Towards Automated Kernel Generation in the Era of LLMs
告别手写CUDA噩梦:LLM+Agent自动生成高性能Kernel技术全景

在当今的AI大模型时代,算力就是黄金。但你是否知道,昂贵的GPU集群往往并没有被“吃干抹净”?
ArXiv URL:http://arxiv.org/abs/2601.15727v1
现代AI系统的性能瓶颈,很大程度上不再取决于硬件的峰值算力,而在于底层的算子(Kernel)质量。将高层的算法逻辑(如矩阵乘法、Attention)翻译成底层硬件能理解的高效指令,是一项被称为“黑色艺术”的工程挑战。它要求工程师既懂算法,又精通硬件架构(内存层级、并行度、指令集)。正因如此,高性能Kernel的开发往往周期长、门槛高,且难以跨硬件迁移。
但如果,我们能让AI自己来写这些底层代码呢?
最近,来自智源研究院(BAAI)、北京大学、香港科技大学等多家顶尖机构的研究团队联合发布了一篇综述《Towards Automated Kernel Generation in the Era of LLMs》,系统地梳理了大语言模型(LLMs)和智能体(Agents)在自动化Kernel生成领域的最新进展。这不仅是代码生成的进阶版,更是AI系统自我进化的关键一步。
为什么是LLM?从“代码补全”到“性能压榨”
传统的编译器优化虽然稳定,但往往难以触及硬件性能的“天花板”。而人类专家虽然能写出极致优化的代码,但太贵且太慢。
LLM的出现打破了这一僵局。LLM不仅阅读了海量的代码,还“压缩”了大量的硬件文档和专家经验。这篇综述将现有的LLM驱动Kernel生成技术分为两大流派:
1. 专精特训:让模型“懂”硬件
通用的代码模型(如Codex)写Python很溜,但写CUDA或Triton往往漏洞百出。研究者们通过两种方式来强化模型:
-
监督微调(Supervised Fine-Tuning, SFT):
仅仅喂给模型代码是不够的,关键在于“思维链”。例如,ConCuR 等研究表明,通过构建包含“推理过程-代码-性能反馈”的高质量数据集,可以让模型学会像专家一样思考:先分析内存访问模式,再决定分块(Tiling)策略,最后生成代码。
-
强化学习(Reinforcement Learning, RL):
Kernel生成是一个典型的“结果导向”任务。代码不仅要跑通(Correctness),还要跑得快(Speedup)。AutoTriton 和 Kevin 等工作引入了执行反馈机制,将编译器的报错信息和运行时的延迟作为Reward,通过RL算法倒逼模型不断优化生成的代码。
2. Agent进化:从“一次生成”到“闭环优化”
如果说LLM是大脑,那Agent就是拥有手脚的工程师。综述指出,单次推理往往难以生成完美的Kernel,基于Agent的闭环工作流才是未来的主流。
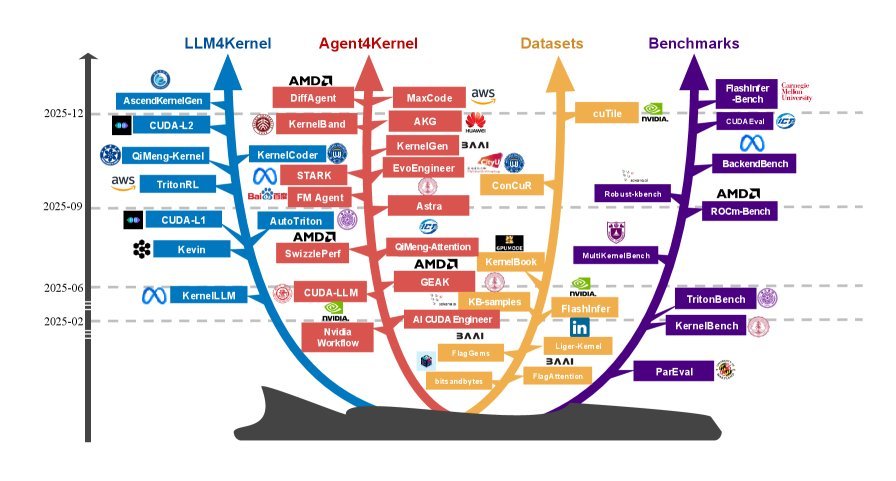
Agent通过以下几个维度实现了能力的跃升:
-
工具使用与环境交互:Agent不再是闭门造车,它们可以调用编译器(如NVCC)、性能分析器(如NCU)来获取真实的反馈。例如,CUDA-LLM 会根据Profiler返回的Cache命中率或Warp利用率,针对性地调整代码。
-
外部记忆与知识库:CUDA的API文档浩如烟海,模型记不住怎么办?RAG(检索增强生成)技术被引入其中。当模型遇到生僻的硬件指令时,Agent会自动检索相关的技术文档或高质量的代码片段作为参考。
-
多智能体协作:就像软件开发团队一样,KernelFalcon 和 CudaForge 等系统采用了“多角色”分工。一个Agent负责写代码(Coder),一个负责写测试用例(Tester),另一个负责审查性能瓶颈(Reviewer/Judge)。这种分工显著提高了生成代码的鲁棒性。
数据与基准:AI系统进化的“燃料”与“标尺”
要训练出懂底层的AI,数据是最大的痛点。通用的GitHub代码库中,高质量的、经过极致优化的Kernel代码占比极低。
综述整理了目前该领域的核心资源:
-
数据集:除了收集开源库(如CUTLASS),研究者们开始利用编译器自动生成对齐的“Python-Triton”数据对,或者通过合成数据来扩充训练集。
-
基准测试(Benchmark):评估标准正在从简单的“能否运行”转向多维度的考量。TritonBench 和 KernelBench 不仅关注加速比(Speedup),还引入了正确性(Correctness)和代码效率等指标。更重要的是,测试范围正从单一的NVIDIA GPU扩展到AMD GPU、华为NPU等异构硬件。
未来展望:挑战与机遇并存
虽然AI写Kernel已经展现出惊人的潜力,甚至在某些算子(如FlashAttention的变体)上超越了人类专家的实现,但综述也冷静地指出了当前的挑战:
-
数据稀缺与长尾效应:真正高性能的Kernel往往隐藏在闭源库中,且针对特定硬件优化的技巧难以通过通用文本学习到。
-
幻觉问题:LLM有时会捏造不存在的硬件指令或API,这在底层编程中是致命的。
-
泛化能力:目前的优化大多集中在NVIDIA生态,如何让AI自动适配AMD、Intel或国产芯片,实现“一次编写,到处高效运行”,是巨大的机遇。
结语
我们正在见证AI系统构建方式的范式转移。从人工手写算子,到编译器自动优化,再到如今的LLM+Agent自主生成,算力优化的门槛正在被迅速拉低。
这篇综述不仅是对现有技术的总结,更是一个信号:未来的AI工程师,可能不再需要死磕底层的汇编与指令集,而是通过设计更聪明的Agent,指挥AI去压榨硬件的每一滴性能。
对于想要深入这一领域的开发者,研究团队还维护了一个开源仓库,持续更新相关论文与资源:
https://github.com/flagos-ai/awesome-LLM-driven-kernel-generation