TreeGRPO: Tree-Advantage GRPO for Online RL Post-Training of Diffusion Models
训练加速2.4倍!TreeGRPO用“决策树”革新AI绘画模型对齐

让AI画出更符合我们心意的作品,是生成模型发展的关键一步。
ArXiv URL:http://arxiv.org/abs/2512.08153v1
但这背后的人类偏好对齐,往往需要消耗巨大的计算资源。
现有的强化学习(RL)方法虽然有效,但训练过程实在太慢了!
现在,来自MIT和UCSD的研究者们提出了一种新框架 TreeGRPO。
它巧妙地将AIGC的生成过程重塑为一棵“决策树”,实现了惊人的2.4倍训练加速,同时在效果和效率之间取得了当前最佳的平衡!
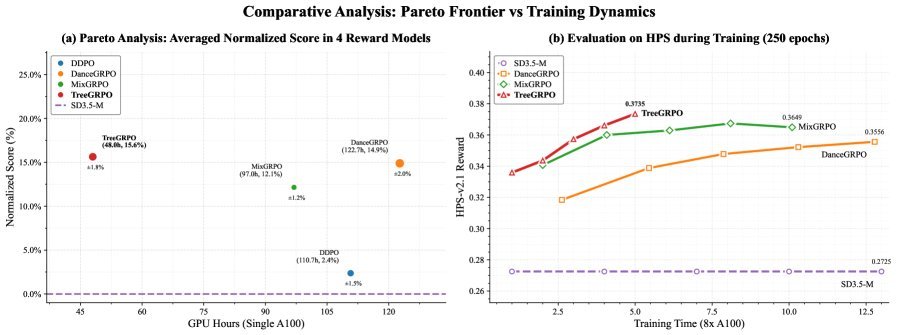
图1: TreeGRPO在奖励分数和训练效率的帕累托前沿上表现最佳
现有对齐方法的瓶颈
在TreeGRPO之前,像 DDPO 或 GRPO 这样的方法已经尝试使用强化学习来对齐文生图模型。
但它们普遍存在两大痛点:
-
样本效率低下:每次更新模型,都需要从头生成一张完整的图片。即使很多中间步骤是相似的,计算资源也被白白浪费了。
-
信用分配粗糙:一张好图的功劳,被平均分给了生成过程中的每一步。这就像一个团队项目最终拿了大奖,但无法分清谁是关键贡献者,谁在“摸鱼”。
这导致训练不仅慢,而且优化方向也不够精准。
核心思想:生成过程即树搜索
TreeGRPO的灵感来源于AlphaGo等棋类AI中高效的树搜索算法。
研究者意识到,扩散模型的去噪过程是一个分步决策的序列,非常适合用树结构来优化。
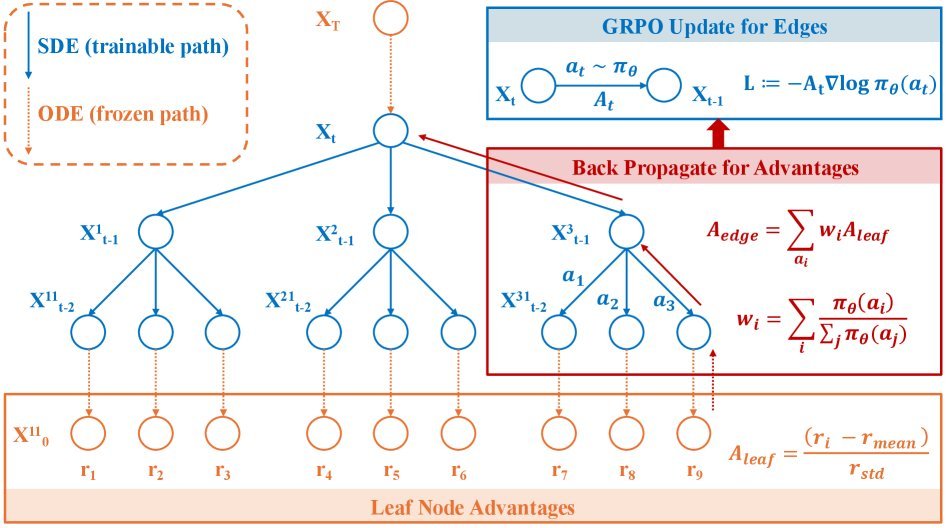
图2: TreeGRPO框架示意图,将去噪过程构建为一棵搜索树
它的核心做法是:
不再为每次迭代都生成一条全新的路径,而是从一个共享的初始噪声出发。
在生成过程的某个中间步骤,像树枝一样分叉,探索多条不同的后续路径。
这样一来,所有分支都复用了共同的“树干”部分(即前缀复用),计算效率大大提升。
TreeGRPO的三大优势
这种树状结构带来了三个关键优势:
-
高样本效率:通过前缀复用和分支探索,用更少的计算量生成了更多样的候选图片,训练信号更丰富。
-
精细化信用分配:通过奖励回传机制,能够计算出每一步操作的具体贡献,实现了精准“论功行赏”。
-
摊销计算成本:一次前向传播可以产生多个分支,从而进行多次策略更新,进一步提升了效率。
技术拆解:TreeGRPO如何工作?
