Understanding and Steering the Cognitive Behaviors of Reasoning Models at Test-Time
拒绝“过度思考”!CREST让大模型推理提速37.6%,精度暴涨17.5%

大模型(LLM)的思维链(Chain-of-Thought, CoT)技术虽然强大,但你是否发现,模型有时候像个啰嗦的老学究?它经常陷入“过度思考”(Overthinking)的泥潭,生成大量冗余的验证步骤,或者在简单问题上反复纠结,导致推理速度极慢,计算成本飙升。
ArXiv URL:http://arxiv.org/abs/2512.24574v1
如果我们可以像外科手术一样,精准地切除模型大脑中那些“犹豫不决”和“无效反思”的区域,会发生什么?
来自Together AI、悉尼大学和德克萨斯大学奥斯汀分校的研究团队给出了答案。他们不仅发现了大模型中专门负责“纠结”的认知注意力头(Cognitive Heads),还提出了一种无需训练的推理解码策略——CREST。这项技术在测试时通过轻量级的干预,不仅让模型推理速度提升了37.6%,更令人惊讶的是,准确率最高提升了17.5%!
揭秘大模型的“犹豫”神经元
人类在解决复杂问题时,通常会经历两种思维模式:
-
线性推理(Linear Reasoning):一步接一步的逻辑推导。
-
非线性推理(Non-linear Reasoning):包括回溯、验证、自我纠错(例如:“等等,让我再检查一下”、“或者我们可以这样想”)。
研究人员发现,现有的推理模型(如DeepSeek-R1等)在生成CoT时,这两种模式是交织在一起的。虽然非线性推理对解决难题至关重要,但过度的非线性推理往往意味着效率低下和“钻牛角尖”。
为了探究这一现象,研究团队做了一个有趣的实验:他们将推理步骤标记为“线性”或“非线性”,然后训练一个简单的线性分类器来观察模型的内部激活。结果令人兴奋——模型中存在特定的注意力头(Attention Heads),它们的激活模式可以高度预测当前是否在进行“非线性推理”。
这些特殊的注意力头被命名为认知头(Cognitive Heads)。它们就像是模型大脑中的“监控器”,专门负责检查、回溯和纠错。
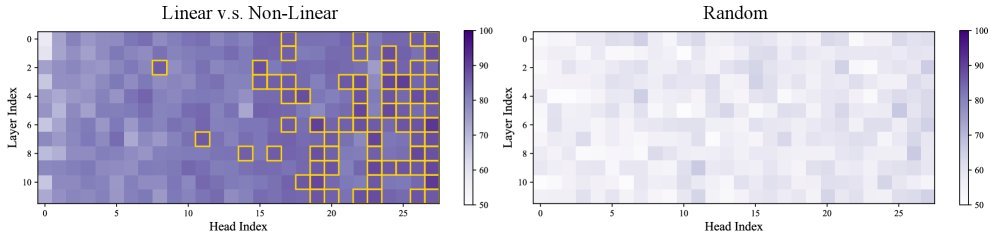
图1:不同层中注意力头对非线性推理步骤的分类准确率。可以看到,深层的某些头(红色点)对认知行为有极高的识别能力。
CREST:给大模型做个“思维瘦身”
既然找到了这些“认知头”,我们能否控制它们?
研究团队提出了CREST(Cognitive REasoning Steering at Test-time),这是一种无需重新训练模型,仅在推理阶段(Test-time)进行的干预方法。它的核心思想是:在推理过程中,适度抑制那些导致过度非线性推理的信号,引导模型更高效地得出结论。
CREST包含两个简洁的步骤:
