强化学习“另辟蹊径”:避开90%关键参数,模型推理能力竟能大幅提升
当一个AI模型在数学和编程等复杂推理任务上取得巨大进步时,我们通常会认为它的内部参数发生了翻天覆地的变化。然而,一个令人困惑的现象出现了:通过强化学习(RL)微调的模型,其参数改动极少,有时高达92%的权重都纹丝不动。
论文标题:The Path Not Taken: RLVR Provably Learns Off the Principals ArXiv URL:http://arxiv.org/abs/2511.08567v1
这就像一位顶尖高手,仅靠微调几个发力点,武功就精进了一大截。
与此形成鲜明对比的是,传统的监督微调(SFT)则像是一场“大手术”,参数改动非常密集。为什么成本高昂、效果显著的强化学习,反而表现得如此“吝啬”?最近一篇名为《The Path Not Taken》的论文,首次揭开了这个谜团的神秘面纱。
研究发现,所谓的“稀疏更新”其实只是表象。其背后隐藏着一个由预训练模型自身“几何结构”决定的优化偏好。强化学习并非随机“偷懒”,而是在有意识地“另辟蹊径”,走一条与SFT截然不同的道路。
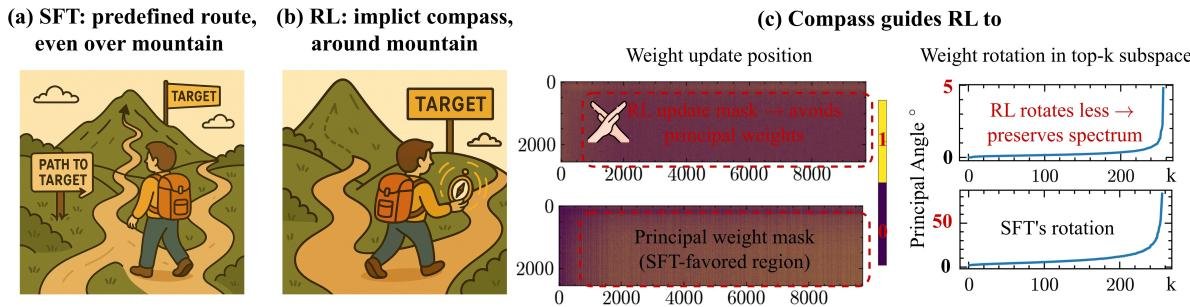
上图形象地展示了两者的区别:SFT像是在老师(外部数据)的指导下,费力地“翻山越岭”(在高曲率区域更新);而RLVR则像带着一个“隐形罗盘”(模型内生的优化偏好),巧妙地绕开山脉,选择了一条平坦的“小径”(在低曲率区域更新)。
“三道门”理论:解密RL的独特路径
那么,这个“隐形罗盘”究竟是如何工作的?论文提出了一个精妙的“三道门”(Three-Gate Theory)理论,系统地解释了RL独特的优化动力学。
第一道门:KL锚定(KL Anchor)
强化学习的目标函数中通常包含一个KL散度项 $D_{\mathrm{KL}}(\pi_{\theta} \parallel \pi_{ref})$。
它的作用就像一根“缰绳”,在优化的每一步都将新模型“拴”在旧模型附近,防止其偏离太远。这道门确保了RL的更新是小范围、渐进式的,限制了参数变化的幅度。
第二道门:模型几何“罗盘”(Model Geometry)
有了“缰绳”限制幅度,但更新的方向由谁决定?这就是第二道门——模型几何的作用。
预训练好的大模型,其参数空间并非一片混沌,而是形成了高度结构化的“地形”,有“山峰”(高曲率区域)和“山谷”(低曲率区域)。“山峰”区域的参数,论文称之为主权重(principal weights),它们对模型的结构至关重要,如同建筑的承重墙。
