AI Agent协作双刃剑:性能提升81%,错误放大17倍!DeepMind发布首个量化法则

“三个臭皮匠,顶个诸葛亮”,在AI Agent领域,这句古老的谚语似乎也成了金科玉律。许多人相信,通过“群聊”式的多Agent协作,就能解决更复杂的问题。
ArXiv URL:http://arxiv.org/abs/2512.08296v1
然而,事实果真如此吗?
来自Google DeepMind、谷歌研究院和MIT的最新研究,为这个火热的领域浇上了一盆“科学”的冷水。研究表明,盲目增加Agent数量不仅可能毫无助益,甚至会带来灾难性后果:在某些任务上,多Agent协作竟能让错误率放大17.2倍!
这篇名为《迈向Agent系统扩展的科学》(Towards a Science of Scaling Agent Systems)的论文,首次为我们揭示了AI Agent协作背后那把锋利的“双刃剑”。
“人多”不一定“力量大”:协作的代价
以往,评估多Agent系统(Multi-Agent Systems, MAS)的研究往往将不同架构、不同工具甚至不同算力预算的系统混为一谈,这使得我们很难判断性能提升究竟是来自协作本身,还是其他因素。
为了厘清真相,该研究设计了一套极其严格的对照实验。
研究团队定义了五种经典的Agent架构:
-
单Agent系统(Single-Agent System, SAS):只有一个Agent单打独斗。
-
独立MAS:多个Agent独立工作,最后汇总结果。
-
中心化MAS:一个“指挥官”Agent负责分解任务、分发给“下属”并整合结果。
-
去中心化MAS:多个Agent通过“辩论”或“投票”等方式进行点对点沟通,共同决策。
-
混合MAS:结合了中心化和去中心化的结构。
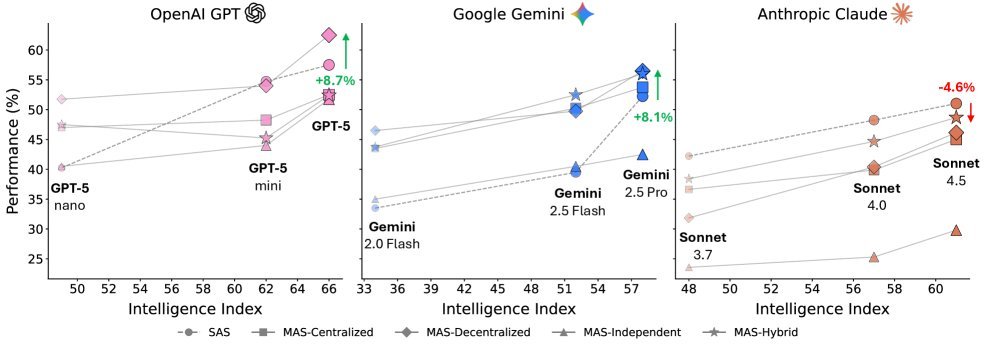
图1:不同架构下,Agent系统性能随模型智能水平的扩展情况
他们让这五种架构,搭载三种不同能力水平的LLM系列(来自OpenAI, Google, Anthropic),在四个完全不同的任务场景(金融分析、网页浏览、游戏规划、工作流执行)下进行大比拼。
最关键的是,所有实验配置都遵循了严格的“控制变量法”:相同的任务、相同的工具、相同的Token预算。
这样一来,性能的差异就能直接归因于协作架构本身。总计180种配置的庞大实验,终于让我们得以一窥Agent协作的底层规律。
三大发现:颠覆你的直觉
这项研究得出了三个颠覆性的核心发现,它们共同构成了一套预测Agent协作效果的量化法则。
1. 工具-协作权衡:工具越复杂,协作越吃力
你可能会认为,任务越复杂、需要用的工具越多,就越应该让多个Agent来分担。
然而研究发现,在固定的计算预算(Token预算)下,事实恰恰相反。
对于需要频繁使用多种工具的重任务(比如涉及16个工具的软件工程任务),多Agent系统的表现反而更差。这是因为总预算被分散到每个Agent头上,导致单个Agent没有足够的“上下文空间”来有效规划和调用复杂的工具链。
这种现象被称为工具-协作权衡(tool-coordination trade-off)。简单说,就是协作带来的沟通开销,侵占了本该用于执行核心任务的宝贵资源。
2. 能力饱和:当“单兵”足够强时,团队是累赘
研究发现了一个有趣的“能力饱和”现象。
当单个Agent(SAS)在某个任务上的表现已经超过一个经验阈值(大约45%的成功率)时,引入多Agent协作带来的收益会急剧下降,甚至变为负数($\beta{=}{-}0.408$, $p{<}0.001$)。
这意味着,对于那些“中等难度”且单个强大模型已经能处理得不错的任务,强行组建团队的沟通成本和复杂性,会完全抵消掉协作可能带来的微小好处。
“人多力量大”的前提是,“人”还不够强。
3. 架构决定命运:错误放大还是抑制?
