UI-TARS-2 Technical Report: Advancing GUI Agent with Multi-Turn Reinforcement Learning
UI-TARS-2:多轮强化学习炼成!达60%人类水平,AI智能体自主操作电脑

让AI像我们一样熟练地操作电脑,无论是浏览网页、处理文件还是玩游戏,这无疑是通用人工智能(AGI)最激动人心的目标之一。然而,现实却骨感得多:去哪里找海量的操作数据?如何让模型在漫长而复杂的任务中稳定学习?
ArXiv URL:http://arxiv.org/abs/2509.02544v2
今天,一篇名为 UI-TARS-2 的技术报告为我们带来了突破性的答案。它不仅在多个主流GUI(图形用户界面)基准测试中超越了Claude和OpenAI的智能体,更是在游戏测试中达到了接近60%的人类水平!这背后,是一套系统化的训练方法论,解决了GUI智能体面临的核心难题。
破解GUI智能体的四大枷锁
过去的GUI智能体开发,常常面临四大挑战:
-
数据稀缺:高质量、长交互链条的“人机交互”数据,极其昂贵且稀少。
-
RL训练不稳:在多步骤交互中,强化学习(RL)的奖励稀疏、优化困难,难以规模化。
-
操作局限:单纯的“点鼠标、敲键盘”无法胜任需要文件系统或命令行的复杂工作。
-
环境脆弱:大规模、可复现的模拟环境搭建困难,稳定性差。
UI-TARS-2 直面这些挑战,提出了一个由四大支柱构成的系统性解决方案。
数据飞轮:自我进化的数据引擎
如何解决数据稀缺问题?答案是:让模型自己“造血”。
UI-TARS-2 设计了一个精巧的数据飞轮(Data Flywheel)机制。它建立了一个自我强化的闭环,让模型能力和数据质量共同进化。
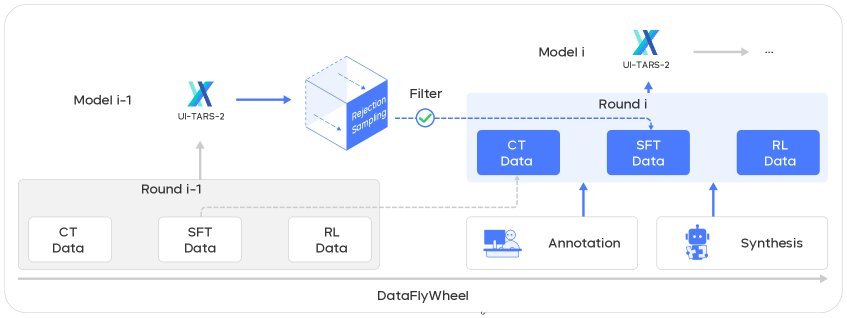
这个飞轮包含三个核心训练阶段:
-
持续预训练(CT):从广泛的数据中学习基础知识。
-
监督微调(SFT):使用高质量、有标注的数据进行任务对齐。
-
强化学习(RL):在真实交互中进行端到端优化。
在每一轮迭代中,最新的RL模型会生成新的交互轨迹。高质量的轨迹会被送入SFT数据集,而质量稍逊的则被送入CT数据集。这样,模型总能用上最适合它的数据,形成“更好的模型产出更好的数据,更好的数据训练出更好的模型”的良性循环。
稳定的多轮强化学习框架
多轮强化学习是训练高级智能体的关键,但也是最难啃的骨头。
传统方法在处理长尾、复杂的任务时效率低下,且容易因策略偏离而导致训练崩溃。UI-TARS-2 通过一个专为大规模、长时程任务设计的RL训练框架,巧妙地解决了这个问题。
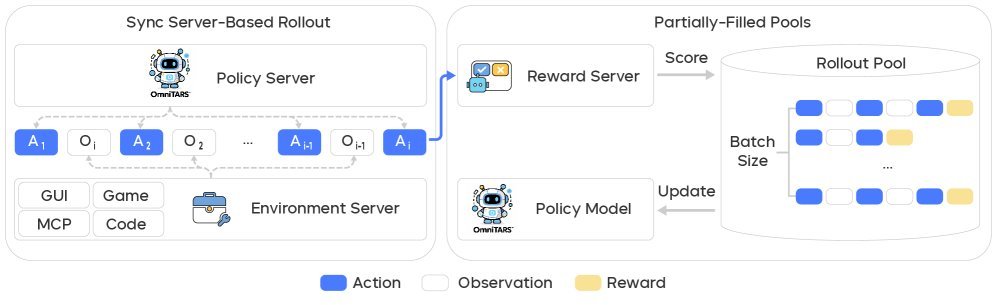
其核心设计包括:
-
异步推理与流式训练:智能体与环境的交互是异步的,训练数据像流水一样持续输入,无需等待整个批次完成。这大大提升了训练效率,避免了被少数耗时任务卡住。
-
有状态的环境:环境能够保存智能体的操作状态,支持需要跨越多步骤、保持上下文的复杂任务。
-
增强的PPO算法:通过奖励塑造、自适应优势估计等技术,对经典的近端策略优化(Proximal Policy Optimization, PPO)算法进行了改进,让训练过程更稳定。
统一沙箱:打通虚拟与现实的操作环境
一个强大的GUI智能体,能力绝不能局限于屏幕之内。
UI-TARS-2 打造了一个“All-in-One”的统一沙箱(Unified Sandbox)平台。这个平台不仅支持在虚拟机中运行Windows、Ubuntu和Android等主流操作系统,还无缝集成了文件系统和命令行工具。
这意味着智能体可以完成更真实的工作流。比如,它可以在浏览器里下载一个文件,然后立刻在同一个沙箱环境里用命令行工具对它进行处理。
此外,该研究还为网页游戏构建了硬件加速的浏览器沙箱,能够支持高并发、高效率的RL训练,为模型在游戏领域的出色表现奠定了基础。
惊艳的实证效果
理论的先进最终要靠效果说话。UI-TARS-2 的表现堪称惊艳:
-
GUI基准测试:在 Online-Mind2Web、OSWorld、WindowsAgentArena 和 AndroidWorld 等多个权威基准上,得分分别达到88.2、47.5、50.6和73.3,全面超越了其前代模型,并在多项测试中优于Claude和OpenAI等强大的基线模型。
-
游戏环境:在一个包含15款游戏的测试集中,UI-TARS-2 取得了59.8的平均归一化分数,达到了大约60%的人类玩家水平。
-
泛化能力:更令人印象深刻的是,这套为GUI训练的方法论表现出了极强的泛化能力。在长时程信息检索(BrowseComp)和软件工程(SWE-Bench)等任务上,UI-TARS-2 同样展现了强大的竞争力。
结论
UI-TARS-2 的意义远不止是发布了一个性能更强的模型。它提供了一套系统化、可扩展、可复制的GUI智能体训练方法论。
通过数据飞轮解决了数据瓶颈,通过稳定的多轮强化学习框架攻克了训练难题,再结合统一沙箱打通了操作壁垒,UI-TARS-2 为通往更通用、更强大的AI智能体铺平了道路。未来,AI真正成为我们“数字化身”的那一天,或许已经不远了。