Unlocking the Power of Multi-Agent LLM for Reasoning: From Lazy Agents to Deliberation
-
ArXiv URL: http://arxiv.org/abs/2511.02303v1
-
作者: Yudi Lin; Qi He; Fali Wang; Xianfeng Tang; Suhang Wang; Ramraj Chandradevan; Hui Liu; Zhiwei Zhang; Xiaomin Li
-
发布机构: Harvard University; Michigan State University; Microsoft; The Pennsylvania State University; University of Utah
TL;DR
本文识别并解决了多智能体 LLM 推理框架中的“懒惰智能体”问题,通过理论分析揭示其源于现有强化学习目标的内在偏差,并提出了一种名为 Dr. MAMR 的新框架,该框架利用夏普利启发的因果影响测量和一种可验证的深思熟虑(deliberation)奖励机制,以促进智能体之间更均衡、更有效的协作。
关键定义
- 懒惰智能体 (Lazy Agent):在多智能体系统中,某个智能体对任务的贡献微不足道(例如,仅复述、总结而不产生新见解),导致协作失效,使多智能体系统退化为单智能体模式的现象。
- 多轮元思维过程 (Multi-turn Meta-thinking Process):一种将复杂推理任务建模为两个智能体交替协作的过程。其中,元思维智能体 (meta-thinking agent) 负责分解任务、设定子目标和监控进度;推理智能体 (reasoning agent) 则执行具体的计算和证明步骤。
- 夏普利启发的因果影响 (Shapley-inspired Causal Influence):本文提出的一种衡量智能体单步行为贡献度的方法。它通过将语义上相似的行为步骤聚合分组,并计算该组内所有步骤对其下一步行为影响的平均值,从而得到一个稳定且能抵抗表述差异的因果影响分数。
