字节跳动VWN:不加算力“拓宽”Transformer,训练提速高达3倍!

想让大模型更强,最直接的方法就是“加宽”——增加其隐藏层维度。但这会导致计算成本呈二次方爆炸式增长,成为一个难以逾越的瓶颈。
论文标题:Virtual Width Networks
ArXiv URL:http://arxiv.org/abs/2511.11238v1
有没有办法只享受“变宽”的好处,却不付出昂贵的代价?
字节跳动最新的研究虚拟宽度网络(Virtual Width Networks, VWN)给出了一个极为巧妙的答案。它通过一种创新的方式,在几乎不增加核心计算负载的前提下,实现了模型“虚拟宽度”的扩展,并带来了惊人的性能提升。
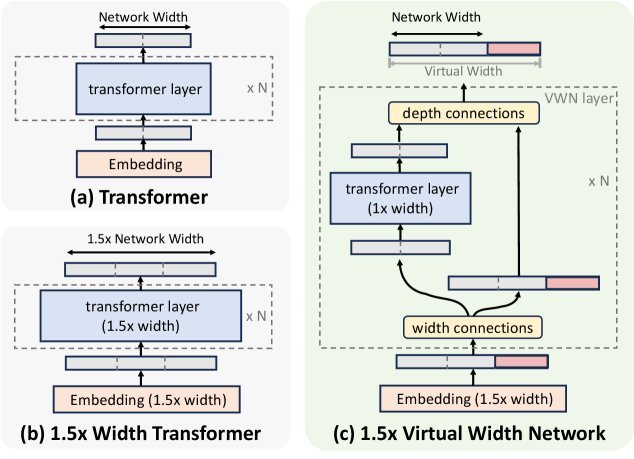
图注:(a) 标准Transformer,(b) 朴素加宽(计算量二次方增长),(c) VWN解耦了表征宽度和骨干网络宽度。
VWN的核心思想:解耦表征与计算
传统Transformer中,词嵌入(Embedding)的维度和网络骨干(Backbone)的隐藏层维度 $D$ 是相同的。如果想把 $D$ 翻倍,那么注意力机制和前馈网络的参数量与计算量都会增长约四倍。
VWN的核心洞见在于:将表征宽度与骨干宽度解耦。
简单来说,VWN允许我们使用一个非常宽的词嵌入维度 $D^{\prime}$(例如,是原始宽度 $D$ 的8倍),但在每一层Transformer的核心计算模块(如自注意力层和FFN)处理时,通过一个轻量级操作将其“压缩”回原始宽度 $D$。
处理完毕后,再将其“扩展”回宽维度 $D^{\prime}$,并传递给下一层。这样一来,模型在层与层之间传递的是信息更丰富的“宽”表征,而计算最昂贵的部分依然在“窄”维度上进行,从而巧妙地规避了二次方增长的计算成本。
GHC:连接虚拟与现实的桥梁
实现上述“压缩-扩展”操作的关键,是一种名为广义超连接(Generalized Hyper-Connections, GHC)的全新模块。
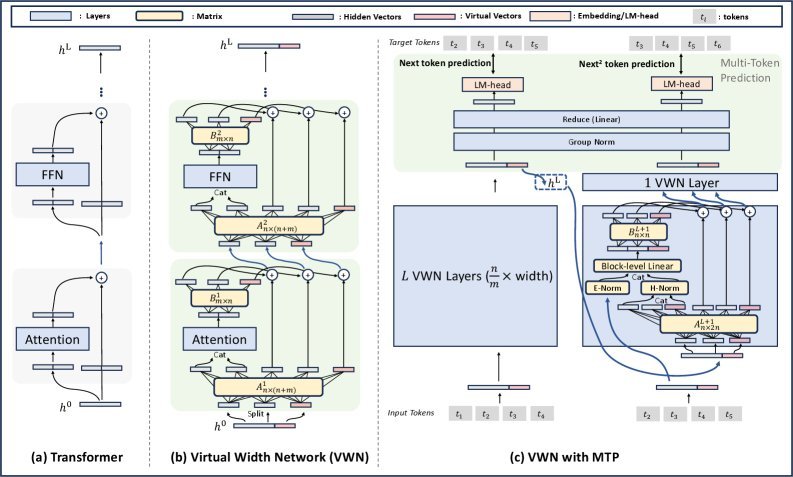
图注:VWN架构概览,GHC通过轻量级的矩阵A和B实现宽窄维度的灵活交互。
GHC本质上是一组轻量级的线性变换。在每个Transformer层中:
-
压缩:GHC使用一个投影矩阵 $\mathbf{A}^{l}$ 将输入的宽隐状态(Over-Width Hidden States)压缩到骨干网络所需的标准宽度。
-
扩展:在骨干网络处理完后,GHC再用另一个投影矩阵 $\mathbf{B}^{l}$ 将输出扩展回宽维度,并与原始的宽隐状态进行融合。
