Top 10 Open Challenges Steering the Future of Diffusion Language Model and Its Variants
扩散模型能否颠覆GPT?华为诺亚详解阻碍DLM爆发的十大核心挑战

当下的 AI 领域,大语言模型(Large Language Models, LLMs)几乎等同于自回归(Auto-Regressive, AR)架构。无论是 GPT-4 还是 DeepSeek,它们生成文本的方式就像泥瓦匠砌墙——“一块砖接一块砖”地按顺序堆砌。虽然这种模式取得了巨大成功,但它天生存在一个缺陷:缺乏全局视野,一旦“砌歪了”很难回头修改。
ArXiv URL:http://arxiv.org/abs/2601.14041v1
扩散语言模型(Diffusion Language Models, DLMs)提供了一种极具诱惑力的替代方案:它将文本生成视为一个全局的、双向的去噪过程,就像雕塑家在一块璞玉上通过反复打磨,最终呈现出完美的艺术品。
然而,尽管 DLMs 理论上更优,为何迟迟没有迎来属于它的“GPT-4 时刻”?华为诺亚方舟实验室联合北大、南洋理工大学发布的最新综述指出,这是因为我们还在用旧时代的“AR 基础设施”来套新时代的“扩散算法”。本文将深入解读阻碍 DLMs 爆发的十大核心挑战,以及通往下一代 AI 的战略路线图。
雕塑家 vs. 泥瓦匠:范式的转移
在深入挑战之前,我们需要从数学本质上理解两者的区别。
传统的 AR 模型遵循因果逻辑,其概率分布定义为:
\[p_{\theta}(x)=p_{\theta}(x^{1})\prod_{n=2}^{N}p_{\theta}(x^{n}\mid x^{1},\cdots,x^{n-1})\]这意味着生成第 $n$ 个词时,只能看到前 $n-1$ 个词。
而 DLMs 则采用双向去噪的公式:
\[p_{\theta}(\mathbf{x})=\sum_{\mathbf{x_{1:T}}\sim q}p(\mathbf{x_{T}})\prod_{t=1}^{T}p_{\theta}(\mathbf{x_{t-1}}\mid\mathbf{x_{t}})\]这意味着模型在每一步都能看到“全局”的信息,并对其进行细化。
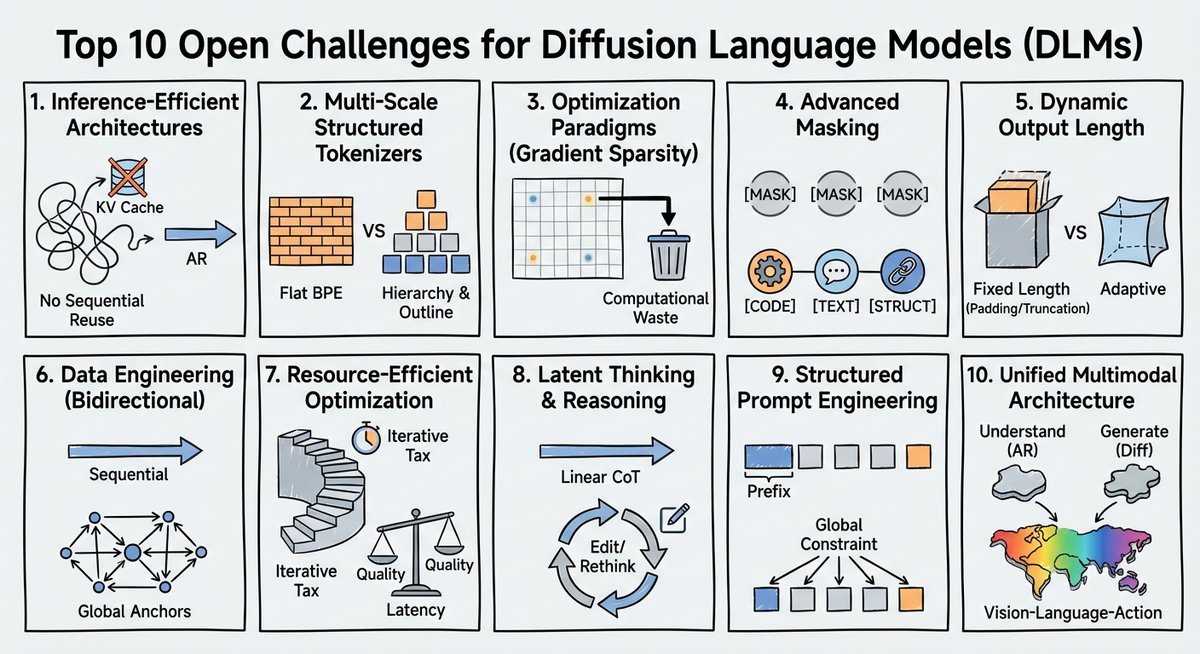
阻碍 DLMs 爆发的十大核心挑战
尽管愿景美好,但现实骨感。研究团队识别出了十个阻碍 DLMs 性能和扩展性的根本瓶颈。
1. 推理效率:被 AR 遗产拖累
目前的 DLMs 大多沿用了为 AR 优化的 Transformer 架构。AR 模型靠 KV Cache 复用计算,效率极高。但扩散过程是非顺序的,掩码位置随机跳跃,导致传统的 KV Cache 失效。如果没有原生的双向推理架构,DLMs 在长文本任务中将寸步难行。
2. 分词器的层级缺失
现有的 BPE 分词器是“扁平”的。但人类思考是分层级的:先有大纲(宏观),再有措辞(微观)。目前的 DLMs 被迫在同一粒度上处理所有信息,无法像人类那样高效分配计算资源——即先“雕刻”大轮廓,再“打磨”细节。
3. 梯度稀疏性危机
在预训练中,DLMs 通常只对长序列中一小部分被掩码的 Token 进行去噪。这意味着前向传播计算了所有 Token,但只有极少数贡献了梯度。这种“梯度稀疏”不仅浪费算力,还导致了预训练(随机掩码)与微调(全序列生成)之间的分布偏移。
