Trainable Log-linear Sparse Attention for Efficient Diffusion Transformers
LLSA:让Diffusion Transformer提速28倍的“对数级”稀疏注意力机制
你是否曾被Diffusion Transformer(DiT)那令人惊叹的高清图像生成能力所折服?从Sora到FLUX,这些模型正在重塑视觉生成的边界。
ArXiv URL:http://arxiv.org/abs/2512.16615v1
但在这光鲜亮丽的背后,隐藏着一个巨大的痛点:随着图像分辨率的提升,计算成本呈爆炸式增长。
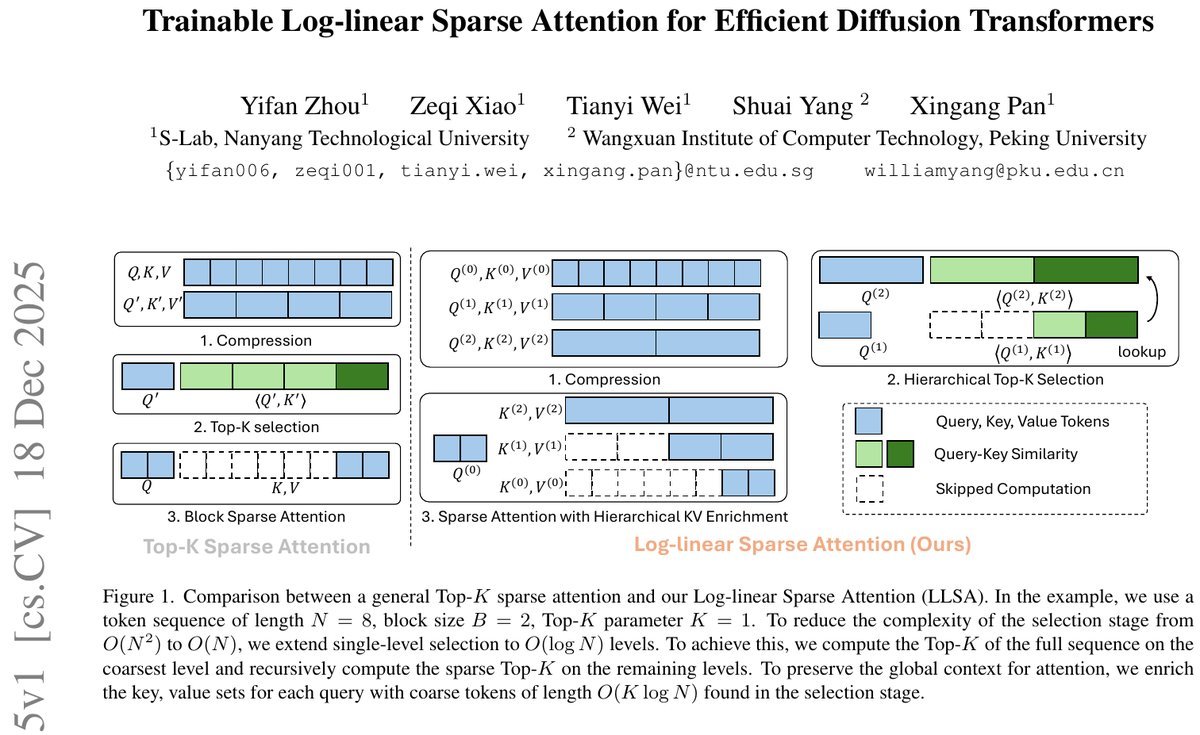
传统的全注意力机制(Full Attention)就像一个贪婪的巨兽,其计算复杂度是$O(N^2)$。这意味着,如果你想把图像分辨率翻倍,计算量可能要翻四倍甚至更多。现有的稀疏注意力(Sparse Attention)虽然试图通过“Top-K选择”来给这个巨兽减肥,但在处理超长序列时,它们依然受困于$O(N^2)$的选择成本,且往往需要牺牲生成质量。
今天我们要解读的这篇论文,来自南洋理工大学和北京大学的研究团队,他们提出了一种名为LLSA(Log-linear Sparse Attention)的全新机制。这项技术不仅将复杂度从平方级降到了对数线性级,更在保持生成质量的同时,实现了惊人的加速效果。
核心痛点:为什么现有方法还不够快?
