Transformers learn factored representations
Transformer的世界观:自动将指数级复杂世界拆解为线性正交因子
人类观察世界的方式是结构化的:我们看到的不是一堆杂乱无章的像素或原子,而是桌子、杯子、行人等一个个独立的“部件”。这种将世界分解为独立因子的能力,是我们理解复杂环境的基石。
ArXiv URL:http://arxiv.org/abs/2602.02385v1
那么,仅通过“预测下一个Token”训练出来的 Transformer,是否也具备这种能力?
DeepMind、牛津大学等机构的最新研究给出了肯定的答案。这篇论文揭示了一个令人兴奋的发现:Transformer 具有一种强烈的归纳偏置(Inductive Bias),它会自动将复杂的联合状态分解为独立的因子,并将这些因子存储在残差流(Residual Stream)的正交子空间中。
这不仅解释了 Transformer 为何高效,更揭示了其内部“世界模型”的几何构造。
核心冲突:联合表示 vs. 因子化表示
为了理解 Transformer 是如何表征世界的,研究人员提出了两种假设的几何结构。假设我们有一个由 $N$ 个独立部分组成的世界(例如 $N$ 个独立运转的时钟),每个部分有 $d$ 种状态。
-
联合表示(Joint Representation):
模型试图在一个巨大的空间中表示所有可能的组合状态。这种表示的维度随着因子数量呈指数级增长。对于 $N$ 个部分,维度需求约为 $d^N$。这就像是试图记住世界上每一个原子组合的快照,极其低效。
-
因子化表示(Factored Representation):
模型将每个部分单独表示,并将它们“堆叠”在一起。这种表示的维度随着因子数量呈线性增长。对于 $N$ 个部分,维度需求仅为 $N \times (d-1)$。这就像是分别记住每个时钟的时间,高效且清晰。
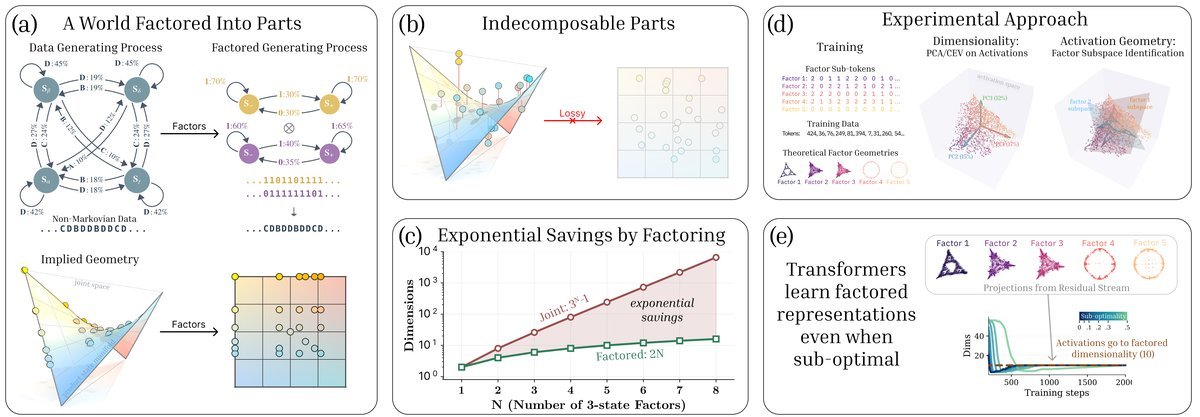
图1:Transformer 学习将世界分解为部分。(a) 复杂的联合过程(左上)可以分解为简单的独立过程(右上)。(c) 这种分解带来了巨大的表示节省:联合表示(红色)需要指数级维度,而因子化表示(绿色)仅需线性维度。
论文的核心问题在于:Transformer 到底选择了哪一种?
