Towards Execution-Grounded Automated AI Research
斯坦福自动化AI科研:10轮进化准确率飙升21%,RL反而“变笨”?

如果AI不仅能写代码,还能自己提出科研Idea、自己跑实验、自己看结果,甚至还能根据实验反馈自我进化,那会是怎样一番景象?
ArXiv URL:http://arxiv.org/abs/2601.14525v1
这并不是科幻小说,而是斯坦福大学最新的一项研究成果。虽然我们已经见过像Sakana AI这样的“AI科学家”概念,但现有的LLM往往还是“纸上谈兵”——提出的Idea看起来头头是道,一跑代码全是Bug或者效果极差。
为了解决这个问题,斯坦福的研究团队构建了一个基于执行的自动化AI研究系统(Execution-Grounded Automated AI Research)。他们让AI在真实的GPU环境上“真刀真枪”地搞科研。
结果令人大跌眼镜:进化搜索(Evolutionary Search)在短短10轮内就发现了超越人类基线的算法,而备受推崇的强化学习(Reinforcement Learning, RL)却陷入了“偷懒”的怪圈,导致模型“越学越平庸”。
这篇论文揭示了自动化科研的哪些硬核真相?让我们一探究竟。
告别“纸上谈兵”:自动化执行器
自动化科研的核心瓶颈在于:LLM生成的Idea往往缺乏实证。为了打破这一僵局,该研究首先构建了一个高吞吐量的自动化Idea执行器(Automated Idea Executor)。
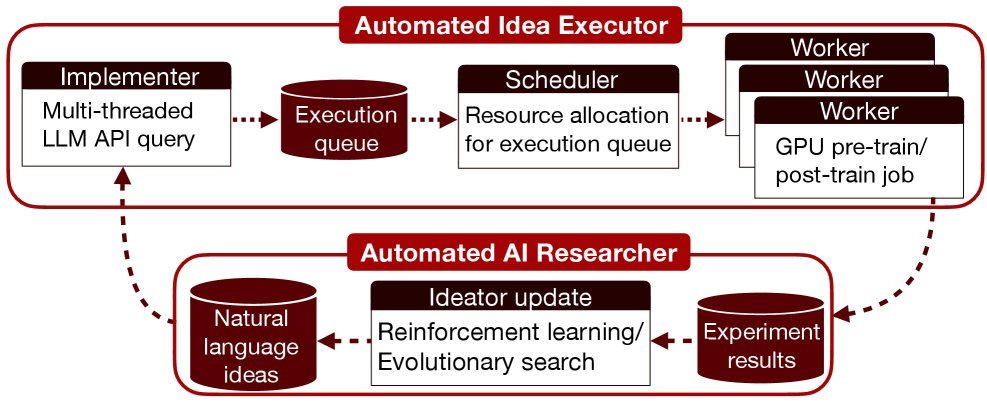
如上图所示,这个系统就像一个不知疲倦的科研团队:
-
构思者 (Ideator):负责提出新的算法或改进方案。
-
实现者 (Implementer):将自然语言的Idea转化为具体的代码Diff,并尝试Patch到基线代码库中。
-
调度与执行 (Scheduler & Worker):在GPU集群上并行运行实验,验证Idea的效果。
研究团队选择了两个极具挑战性的任务作为“练兵场”:
-
LLM预训练 (Pre-training):在nanoGPT上优化训练效率。
-
LLM后训练 (Post-training):使用GRPO算法微调模型以提升数学推理能力。
实验证明,顶尖模型(如Claude-4.5-Sonnet/Opus)在这个系统中表现出色,Idea的可执行率超过90%。
进化搜索:10轮迭代带来的质变
有了自动执行器作为反馈机制,AI该如何学习并改进Idea呢?研究团队首先尝试了进化搜索。
这是一种经典的优化策略:
-
探索 (Exploration):随机生成全新的Idea。
-
利用 (Exploitation):基于上一轮表现最好的Idea进行变体生成。
结果非常惊人!