更进一步,研究还提出了动态GHC(Dynamic GHC, DGHC),其变换矩阵 $\mathbf{A}$ 和 $\mathbf{B}$ 可以根据输入动态生成,赋予模型更强的适应性。整个GHC模块的计算和内存开销都非常小,几乎可以忽略不计。
协同效应:当VWN遇上多令牌预测
为了更好地利用VWN带来的更宽表征空间,该研究将其与多令牌预测(Multi-Token Prediction, MTP)相结合。
MTP要求模型同时预测未来多个Token,这本身就需要模型具备更强的短程组合建模能力。而VWN提供的超宽表征空间,恰好为学习这种复杂关系提供了充足的“带宽”。
反过来,MTP提供的密集监督信号,也有效地驱动了VWN宽表征的学习。两者形成了完美的协同效应。
惊人的实验效果
VWN的效果到底如何?研究在一系列大规模MoE模型上进行了验证,结果令人印象深刻。
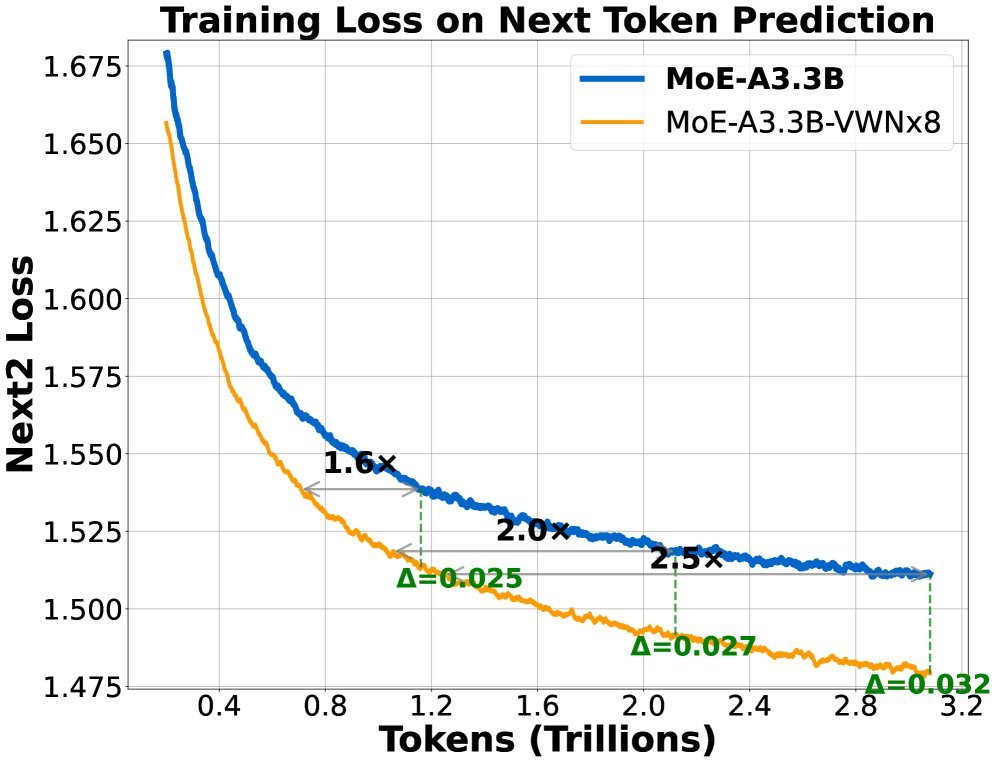
图注:在一个3.3B参数的MoE模型上,VWN(橙线)与基线(蓝线)的训练损失对比。
在一个激活参数为3.3B的MoE模型上,采用8倍虚拟宽度扩展的VWN(VWNx8)展现了巨大优势:
-
训练加速:在单令牌预测任务上,优化速度提升超过2倍;在双令牌预测任务上,加速比更是高达3倍。
-
数据效率:VWN仅用基线模型2.5倍到3.5倍分之一的数据量,就达到了相同的损失水平。
-
优势放大:随着训练的进行,VWN与基线模型之间的性能差距越来越大,显示出其强大的扩展潜力。
研究还发现,虚拟宽度与模型损失之间存在近似的对数线性关系,这意味着“虚拟宽度缩放”可能成为继模型参数、数据量之后的第三条有效提升大模型效率的缩放法则(Scaling Law)。
深度注意力:一个全新的视角
论文还提供了一个非常精彩的解读视角:将VWN理解为一种沿深度轴的注意力机制。
如果把Transformer的堆叠层看作一个“深度序列”,那么:
-
标准残差连接:只关注前一层的输出,相当于一个大小为2的滑动窗口。
-
VWN/GHC:通过在层间传递和融合宽表征,实现了一种跨多层的、类似线性注意力的信息聚合机制。它允许当前层“看到”前面多个层的压缩信息,极大地扩展了模型的“深度感受野”。
总结
Virtual Width Networks (VWN) 提出了一种极具前瞻性的模型架构范式。它通过解耦表征宽度和计算宽度,让我们能够以极小的成本获得“更宽”模型所带来的巨大优势。这项工作不仅显著提升了模型训练的效率和性能,更重要的是,它为大模型缩放探索出了一个全新的、充满潜力的维度。简单而有效,VWN再次证明了架构创新在AI发展中的关键作用。