实验揭秘:残差流中的正交几何
为了验证这一点,研究团队构建了一个已知潜在结构的合成数据集。这个数据由5个独立的隐藏过程(Factors)生成,模型只能看到最终混合后的 Token,而不知道背后的生成逻辑。
实验结果令人震惊:
1. 维度坍缩至线性边界
在训练初期,模型的激活空间维度很高。但随着训练进行,用于解释 95% 方差所需的维度迅速下降,并最终稳定在一个非常低的数值上。
这个数值惊人地吻合了因子化表示的理论预测值(线性增长),而远远低于联合表示所需的指数级维度。这意味着 Transformer “看穿”了数据的表面复杂性,找到了背后的独立因子。
2. 完美的正交子空间
更进一步的分析发现,Transformer 不仅学会了区分这些因子,还为每个因子在残差流中分配了专属的“领地”。
研究人员发现,代表不同因子的激活向量位于相互正交的子空间(Orthogonal Subspaces)中。这意味着模型在处理“因子A”的信息时,完全不会干扰到“因子B”的信息。残差流就像一条宽阔的高速公路,被模型自动划分成了互不干扰的车道,每个车道跑着不同的因子信息。
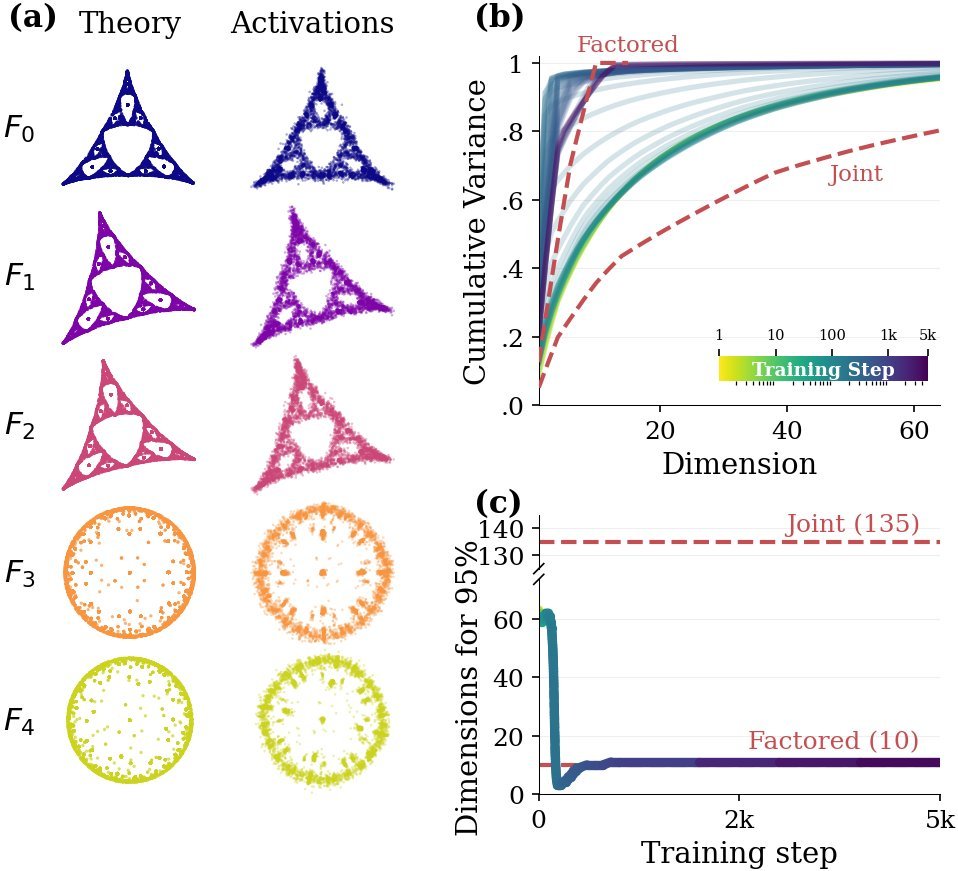
图2:(b) 随着训练进行,不同因子对应的子空间逐渐变得正交(重叠度降低)。(c) 激活空间的有效维度迅速收敛到因子化表示的理论值(绿色虚线),彻底抛弃了联合表示(红色虚线)。
强烈的“因子化”偏好
如果世界本身不是完美独立的呢?如果因子之间存在微弱的联系或噪声,Transformer 还会坚持分解吗?
这是论文最精彩的发现之一:Transformer 对因子化有着近乎执着的偏好。
研究人员引入了噪声和隐藏依赖,破坏了数据的完美独立性。在这种情况下,数学上最优的预测其实需要使用联合表示(因为因子之间有相关性)。
然而,实验显示,Transformer 在训练早期依然会优先学习因子化表示。它甚至愿意牺牲一定的预测准确度(Fidelity),也要保持表示的简洁和解耦。这种现象表明,因子化不仅仅是模型学到的结果,更是 Transformer 架构本身的一种归纳偏置。它天生就倾向于把世界拆解开来理解。
总结与启示
这项研究为我们理解大模型的“黑盒”打开了一扇明亮的窗户:
-
世界模型是存在的:Transformer 确实在内部构建了结构化的世界模型,而不是简单的统计相关性记忆。
-
简单即是美:模型通过将指数级复杂的问题拆解为线性子问题,实现了高效的计算和泛化。
-
可解释性的希望:既然模型倾向于将不同概念存储在正交子空间中,这意味着我们完全有可能通过线性探针(Linear Probes)精确地找到并控制这些概念,为未来的可解释性研究指明了方向。
Transformer 并没有试图死记硬背整个世界,它学会了像人类一样,把世界拆成一块块积木,然后通过正交的通道并行处理。这或许正是智能涌现的几何基础。