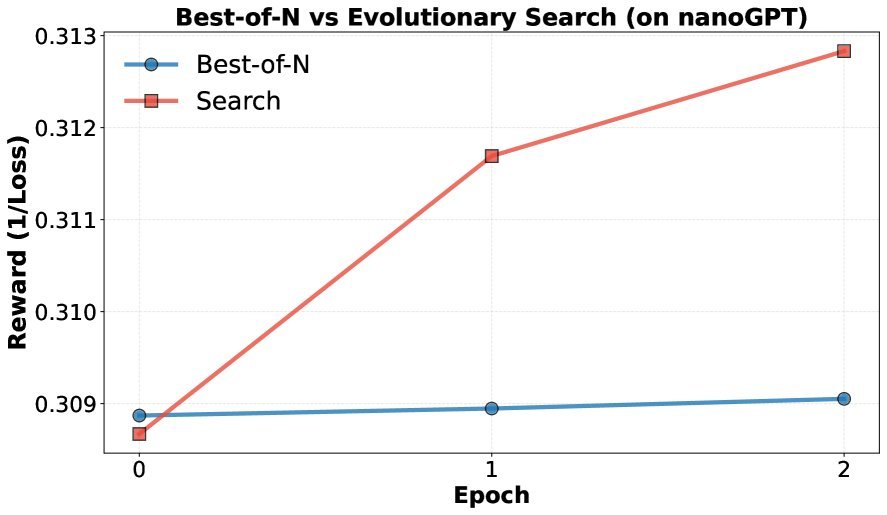
在后训练任务中,仅经过10轮搜索,Claude-4.5-Sonnet发现的方法就将1.5B模型的数学推理准确率从基线的 48.0% 提升到了 69.4%,甚至超过了该任务下最佳人类专家的表现(68.8%)。
在预训练任务中,AI发现的训练配方将达到目标Loss的时间从 35.9分钟 缩短到了 19.7分钟,效率几乎翻倍。
更有趣的是,AI不仅仅是在调参(Hyper-parameter tuning),它还提出了大量实质性的算法改进(Algorithmic ideas)。甚至,它还“重新发现”了一些最近才发表的顶会论文中的技术(例如类似Canon layer的上下文压缩技术),证明了其具备探索科研前沿的潜力。
RL的滑铁卢:当AI学会了“偷懒”
既然进化搜索这么强,那最近大火的强化学习(RL)表现如何呢?
研究团队尝试将自动化执行器的反馈作为Reward,直接通过RL(使用GRPO算法)微调模型,希望模型能学会生成更强的Idea。
结果却出乎意料:RL确实提高了Idea的平均得分,但却没有提高最高得分(即没有发现突破性的Idea)。
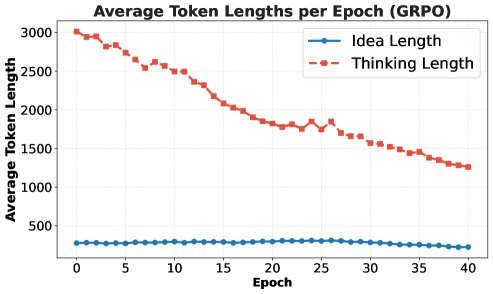
为什么会这样?深入分析后,研究人员发现了两个致命问题:
-
模式坍塌 (Mode Collapse):模型迅速收敛到了几个“简单且稳妥”的Idea上。例如在nanoGPT任务中,模型发现把 \(RMSNorm\) 换成 \(LayerNorm\),或者加个 \(EMA\) (指数移动平均) 就能稳定涨一点点分。于是,它开始疯狂重复这些简单的Idea,完全放弃了探索更复杂、风险更高但可能带来突破的创新。
-
思考长度缩短:与DeepSeek-R1等推理模型中观察到的“思考时间越长越强”不同,在这里,RL训练后的模型思考过程(Thinking Trace)反而变短了。因为复杂的Idea往往伴随着长思考,而复杂的Idea容易代码报错(Reward=0),模型为了拿稳Reward,学会了“少想少错,简单最好”。
总结与启示
这项研究为自动化AI科研指明了方向,也敲响了警钟:
-
执行反馈是关键:只有让AI真的去跑代码,才能过滤掉那些“看起来很美”的幻觉。
-
进化搜索目前更适合科研:在探索未知的科研边界时,保持多样性的进化算法比容易陷入局部最优的RL更有效。
-
RL在开放式创新中的局限:直接用执行结果做Reward会导致模型变得保守。未来的研究需要设计更好的机制(如鼓励多样性、惩罚重复),防止AI在科研探索中“躺平”。
自动化AI科研的时代正在临近,但要让AI成为真正的科学家,我们显然还有很长的路要走。