Vision Transformers are Circulant Attention Learners
ViT暗藏“循环”玄机?清华新作:用FFT将注意力复杂度降至$O(N\log N)$

Vision Transformer (ViT) 自从问世以来,凭借其强大的全局建模能力,在计算机视觉的各个领域攻城略地。然而,这种强大的能力并非没有代价——标准自注意力机制(Self-Attention)的计算复杂度是 $O(N^2)$。这意味着,随着图像分辨率的提升,计算量呈爆炸式增长,这成为了ViT在高分辨率任务(如分割、检测)中落地的最大拦路虎。
ArXiv URL:http://arxiv.org/abs/2512.21542v1
为了解决这个问题,过去的研究者们想出了各种“手工”招数:有的把注意力限制在局部窗口(如 Swin Transformer),有的引入稀疏采样(如 PVT)。虽然这些方法降低了计算量,但也牺牲了ViT最引以为傲的“全局视野”。
有没有一种方法,既能保留全局感受野,又能大幅降低计算复杂度?
来自清华大学的研究团队给出了一个令人惊讶的答案:有,而且这种高效结构其实一直隐藏在ViT的注意力图之中。
他们在最新论文《Vision Transformers are Circulant Attention Learners》中揭示了一个有趣的现象:ViT学到的注意力矩阵,本质上非常接近一种特殊的数学结构——块循环矩阵(Block Circulant Matrix with Circulant Blocks, BCCB)。基于这一发现,他们提出了一种全新的循环注意力(Circulant Attention),利用快速傅里叶变换(FFT)将计算复杂度从 $O(N^2)$ 降维打击至 $O(N\log N)$。
这一发现颠覆了什么?
要理解这项工作的精妙之处,我们需要先看一眼ViT内部发生了什么。
在标准的自注意力机制中,模型需要计算每一个Token与其他所有Token之间的关系,生成一个 $N \times N$ 的注意力矩阵。通常我们认为这个矩阵是稠密的、无规律的。
然而,作者在观察 DeiT 模型训练出的注意力图时,发现了一个惊人的规律:
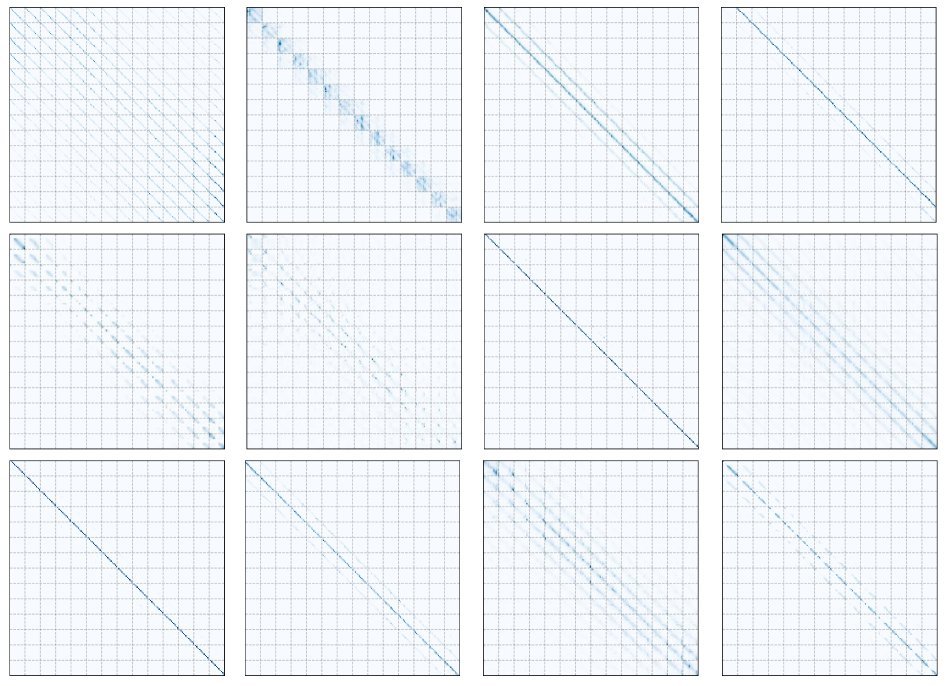
如上图所示,这些注意力图并非杂乱无章,而是呈现出明显的条纹状结构。在数学上,这种结构高度近似于 BCCB矩阵。
为什么这个发现很重要?