- 可验证的重启奖励 (Verifiable Restart Reward):一种为推理智能体的“深思熟虑”行为(即丢弃历史输出并重新开始)设计的奖励信号。该奖励通过验证“重启”这一动作是否提升了模型对最终正确答案的置信度来判断其有效性,从而为训练提供精确的信用分配。
相关工作
当前,大型语言模型(LLM)的推理能力通过思维链(Chain-of-Thought)等提示技术以及基于可验证奖励的强化学习训练得到了显著提升。在此基础上,多智能体框架通过为不同 LLM 分配专门角色(如规划、执行、反思)来模拟人类团队协作,以解决更复杂的问题。代表性工作 ReMA 采用了一个元思维智能体和一个推理智能体序贯交互的模式,并使用多轮组相对偏好优化(multi-turn GRPO)算法进行训练。
然而,现有工作存在一个关键瓶颈:懒惰智能体问题。尽管在传统多智能体强化学习中已有关注,但在 LLM 序贯交互的场景下,该问题的出现出乎意料。一个智能体的“懒惰”行为(如输出空白或无意义的复制)会误导后续的推理轨迹,破坏协作,使整个系统性能受限。本文旨在深入探究此问题在序贯多智能体 LLM 推理中的成因,并提出一种能够有效解决该问题、释放多智能体协作潜力的训练框架。
本文方法
懒惰智能体问题的实证与分析
本文首先通过实证案例揭示了懒惰智能体问题的存在。在 ReMA 框架中,推理智能体常在中间步骤输出空白内容,将推理负担完全推给元思维智能体,最终导致错误。
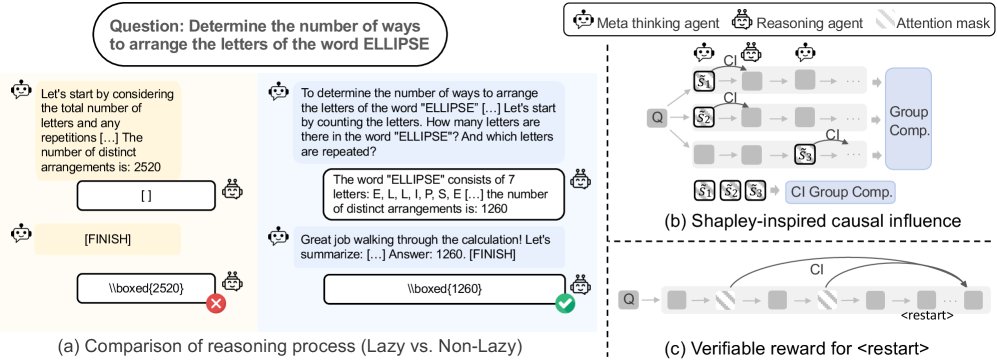
(a) 懒惰智能体案例研究;(b-c) 本文提出的模块。
为了量化“懒惰”程度,本文采用因果影响分析方法。通过抑制(suppress)某个智能体步骤对应的注意力,并测量其对下一步输出概率分布的改变(以KL散度衡量),可以评估该步骤的贡献大小。KL散度越小,说明该步骤影响力越低,行为越“懒惰”。
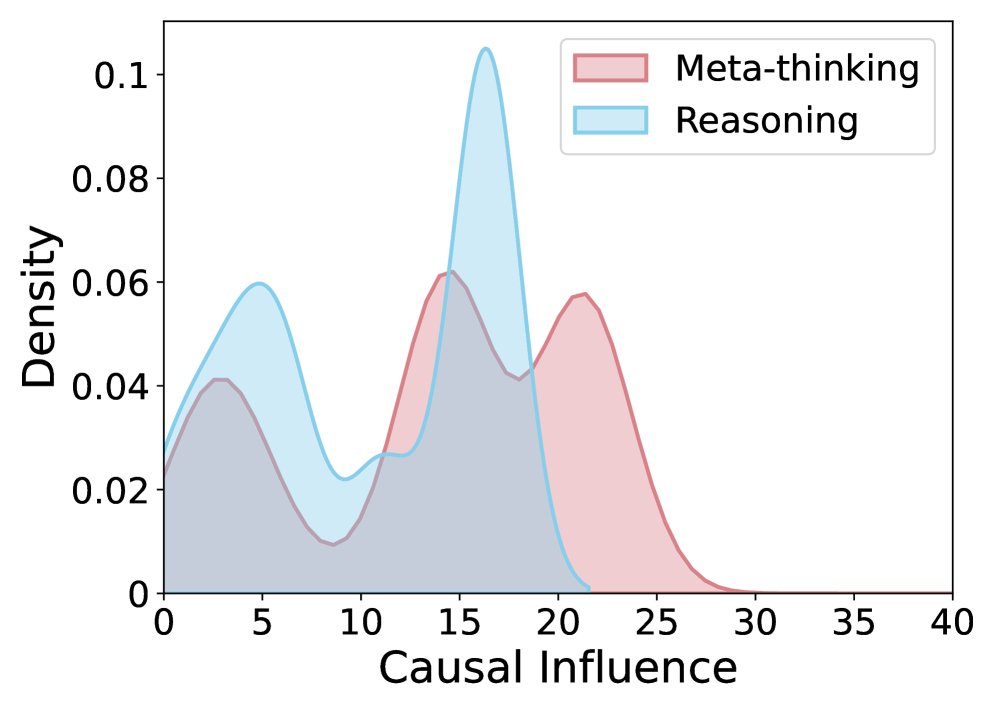
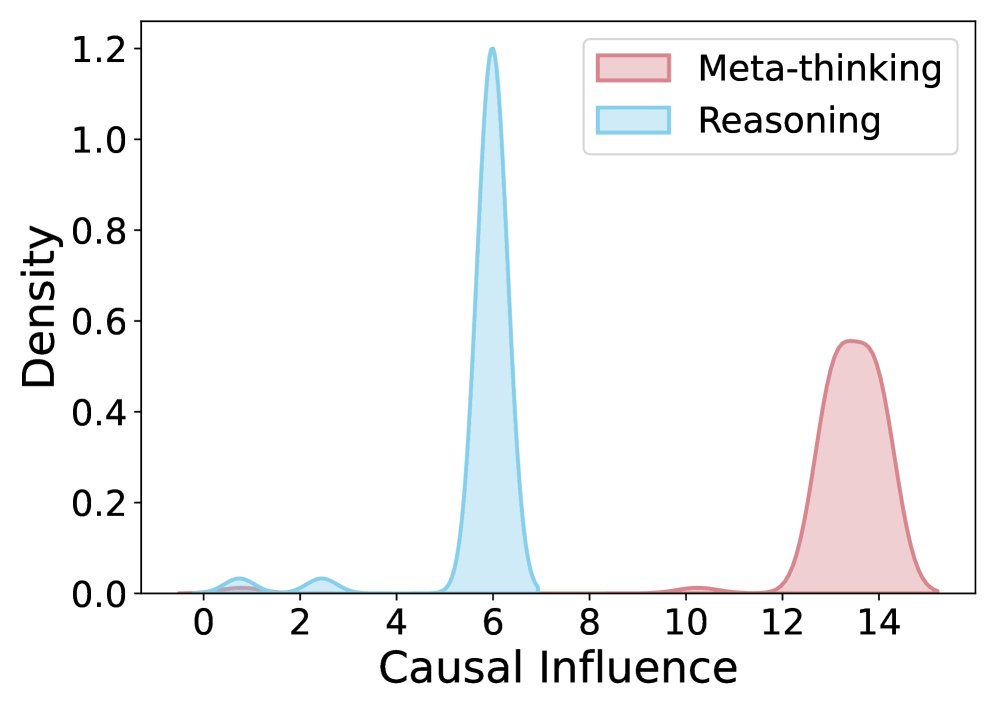
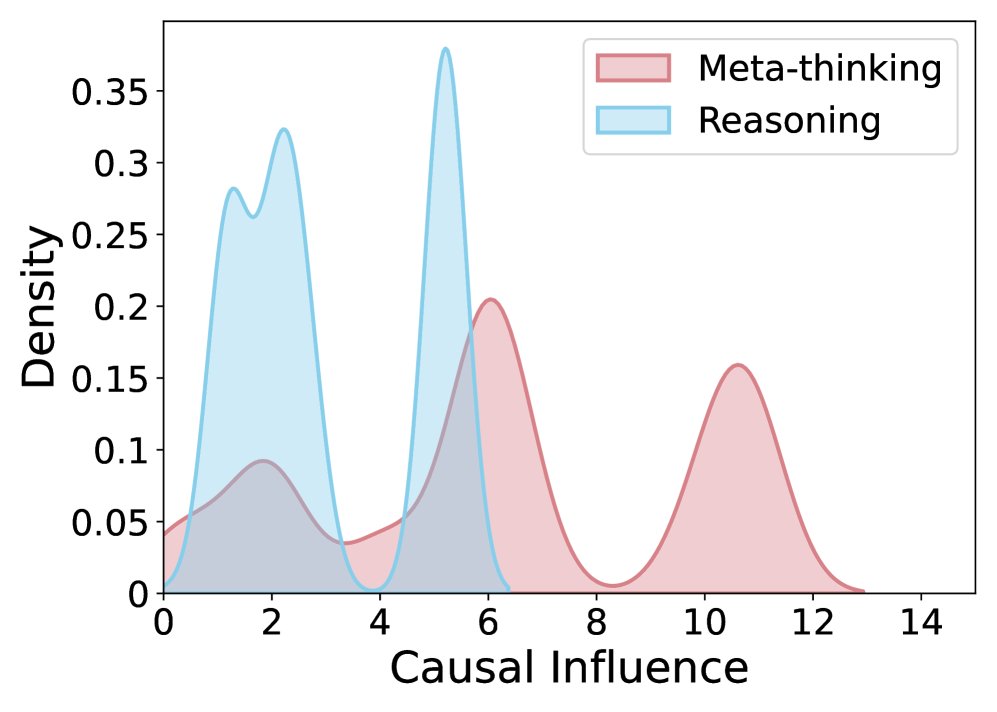
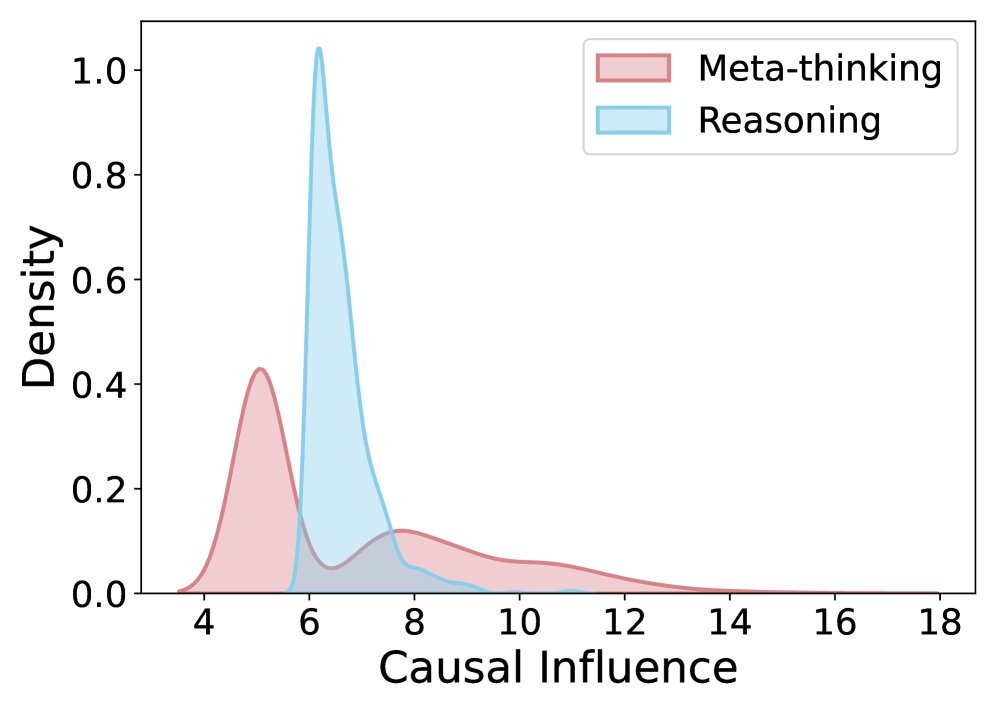
因果效应比较。(a) 未经训练的初始模型, (b) ReMA, (c) ReMA 带提示, (d) 本文方法。对应的 MATH500 性能分别为: (a) 75.0, (b) 74.4, (c) 75.6, (d) 78.4。