在KL缰绳的约束下,优化算法会本能地选择阻力最小的路径,即沿着平坦的“山谷”前进。这意味着,RL更新会被这片“地形”自然地引导,避开那些陡峭的“主权重”区域,从而决定了参数更新的方向。这解释了为什么这种优化偏好是“模型内生”的——罗盘就藏在模型自己的结构里。
第三道门:精度“滤镜”(Precision)
现代模型训练普遍使用 \(bfloat16\) 这种低精度浮点数格式。它的特点是精度有限,尤其是在表示微小变化时。
当RL在非优选区域做出极其微小的更新时,这些更新可能因为太小而无法在 \(bfloat16\) 格式下表示出来,最终被“四舍五入”为零。这道门就像一个滤镜,它放大了前两道门造成的效果,使得本就倾向于“小修小补”的RL更新,在表面上看起来更加稀疏。
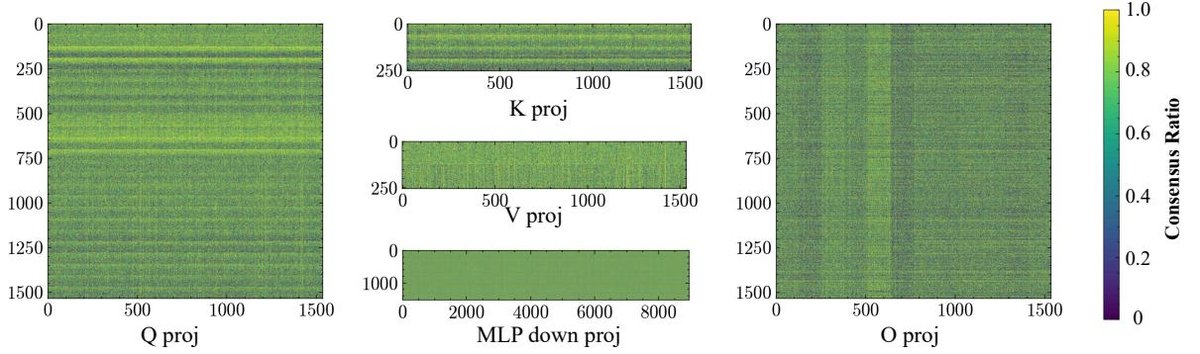 上图展示了不同RL算法在同一模型上的更新“足迹”,可见其高度一致性,证明了这种偏好源于模型自身。
上图展示了不同RL算法在同一模型上的更新“足迹”,可见其高度一致性,证明了这种偏好源于模型自身。
SFT与RLVR:分道扬镳的优化之路
理论需要实验的支撑。研究者通过一系列精巧的实验,证实了RLVR与SFT在参数空间中确实“分道扬镳”。
1. RLVR保留光谱几何,SFT扭曲它
模型的权重矩阵可以被分解为奇异值和奇异向量,这构成了模型的“光谱几何”(spectral geometry),可理解为模型的“骨架”。
实验显示,RLVR微调后,模型的“骨架”几乎保持不变,奇异值和主子空间旋转都非常小。而SFT则对“骨架”进行了大刀阔斧的改造,导致光谱结构发生显著扭曲。
 RLVR(左)的光谱漂移和子空间旋转远小于SFT(右)。
RLVR(左)的光谱漂移和子空间旋转远小于SFT(右)。
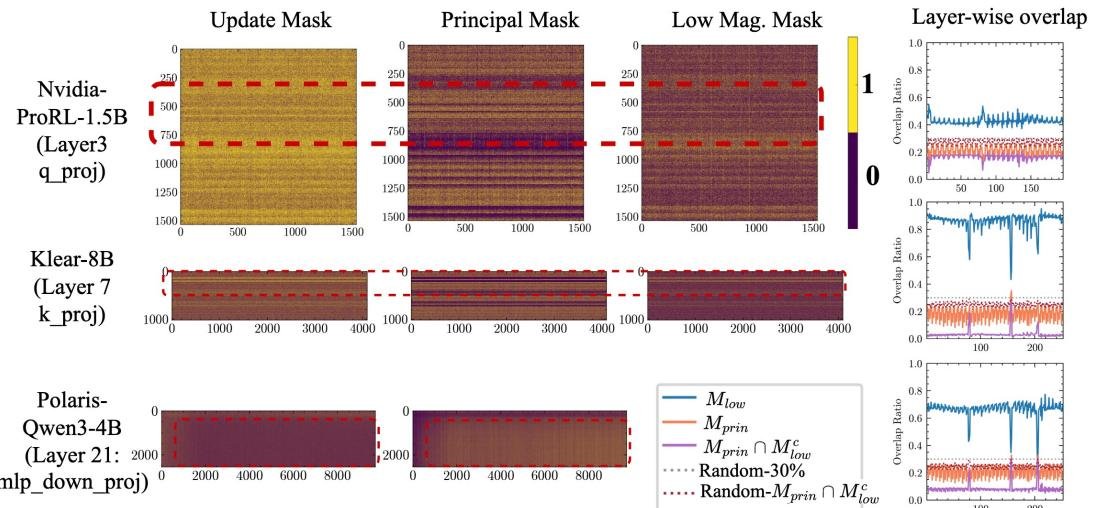
2. RLVR避开主权重,SFT直击主权重
这是最核心的发现。通过奇异值分解(SVD)识别出模型的“主权重”(即那些最重要的参数)后,研究发现:
- RLVR的更新区域与主权重区域的重合度非常低。
- SFT的更新则高度集中在主权重区域。
这有力地证明了RLVR在“另辟蹊径”,而SFT则在“正面攻坚”。
3. 破坏几何结构,优化偏好随之消失