4. 掩码机制过于粗糙
目前的 \([MASK]\) 标记太通用了。在代码中掩盖一个控制流操作符,与在散文中掩盖一个虚词,其恢复难度和逻辑重要性截然不同。缺乏结构化掩码(Structured Masking)机制,限制了模型对复杂逻辑的捕捉能力。
5. 输出长度的僵化
AR 模型可以通过 \(EOS\) 标记自然结束,但 DLMs 通常需要预定义输出长度。这导致了计算浪费:简单问题被强行拉长,复杂问题被截断。如何实现动态输出长度,是 DLMs 走向实用的关键。
6. 数据工程的错位
现有的数据大多是为 AR 策划的,强调顺序连贯性。而 DLMs 需要的是能强调结构关系和多点依赖的数据。缺乏“扩散原生”的数据集,使得 DLMs 难以习得全局语义锚点。
7. 资源优化的两难
虽然 DLMs 理论上支持并行生成,但多步去噪带来的“迭代税”使得其延迟往往高于同级 AR 模型。如何在去噪质量和计算成本之间找到平衡点,仍是未解之谜。
8. 潜在这个思考与迭代推理
目前的思维链(Chain-of-Thought, CoT)是线性的。但真正的深度思考往往是非线性的:提出假设、推翻、重写。DLMs 天生具备“重写”能力,但目前的 SFT 范式未能利用这一点,导致模型无法进行真正的潜在思考(Latent Thinking)。
9. 提示工程的缺失
传统的 Prefix Prompt 是因果模型的产物。对于双向的 DLMs,提示词应该像“脚手架”一样穿插在生成的全过程中。目前缺乏一套标准化的“扩散原生提示”框架。
10. 迈向统一的多模态架构
目前的 AI 领域是分裂的:理解任务用 AR,生成任务用扩散。终极目标是建立一个统一架构,将理解、生成和行动都视为同一流形上的去噪过程。
破局之路:四大战略支柱
为了跨越上述障碍,论文提出了一套从“适应 AR”转向“扩散原生”的战略路线图。
支柱一:基础设施与结构基础
我们需要重新设计非因果效率的架构。这包括多尺度分词器(Multi-scale Tokenizer),让高层 Token 代表段落级大纲,低层 Token 处理词法细节,模拟人类“先构思后写作”的过程。
支柱二:算法机制与优化
引入动态优化策略,例如从高掩码率(全局规划)逐渐过渡到低掩码率(局部精修)。同时,推广结构化掩码,使用如 \([LOGIC-MASK]\) 或 \([ENTITY-MASK]\) 等专用标记,引导模型关注不同的文本功能。
支柱三:认知推理与交互
放弃线性的 CoT,转向扩散原生 CoT。利用主动重掩码(Active Remasking)机制:模型在生成过程中自我检测低置信度区域,并主动“擦除”重写。这种内部反馈循环将赋予 AI 真正的自我修正能力。
支柱四:统一智能
构建扩散原生数据生态,标注数据中的“结构锚点”。最终目标是实现统一扩散主干,在视觉-语言-行动(VLA)模型中,将感知(高噪声去噪)和生成(低噪声去噪)统一在同一个数学框架下。
结论
从“砌砖”到“雕塑”的转变,不仅仅是算法的更迭,更是向更高级智能形式的迈进。
目前的自回归模型虽然强大,但其“因果视界”限制了其结构性前瞻和自我纠错的能力。扩散语言模型通过引入全局视野和迭代优化的机制,为解决复杂推理和多模态融合提供了新的希望。
正如论文所言,一旦解决了推理延迟和优化稳定性的瓶颈,DLMs 很可能成为下一代 AI 的基石——它不再只是预测下一个词,而是在精心雕琢整个思维的结构。