实验对比发现(上图a-c),与未经训练的基线模型相比,经过 ReMA 训练后,推理智能体(reasoning agent)的因果影响显著低于元思维智能体(meta-thinking agent),表现出明显的懒惰行为。即便通过提示工程鼓励其积极贡献,也未能从根本上解决问题。
创新点:懒惰智能体成因的理论分析
本文从理论上指出了多轮 GRPO 训练目标中的一个结构性偏差是导致懒惰智能体问题的根源。原目标函数为:
\[\mathcal{J}(\theta)=\mathbb{E}_{(\mathbf{x},\mathbf{y}^*)\sim\mathcal{D},\,\{(\mathbf{m}_i,\mathbf{y}_i)\}_{i=1}^{G}\sim\pi_{\theta_{\mathrm{old}}}(\cdot\mid\mathbf{x})} \left[\frac{1}{G}\sum_{i=1}^{G}\frac{1}{T_i}\sum_{t=1}^{T_i}\frac{1}{ \mid \mathbf{y}_{i,t} \mid }\sum_{j=1}^{ \mid \mathbf{y}_{i,t} \mid }\dots\right]\]其中,为了避免偏好更长交互序列而引入的归一化项 \($\frac{1}{T\_i}\)$($T_i$ 为交互轮数)会无意中激励模型选择能以更少轮次完成任务的路径。由于懒惰智能体的行为(如输出空内容)通常会缩短交互轮数,导致这些“捷径”行为在训练中被错误地强化,从而诱发了懒惰行为的产生。
Dr. MAMR: 一个优化的多智能体元推理框架
针对上述问题,本文提出了一个名为 Dr. MAMR (Multi-agent Meta-Reasoning Done Right) 的新框架。
创新点1:夏普利启发的因果影响测量
为了更精确地为每一步行为分配信用,Dr. MAMR 设计了一种稳定、高效的因果影响测量方法。该方法受夏普利值(Shapley values)启发,核心思想是:
- 分组聚合:对于某个待评估的行为步骤 $s_{i,t}$,在所有训练轨迹中找到一组在语义上与其相似的步骤 $G_S(s_{i,t})$。
