The Two-Stage Decision-Sampling Hypothesis: Understanding the Emergence of Self-Reflection in RL-Trained LLMs
RL为何能让大模型“学会自省”?双阶段决策采样假说揭秘SFT的死穴

在大模型领域,一个令人困惑的现象长期存在:为什么经过强化学习(RL)训练的模型(如DeepSeek-R1、OpenAI o1)能够涌现出“自省”和“自我修正”的能力,而传统的监督微调(SFT)即使使用了包含大量思维链(CoT)的数据,却往往只是在模仿“思考的语气”,很难真正学会发现错误并改正?
ArXiv URL:http://arxiv.org/abs/2601.01580v1
亚利桑那州立大学、上海人工智能实验室和上海科技大学的研究团队提出了一项极具洞察力的理论——双阶段决策采样(Two-Stage Decision-Sampling, DS)假说。该研究从梯度的视角,一针见血地指出了SFT在培养“思考模型”时的致命缺陷,并解释了为何RL才是通向真正智能的必经之路。
核心洞察:一个大脑,两种功能
虽然我们在训练大模型时,通常将其视为一个统一的“下一个Token预测器”,但该研究提出,为了理解自省能力的涌现,我们在概念上必须将模型的策略分解为两个功能截然不同的部分:
-
采样策略($\pi_{sample}$):负责生成具体的候选答案或推理步骤(即“怎么做”)。
-
决策策略($\pi_{d}$):负责验证当前的推理,并决定是“停止并输出”还是“拒绝并重试”(即“做得对不对”)。
论文的核心观点在于:RL之所以成功,是因为它能同时优化这两个部分;而SFT之所以失败,是因为其优化目标导致了梯度的“分配不均”。
梯度归因属性:RL与SFT的本质分歧