1. 离线校准(Offline Calibration)
这是一个一次性的过程。研究者通过少量的样本,识别出哪些是“认知头”,并计算出一个引导向量(Steering Vector)。
为了去除噪声,CREST并没有直接使用原始的头向量,而是利用PCA(主成分分析)提取了一个共享的低秩子空间,从而得到了更纯净的引导方向 $v^{i,j}$。
2. 测试时引导(Test-time Steering)
在模型实际推理时,CREST会对每一层输出的隐藏状态进行微调。具体的做法是,将隐藏状态 $x^{i,j}$ 在引导向量 $v^{i,j}$ 的方向上进行正交化旋转。
为了避免引入复杂的超参数(如步长),CREST采用了一种巧妙的范数保持(Norm-Preserving)策略:
\[\hat{x}^{i,j}=\frac{\lVert x^{i,j}\rVert}{\lVert x^{i,j}-\big((x^{i,j})^{\top}v^{i,j}\big)v^{i,j}\rVert}\left(x^{i,j}-\big((x^{i,j})^{\top}v^{i,j}\big)v^{i,j}\right)\]这个公式看起来复杂,其实含义很简单:剔除掉隐藏状态中那些“想要过度反思”的分量,同时保持信号的总强度不变。 这使得CREST具有极高的稳定性,不需要针对每个任务费力地调整参数。
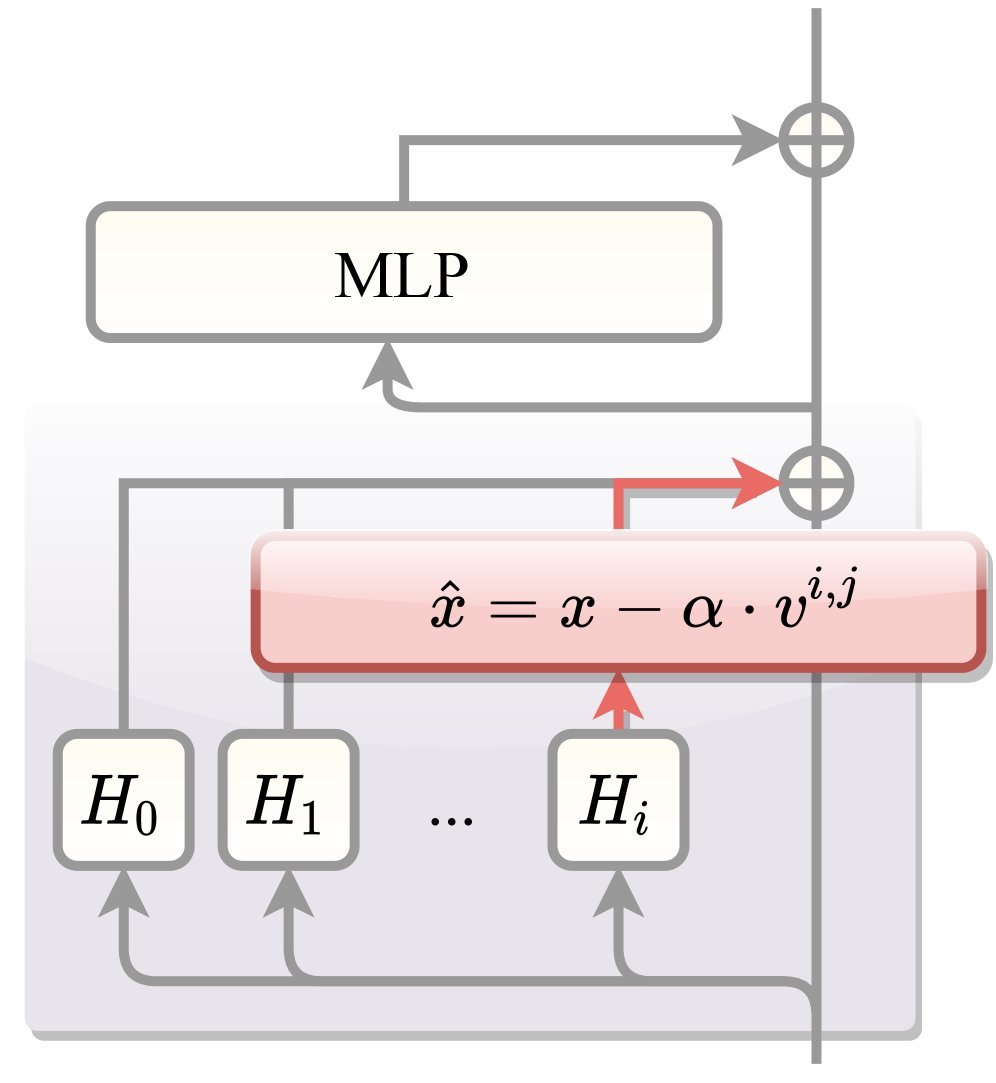
图2:CREST的工作流程。通过抑制特定的认知头,模型从冗长的“过度思考”路径(红色)转变为更高效的路径(绿色)。
效果拔群:更快,更准,更省钱
实验结果证明,适度的“思维瘦身”不仅没有让模型变笨,反而让它更聪明了。
研究团队在MATH500、AIME、LiveCodeBench等多个高难度推理基准上测试了CREST。结果显示,通过抑制无效的非线性推理,模型避免了在错误路径上的反复纠缠,从而显著提升了性能。
-
准确率提升:在AMC23数据集上,使用CREST的DeepSeek-R1-Distill-Qwen-1.5B模型准确率提升了惊人的17.50%。
-
Token消耗降低:同一任务中,Token的使用量减少了37.60%。这意味着推理速度更快,API调用成本更低。
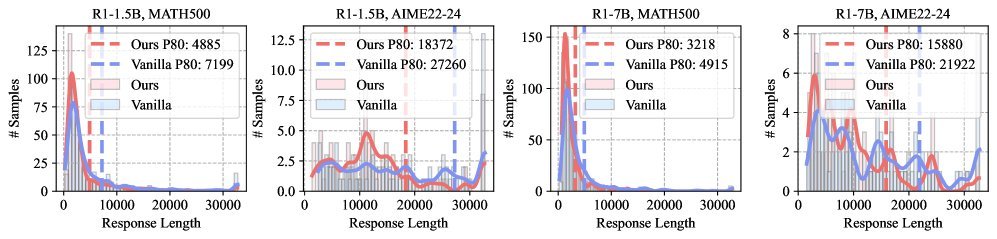
图7:响应长度分布对比。CREST(橙色)显著将推理长度的分布向左推移,大幅减少了长尾的冗余推理。
总结与启示
CREST的成功揭示了一个反直觉的现象:更多的思考并不总是意味着更好的结果。 现有的CoT推理中存在大量的冗余,通过精准的神经元干预,我们可以挖掘出模型潜在的效率。
这项工作最吸引人的地方在于它的即插即用特性。不需要昂贵的重训练,不需要修改模型架构,只需要在推理阶段加一点点“魔法”,就能让你的大模型既快又准。对于那些受限于端侧计算资源或对延迟敏感的应用来说,CREST无疑是一个极具价值的优化方案。