- 计算边际贡献:对组内的每一个步骤 $s_{j,t’}$,分别计算其对下一步 $s_{j,t’+1}$ 的因果影响,即比较包含该步骤和不包含该步骤(通过掩码实现)时模型生成下一步的对数概率差值 $\Delta\ell_{j,t’}$。
- 求平均:将组内所有步骤的因果影响求平均,作为 $s_{i,t}$ 的最终因果影响得分 $\mathrm{CI}(s_{i,t})$。
这种方法通过聚合不同上下文中相似想法的贡献,避免了单一样本带来的噪声和对特定措辞的偏见,从而得到更稳健的贡献评估。
创新点2:支持深思熟虑的推理智能体
随着智能体协作加深,交互轮次增多,推理智能体可能会因过早地依赖不充分的上下文或被自己之前的错误输出误导而“迷失方向”。
为了解决这个问题,Dr. MAMR 赋予推理智能体深思熟虑 (deliberation) 的能力:当它认为有必要时,可以主动丢弃之前的历史输出,整合元思维智能体的指令,并重新开始推理。
本文引入了一个特殊的控制Token \([RESTART]\) 来触发这一行为,并设计了一种可验证的重启奖励机制来指导该行为的训练。该奖励机制的核心是:
- 判断“重启”操作(即掩码掉之前的推理历史)是否对模型生成最终答案的置信度产生了积极影响。
- 如果最终答案正确 ($z_i=+1$),且重启操作提升了模型对该答案的置信度 ($\Delta\ell_{i,t}>0$),则给予正奖励。
- 如果最终答案错误 ($z_i=-1$),且重启操作降低了模型对该答案的置信度 ($\Delta\ell_{i,t}<0$),也给予正奖励。
- 其他情况则给予负奖励或零奖励。
该奖励公式如下:
\[r^{\text{restart}}_{i,t}\;=\;\begin{cases}+1,&\text{if }(z_{i}=+1\,\wedge\,\Delta\ell_{i,t}>0)\;\;\text{or}\;\;(z_{i}=-1\,\wedge\,\Delta\ell_{i,t}<0),\\[6.0pt] -1,&\text{if }(z_{i}=+1\,\wedge\,\Delta\ell_{i,t}<0)\;\;\text{or}\;\;(z_{i}=-1\,\wedge\,\Delta\ell_{i,t}>0),\\[6.0pt] 0,&\text{if }\Delta\ell_{i,t}=0.\end{cases}\]最终优化目标