让我们深入看看TreeGRPO的技术细节。
1. 树状结构采样器
TreeGRPO并非在每一步都进行分支,而是采用了一种“随机窗口”策略。
它会随机选择一个连续的时间窗口(比如在总共10步的去噪过程中,选择第3到第5步)。
在这个窗口内,模型会采用随机微分方程(SDE)进行探索,生成多个分支。
而在窗口之外,则使用确定性的常微分方程(ODE)进行快速、单一路径的生成。
这种混合策略兼顾了探索的多样性和计算的经济性。
2. 从叶到根的优势传播
当树的各个分支(叶节点)都生成最终图像后,奖励模型会为每张图打分。
接下来是TreeGRPO最精妙的一步:优势传播(Advantage Propagation)。
首先,对同一提示词(Prompt)下的所有叶节点得分进行归一化,得到叶节点优势 $A_{\text{leaf}}$。
然后,从叶节点开始,自底向上地将优势值反向传播到父节点。
一个父节点的优势,是其所有子节点优势的加权平均,权重由该分支的生成概率决定。
\[A_{\text{edge}}(e^{\prime}) = \sum_{e\in S(u)}w_{u}(e)\,A_{\text{edge}}(e)\]通过这个过程,奖励信号被精确地分配到了树的每一条“边”上,得到了每步优势 $A_{\text{edge}}$。
3. 基于边优势的GRPO更新
最后,TreeGRPO使用这些计算出的、精细化的“每步优势”来指导模型的策略更新。
它采用了一种类似PPO的GRPO(Group-Relative Policy Optimization)更新法则,但优化的目标不再是整个轨迹的笼统奖励,而是每个关键步骤的具体优势值。
\[\mathcal{L}_{\text{GRPO}}(\theta) = -\sum_{t\in\mathcal{W}}\sum_{e\in\mathcal{E}_{t}}\min\!\Big(r_{t}(e;\theta)\,A_{\text{edge}}(e),\;\mathrm{clip}\!\big(r_{t}(e;\theta),\,1-\epsilon,\,1+\epsilon\big)\,A_{\text{edge}}(e)\Big)\]这使得模型的每一步优化都“有的放矢”,从而更快地学会如何生成高质量、高偏好度的图像。
实验效果:又快又好
实验结果有力地证明了TreeGRPO的优越性。
研究团队在SD3.5-medium模型上进行了测试,并与DDPO、DanceGRPO等主流方法进行了对比。

图3: 在多个奖励模型上,TreeGRPO(红色)均取得了领先的性能和效率
-
效率:在单奖励模型训练中,TreeGRPO每轮迭代仅需72.0秒,而基线方法中最快的MixGRPO也需要145.4秒,最慢的DanceGRPO则需要184.0秒。TreeGRPO实现了2.4倍的训练加速!
-
性能:无论是在单一奖励(HPSv2.1)还是多重奖励(HPSv2.1 + ClipScore)的训练设置下,TreeGRPO在多个评价指标上都取得了与基线持平甚至更优的成绩。
-
帕累托最优:综合来看,TreeGRPO在“性能-效率”的权衡中,达到了新的帕累托前沿,意味着在同等效果下它最快,在同等耗时下它最好。
此外,研究还分析了树的宽度$k$和深度$d$等超参数的影响,发现$k=3, d=3$的配置在性能和效率之间取得了最佳平衡。
总结与展望
TreeGRPO通过将扩散模型的生成过程巧妙地重构为树搜索问题,成功解决了强化学习对齐中的两大核心痛点:样本效率和信用分配。
它不仅实现了高达2.4倍的训练加速,还在生成质量上保持了强大的竞争力,为视觉生成模型的高效对齐提供了一条可扩展的有效路径。
当然,该方法也引入了新的超参数(如树的结构),并增加了训练时的内存占用。未来的工作可能会探索自适应地调整这些参数,或将该思想应用到视频、3D等更复杂的生成任务中。
总而言之,TreeGRPO用一个优雅的“树”结构,为昂贵的AI模型对齐过程踩下了一脚关键的“油门”。