只需数百样本,性能反超SOTA!蚂蚁Thinker教LLM如何“分层思考”

大模型在应对复杂问题时,常常像一个知识渊博但思维混乱的学生。它们在需要深度搜索和多步推理的任务面前,要么逻辑跳跃,要么效率低下,甚至自信地“一本正经胡说八道”。
论文标题:Thinker: Training LLMs in Hierarchical Thinking for Deep Search via Multi-Turn Interaction
ArXiv URL:http://arxiv.org/abs/2511.07943v1
许多研究尝试通过强化学习(RL)来训练模型进行深度搜索,但这就像让学生“自由发挥”,整个解题过程难以监督,逻辑严谨性也无从保证。
有没有办法让大模型像人类专家一样,先拆解问题,再逐个击破呢?
来自蚂蚁集团、同济大学和浙江大学的研究者们给出了答案。他们提出了一个名为 Thinker 的模型,它能通过分层思考和多轮交互,让大模型的推理过程变得既可监督又可验证,彻底告别了以往的“混乱搜索”模式。
核心框架:分层思考,先广后深
Thinker 的核心思想借鉴了人类解决复杂问题的模式:广度分解与深度求解(Breadth Decomposition and Depth Solving)。
面对一个复杂问题,Thinker 不会急于一头扎进去寻找答案,而是像项目经理一样,先在“广度”上将其拆解成一系列可以独立解决的、原子化的子问题。
例如,对于问题:“《Hit Parade Of 1947》和《Khiladi 420》这两部电影,哪一部的导演先去世?”
Thinker 会将其分解为:
-
《Hit Parade Of 1947》的导演是谁?
-
这位导演(#1)何时去世?
-
《Khiladi 420》的导演是谁?
-
这位导演(#3)何时去世?
-
根据#2和#4的结果,哪位导演先去世,他导演的是哪部电影?
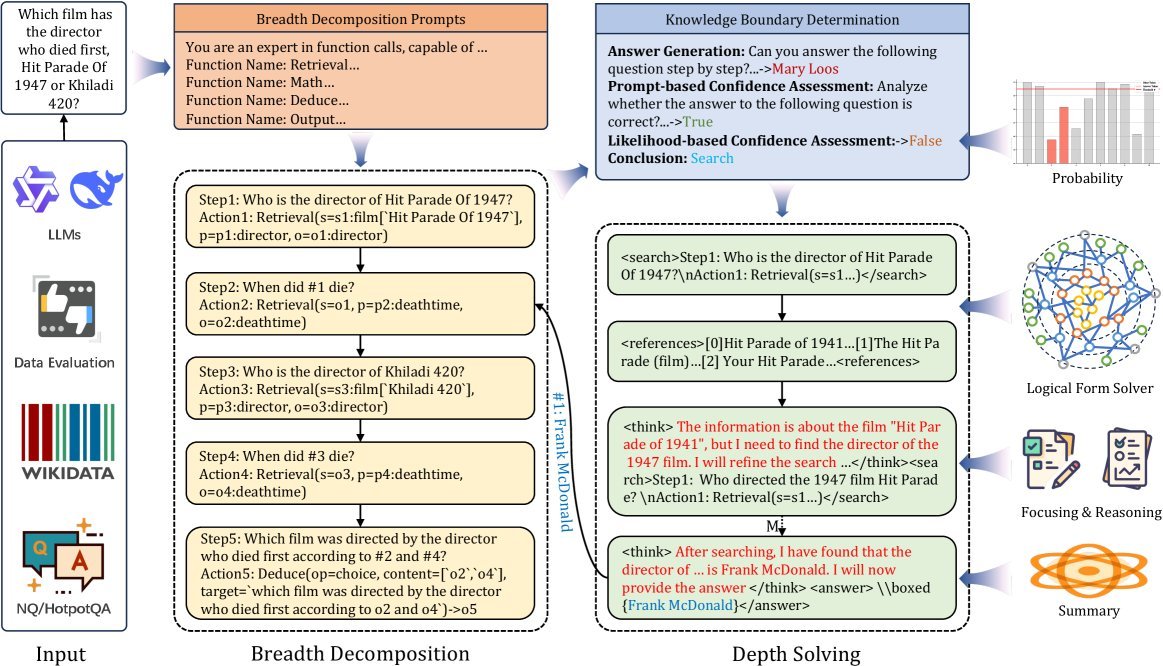
图注:Thinker模型的分层思考与多轮交互推理概览
完成广度分解后,模型进入“深度求解”阶段,针对每一个子问题进行独立解决。这个过程可能需要进行0到多次的检索操作,直到找到答案为止。
创新一:知识边界判断,避免无效搜索
是不是所有问题都需要从外部知识库里捞一遍答案呢?当然不是。
很多信息早已存在于大模型的参数知识中。每次都进行检索不仅浪费计算资源,还可能引入噪声,导致模型产生幻觉。
为此,Thinker 引入了一个巧妙的机制:知识边界判断(Knowledge Boundary Determination)。
它采用“先生成,后评估”的策略。模型首先尝试用自己的内部知识直接回答子问题,然后通过一个混合置信度评估体系(结合提示评估和似然度评估)来判断这个答案的可靠性。
只有当模型对自己的答案“缺乏自信”时,才会启动外部的深度搜索。实验表明,该模块能显著减少不必要的检索操作。
创新二:双重表示,兼容并包
以往的深度搜索方法大多只处理纯文本,这使得它们难以有效利用高质量的结构化知识库(如知识图谱)。
Thinker 独创性地为每个子问题设计了双重表示(Dual Representation):
-
自然语言(Step):人类可读的问题描述,如“Who is the director of Hit Parade Of 1947?”
-
逻辑函数(Action):机器可执行的结构化查询,如 \(Retrieval(s=s1:film[‘Hit Parade Of 1947’], p=p1:director, o=o1:director)\)
这种设计带来了两大好处:
-
灵活性:面对普通搜索引擎,可以直接使用 Step 中的自然语言进行检索;面对知识图谱等结构化数据源,则可以执行 Action 中的逻辑函数。
-
逻辑性:通过变量(如上例中的 \(o1\)),子问题之间的依赖关系得以清晰传递,确保了整个推理链条的逻辑严谨性和稳定性。
实验效果:小样本撬动惊人性能
是骡子是马,拉出来遛遛。研究者在7个主流问答数据集上对 Thinker 进行了全面评测。
结果显示,Thinker 显著优于现有基线模型。尤其在3B参数规模的模型上,Thinker 的平均性能比当时的SOTA方法 ReSearch 高出 7.9%。在7B模型上,平均EM得分也高出 4.1%。
图注:Thinker在不同模型规模上均表现出色
更令人惊讶的是 Thinker 的样本效率。研究发现,仅用几百个训练样本(总数据的1%),Thinker 的性能就已经能与经过完整训练的SOTA方法相媲美。这大大降低了训练成本,展示了其强大的学习能力。
此外,消融实验证明,“深度求解”模块是性能提升的关键,而当 Thinker 与支持知识图谱的KAG框架结合时,其“双重表示”的优势被完全激活,性能得到进一步飞跃。
总结
Thinker 的提出,为解决大模型在复杂推理任务中的“逻辑混乱”问题提供了一个优雅且高效的方案。
它通过模拟人类的分层思考模式,并引入知识边界判断和双重表示等创新机制,不仅让模型的推理过程变得清晰、可控,更在性能和效率上取得了显著突破。
这项工作不仅展示了一条通往更强大、更可靠的AI推理能力的路径,也启发我们:要让机器更好地思考,或许最好的方法就是先教会它如何“组织思想”。