为了建立因果关系,研究者做了一个巧妙的实验:他们通过正交旋转等数学变换“打乱”模型特定层的几何结构,但保持其功能不变。
结果,之前那种高度一致的RL更新模式消失了。这就像把罗盘的磁针打乱,它便无法再指向正确的方向。这决定性地证明了,模型几何结构正是引导RL更新方向的“罗盘”本身。
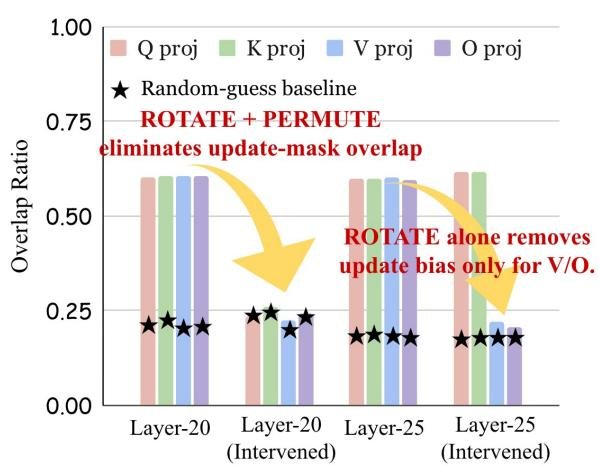 在打乱几何结构(Rotate, Permute)后,两次独立RL运行的更新重合度(Overlap)显著下降。
在打乱几何结构(Rotate, Permute)后,两次独立RL运行的更新重合度(Overlap)显著下降。
对PEFT的启示:SFT的老地图无法导航RL的新大陆
这一发现不仅仅是理论上的突破,它对实践有着极其重要的指导意义。它意味着,我们不能再想当然地将为SFT设计的参数高效微调(PEFT)方法,如LoRA及其变体,直接套用在RL上。
例如,一些先进的LoRA变体(如PiSSA)的设计初衷就是为了更有效地作用于主权重。这在SFT中是合理的,但在RL场景下,这恰恰与RL“避开主权重”的内在机制背道而驰。
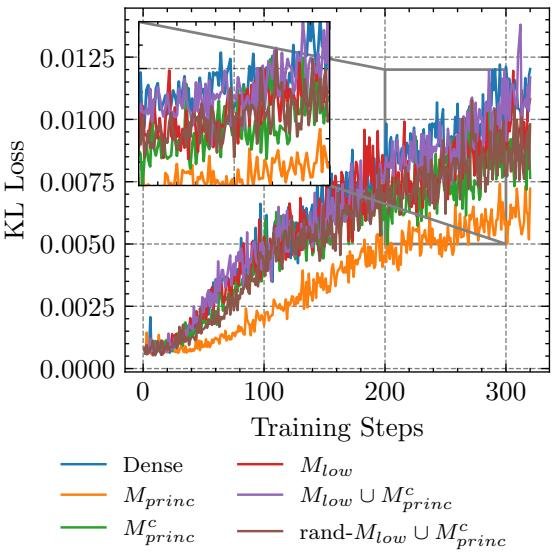 上图显示,在RL微调中,仅更新“非主权重”(Off-Principal)的稀疏方案,其学习轨迹(蓝色虚线)与全量微调(黑色实线)最为接近。而更新“主权重”(Principal)的方案(红色)则效果最差。
上图显示,在RL微调中,仅更新“非主权重”(Off-Principal)的稀疏方案,其学习轨迹(蓝色虚线)与全量微调(黑色实线)最为接近。而更新“主权重”(Principal)的方案(红色)则效果最差。
实验证实了这一点。在RL微调中,专门针对非主权重进行稀疏更新,能以更少的参数紧密追踪全量微调的效果。相反,那些旨在影响主权重的PEFT方法(如PiSSA或高学习率的LoRA),在RL任务中不仅没有带来优势,甚至可能导致训练崩溃。
结论
这篇论文为我们揭示了强化学习微调的一个深刻机制:它并非通过大刀阔斧的改变,而是借助模型自身的几何结构“罗盘”,走上了一条“避开主路、另辟蹊径”的优化捷径。
这一“白盒”视角颠覆了我们对RL的传统认知,并明确指出:SFT时代的PEFT“老地图”已无法导航RL这片“新大陆”。未来,我们需要为RL量身打造全新的、能够感知并利用模型几何结构的参数高效算法。这不仅是技术的演进,更是我们从“知其然”到“知其所以然”的又一次飞跃。