视为一个极其强大的、包含了世界模式的“系统1”基座。未来的研究重点,不应是抛弃LLM去寻找“更好的东西”,而应该是:
我们应该如何设计和优化“协调层”,从而最有效地驾驭LLM这个强大的模式海洋?
这篇论文将许多看似零散的技术(如多智能体辩论、CoT、RAG、自我批判)统一到了一个清晰的理论框架(UCCT)之下,并指明了可量化的优化方向。
AGI的道路或许依然漫长,但这篇论文无疑点亮了一盏重要的指路明灯:通往AGI的道路,需要穿过LLM,而不是绕过它们。