为了量化这一机制,作者引入了梯度归因属性(Gradient Attribution Property)的概念。这不仅仅是数学上的推导,更是理解模型行为的关键钥匙。
1. RL的“平衡梯度归因”
在强化学习(特别是使用GRPO等算法)中,模型通常通过简单的代理奖励(Surrogate Reward)进行优化。研究证明,这种奖励机制具有平衡梯度归因(Balanced Gradient Attribution)的特性。
简单来说,当模型最终获得一个正向或负向的奖励(例如答案正确与否)时,这个信号会通过数学上的折扣因子,对称地传导给“负责生成”的 $\pi_{sample}$ 和“负责判断”的 $\pi_{d}$。这意味着,如果模型答错了,RL不仅会告诉生成部分“你算错了”,还会告诉决策部分“你不该在这个时候停止,你应该检查一下”。
2. SFT与KL惩罚的“不平衡梯度归因”
相比之下,SFT(以及RL中常用的KL散度惩罚)则表现出不平衡梯度归因(Unbalanced Gradient Attribution)。
SFT本质上是在最小化预测Token与参考Token之间的距离。由于Token数量(长度)在计算中占据主导地位,这种目标函数会产生一种基于长度的加权效应:
-
它会对 $\pi_{sample}$ 施加巨大的约束,迫使模型严格模仿参考答案的措辞和格式。
-
然而,它对 $\pi_{d}$ 的优化却微乎其微。
这就解释了为什么SFT模型往往只是“鹦鹉学舌”:它们学会了生成看起来像推理过程的文本(因为 $\pi_{sample}$ 被强力优化了),但并没有学会何时该真正地停下来反思(因为 $\pi_{d}$ 处于欠优化状态)。
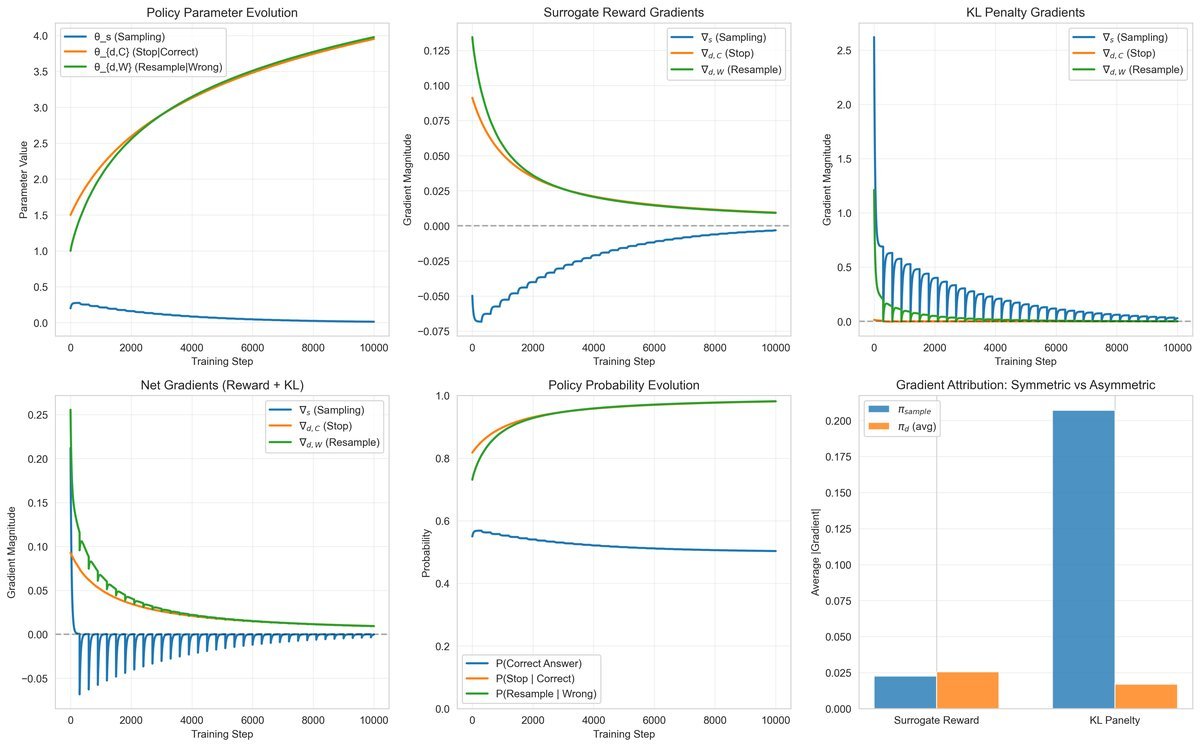
上图展示了模拟结果:RL(Surrogate Reward)能同时提升两个策略的参数,而KL惩罚导致决策策略($\pi_d$)的参数几乎无法更新。