Dr. MAMR 的最终训练目标移除了导致偏差的 $\frac{1}{T}$ 归一化项,并构建了一个新的步级别优势函数 $A^{\mathrm{step}}_{i,t}$,它由三部分加权组成:
\[A^{\mathrm{step}}_{i,t}\;=\;\tilde{A}_{i,t}\,+\,\alpha\,\tilde{C}_{i,t}\,+\,\beta\,\tilde{R}_{i,t}\]其中,$\tilde{A}_{i,t}$ 是基于最终结果的标准化优势,$\tilde{C}_{i,t}$ 是标准化的夏普利启发因果影响,$\tilde{R}_{i,t}$ 是标准化的可验证重启奖励。$\alpha$ 和 $\beta$ 是超参数。这个综合的优势函数能够同时鼓励智能体做出有实际贡献的行为和在必要时进行深思熟虑的重启。
实验结论
本文在数学推理数据集 DeepScaleR 上对模型进行训练,并在多个数学竞赛级别的基准测试上进行评估。
- 懒惰智能体问题得到缓解:实验结果(如图2d所示)证实,与基线方法 ReMA 相比,采用 Dr. MAMR 框架训练的智能体在因果影响上表现出更加均衡的分布,推理智能体的贡献显著增加,成功缓解了懒惰行为。
- 性能显著提升:通过有效促进协作和深思熟虑,Dr. MAMR 在多个复杂推理任务上取得了优越的性能。例如,在 MATH500 数据集上,Dr. MAMR 的 Pass@1 准确率达到 78.4%,超过了 ReMA (74.4%) 和其他变体。
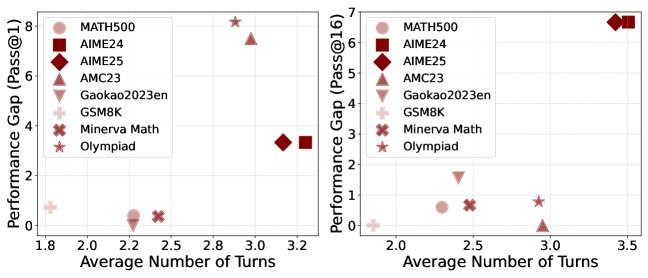
- 深思熟虑机制的有效性:初步实验表明,即使仅在推理时通过提示引导智能体进行重启,也能在较难的基准测试上获得性能提升(如图4所示),尤其是在需要多轮交互的复杂问题上。这验证了允许智能体在长交互中“重置”思路的价值。
最终结论:本文的分析和方法有效地解决了序贯多智能体LLM推理中的懒惰智能体问题。通过修正训练目标的内在偏差,并引入基于因果影响和可验证重启奖励的机制,Dr. MAMR 框架成功地促进了智能体之间更有意义的协作,从而显著提升了模型在复杂推理任务上的表现,真正释放了多智能体框架的潜力。