这是本次研究中最令人警醒的发现。
协作不仅可能不产生价值,还可能成为错误的“放大器”。
研究量化了不同架构下的错误放大(error amplification)效应:
-
独立Agent系统:由于Agent之间缺乏沟通和验证,一个Agent的错误会未经检查地传播到最终结果中。这种架构下的错误被放大了惊人的17.2倍!
-
中心化Agent系统:由于存在一个“指挥官”作为验证瓶颈,它可以在整合结果前审查各个子Agent的输出,从而有效遏制错误。即便如此,错误依然被放大了4.4倍。
这个发现告诉我们,沟通机制的设计至关重要。缺乏有效监督的“各自为战”,是滋生错误的温床。
架构与任务的“天作之合”
那么,多Agent协作究竟何时才有效?答案是:架构必须与任务特性精准匹配。
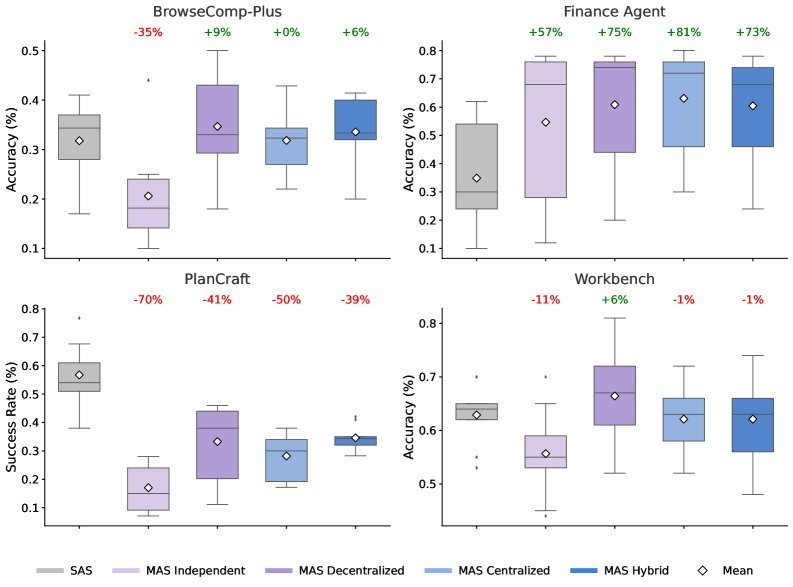
图2:不同任务下,单Agent与多Agent系统的性能对比
上图清晰地展示了这种任务依赖性:
-
金融推理任务:这类任务可以被清晰地分解为多个并行的子任务。中心化架构在此大放异彩,性能相比单Agent提升了80.9%。指挥官模式完美适配。
-
动态网页浏览:任务充满不确定性,需要多路探索。去中心化架构表现最佳,通过并行探索带来了9.2%的性能提升。
-
序列规划任务:这类任务需要严格的逻辑顺序,一步错、步步错。结果,所有多Agent变体的表现都惨不忍睹,性能下降了39%至70%!协作带来的沟通开销和上下文碎片化,严重干扰了连贯的推理链。
迈向Agent的“科学”
这项研究最重要的贡献,是提出了一个可预测的量化框架。
研究团队基于实验数据,构建了一个能够解释超过一半性能差异($R^{2}{=}0.513$)的预测模型。更厉害的是,这个模型在预测未知任务的最佳架构时,准确率高达87%。
这意味着,未来我们在设计AI Agent系统时,或许可以告别“拍脑袋”式的直觉和试错。
我们可以先测量任务的关键属性(如可分解性、工具复杂性、序列依赖性),然后利用科学模型来选择最优的Agent架构。
这标志着我们正从构建Agent的“艺术”时代,迈向理解Agent的“科学”时代。下次当你再想用“群聊”解决问题时,不妨先问一句:这真的科学吗?