在处理长序列(比如高分辨率图像或长视频)时,现有的Top-K稀疏注意力方法主要面临两个瓶颈:
-
选择成本依然昂贵:虽然注意力计算本身变稀疏了,但为了找出哪$K$个块(Block)最重要,模型仍然需要先对所有块进行一次粗略的计算。这一步的复杂度依然是$O(N^2)$,在序列极长时,这本身就成了新的瓶颈。
-
顾此失彼的尴尬:为了保证生成质量,随着序列变长,通常需要增大$K$值(即保留更多的注意力连接)。这导致计算量再次攀升,所谓的“稀疏”变得不再稀疏。
这就像是为了在一个巨大的图书馆里找一本书,虽然你只读这一本书(稀疏注意力),但为了找到它,你不得不先把图书馆里所有书的目录都翻一遍(平方级的选择成本)。
LLSA的破局之道:分层与富集
LLSA的设计哲学非常精妙,它通过两个核心创新解决了上述问题:
1. 分层Top-K选择(Hierarchical Top-K Selection)
LLSA不再试图一次性从所有块中找出最重要的部分,而是采用了一种“由粗到细”的分层策略。
-
金字塔结构:它将序列压缩成多个层级,就像金字塔一样。
-
递归筛选:首先在最顶层(最粗糙的层级)进行筛选,找出大概的关注区域;然后在下一层级,只在上一层选中的区域内进一步细化筛选。
这种分层设计直接将选择阶段的复杂度从$O(N^2)$降低到了$O(N)$。就像找书时,先找楼层,再找书架,最后找书,效率呈指数级提升。
2. 分层KV富集机制(Hierarchical KV Enrichment)
这是LLSA最精彩的一笔。传统的稀疏注意力往往因为丢弃了太多信息而导致“视野狭窄”,丢失了全局上下文。
LLSA引入了一种混合粒度的策略:
-
对于最相关的区域,使用最精细的Token进行计算。
-
对于稍远的区域,使用较粗粒度的Token(即压缩后的Token)作为补充。
这就好比我们在看一幅画:对于焦点区域,我们用放大镜看细节;对于背景区域,我们用余光看轮廓。这样既保留了全局上下文(Global Context),又极大地减少了计算量。
极致的工程优化:告别Dense Mask
除了算法层面的创新,LLSA在工程实现上也做到了极致。
在标准的FlashAttention中,处理稀疏注意力通常需要构建一个巨大的掩码矩阵(Mask),这会消耗大量的显存和计算资源。LLSA开发了一套高效的GPU内核,直接在稀疏索引上进行操作。
特别是在反向传播(Training Backward)阶段,LLSA设计了一种轻量级的稀疏索引转置算法,彻底消除了对密集掩码的依赖。这意味着,LLSA不仅推理快,训练也快,且显存占用极低。
实验结果:速度与质量的双赢
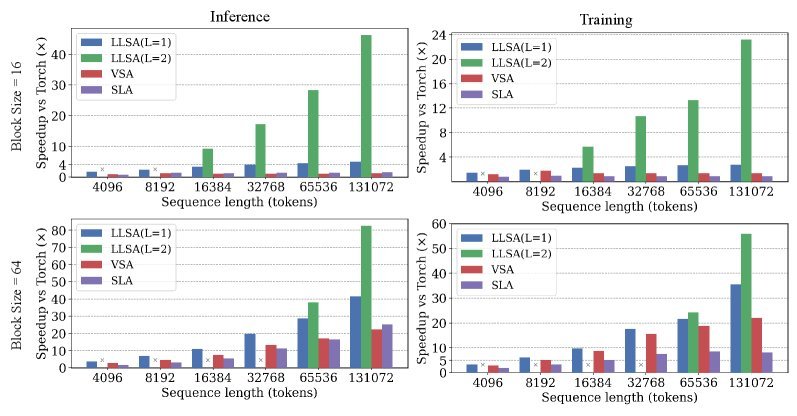
研究团队在不使用Patch化和VAE编码的情况下,直接在像素空间训练高分辨率DiT(最高达$256 \times 256$像素序列,即65536个Token)。结果令人印象深刻:
-
推理加速:在$256 \times 256$分辨率下,注意力推理速度提升了28.27倍。
-
训练加速:DiT的整体训练速度提升了6.09倍。
-
质量更优:得益于KV富集机制,LLSA即使在$K=8$这种极小的稀疏度下,其生成质量(FID分数)依然优于其他需要$K=32$的稀疏注意力方法。
总结
LLSA通过将复杂度降低到$O(N \log N)$,打破了长序列生成的计算诅咒。它证明了我们不需要在“速度”和“质量”之间做艰难的妥协。对于未来想要训练更高分辨率、更长视频的DiT模型的研究者来说,LLSA无疑提供了一条极具潜力的技术路线。
简单来说,LLSA告诉我们:看得少(Sparse),但这并不意味着看得不准;只要层次分明,一眼就能看到本质。