实验验证:RL到底强在哪里?
为了验证这一理论,研究团队在算术推理任务上进行了对比实验。他们设计了一种巧妙的校准方法,将模型的整体性能解耦为“采样准确率”和“决策准确率”。
实验结果令人震惊:
-
RL的提升主要来自决策能力:经过RL训练的模型,其生成正确答案的能力($\pi_{sample}$)提升并不大,但其拒绝错误答案并重试的能力($\pi_{d}$)却有了质的飞跃。
-
SFT的“回声室效应”:SFT模型虽然在简单任务上表现尚可,但在面对分布外(OOD)的难题时,其决策能力迅速崩溃。即使模型生成了错误的答案,它也无法识别,只会盲目自信地输出。
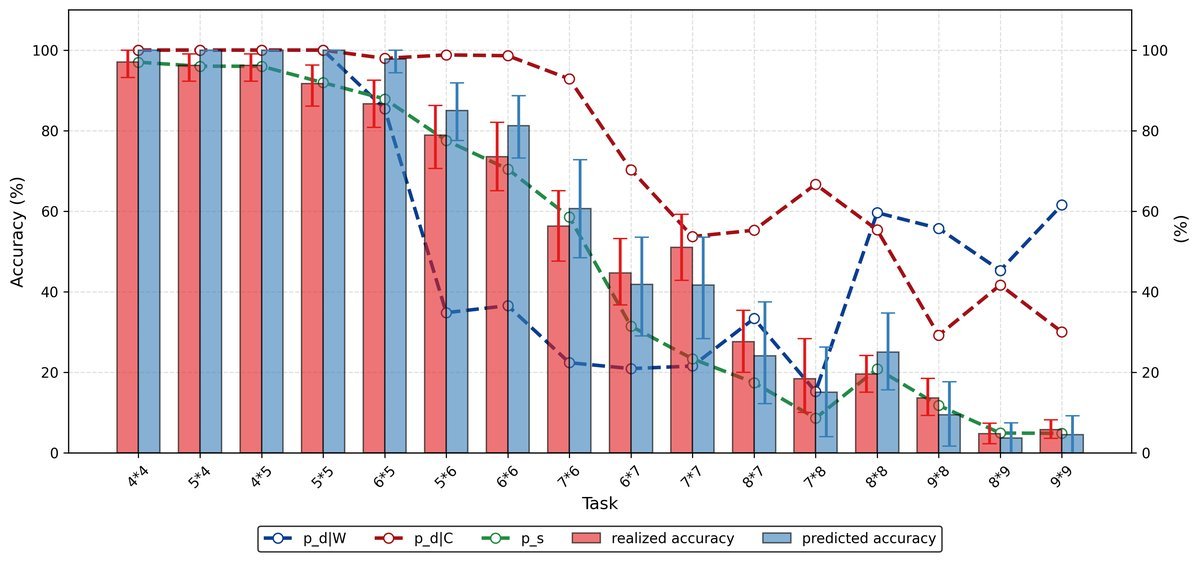
RL模型的解剖分析:注意右侧的 $p_{d \mid W}$(错误时重试的概率)保持在较高水平,说明模型学会了“知错能改”。
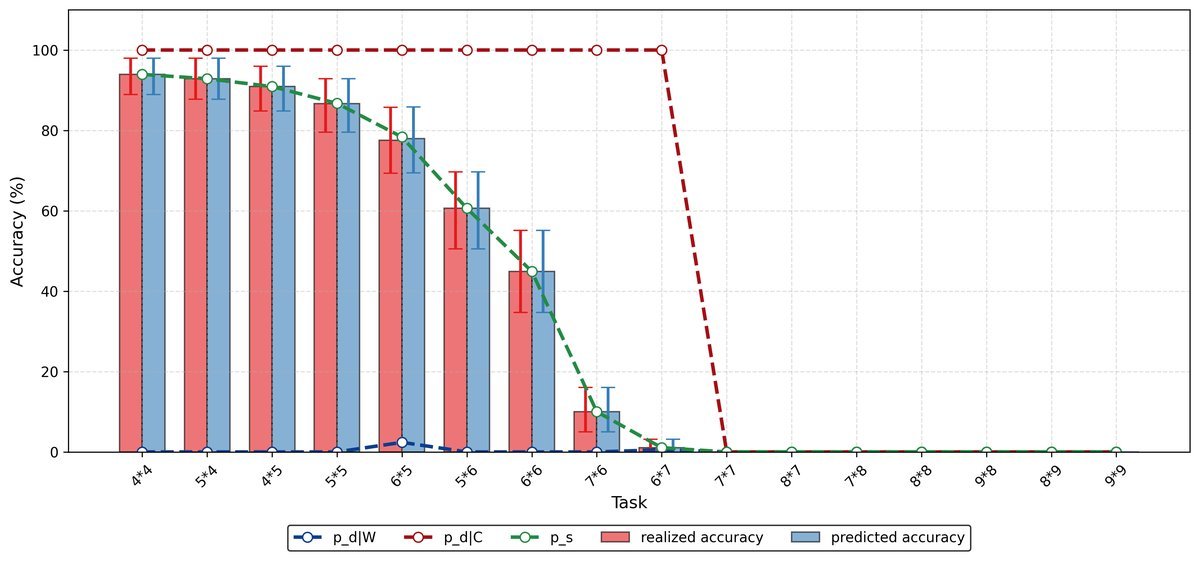
SFT模型的解剖分析:在任务变难时(横轴向右),$p_{d \mid W}$ 迅速跌至零。模型失去了判断对错的能力,陷入了“回声室”。
结论:通往Thinking Model的必经之路
这项研究为我们理解DeepSeek-R1等推理模型的成功提供了坚实的理论基础。它告诉我们,自省能力并非魔法,而是梯度流动的必然结果。
SFT模型之所以无法学会真正的自我修正,是因为其训练目标在数学结构上就注定了它只能模仿“思考的皮毛”(生成的文本),而无法触及“思考的灵魂”(对状态的价值判断)。
要想训练出真正具有逻辑推理和自我修正能力的AI,我们必须超越单纯的监督学习,利用强化学习的平衡梯度归因特性,让模型在不断的试错中,不仅学会“怎么说”,更学会“如何判断”。这正是从“语言模型”向“思维模型”进化的关键一步。