因为在数学上,BCCB矩阵有一个极其强大的特性:BCCB矩阵与向量的乘法,等价于2D离散卷积。
这意味着,我们可以利用 卷积定理,通过 快速傅里叶变换(Fast Fourier Transform, FFT)在频域完成计算。这样一来,原本需要 $O(N^2)$ 的矩阵乘法,瞬间变成了 $O(N\log N)$ 的频域点乘!
Circulant Attention:用FFT重构注意力
基于上述发现,作者提出了 循环注意力(Circulant Attention)。其核心思想非常直接:既然ViT倾向于学习BCCB结构,那我们干脆直接显式地将注意力图建模为BCCB矩阵。
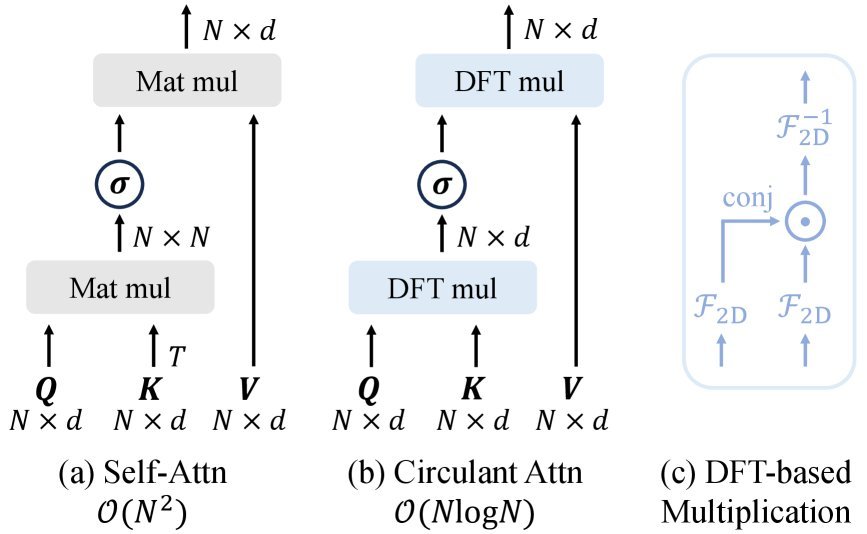
如上图所示,循环注意力 的计算流程与传统方法大不相同:
-
传统方法:计算 $Q$ 和 $K$ 的点积得到注意力图 $A$,然后 $A$ 乘以 $V$。每一步都是沉重的矩阵运算。
-
本文方法:
-
不直接计算巨大的注意力矩阵。
-
利用FFT将 $Q$ 和 $K$ 变换到频域。
-
在频域通过点乘(Element-wise Product)高效计算出相关性。
-
再通过逆FFT变回时域,得到输出。
-
具体的数学推导非常优雅。对于输入序列 $x$,原本的注意力计算 $O=\sigma(QK^T)V$ 被重构为基于卷积的形式:
\[O = \sigma(a) \circledast V\]其中 $\circledast$ 代表基于DFT(离散傅里叶变换)的乘法运算。这使得整个注意力机制的复杂度被严格控制在 $O(N\log N)$。
性能表现:更快、更强
这种数学上的优雅设计,在实际应用中表现如何呢?
作者将 循环注意力 作为一个即插即用的模块,替换了 DeiT、PVT 和 Swin Transformer 中的原始注意力模块,进行了广泛的实验。
1. 惊人的效率提升
在处理高分辨率图像时,优势尤为明显。如下图所示,随着Token数量的增加(图像分辨率变大),传统自注意力(SA)的计算量(FLOPs)呈指数级上升,而 循环注意力(CA)则保持了近乎线性的增长。
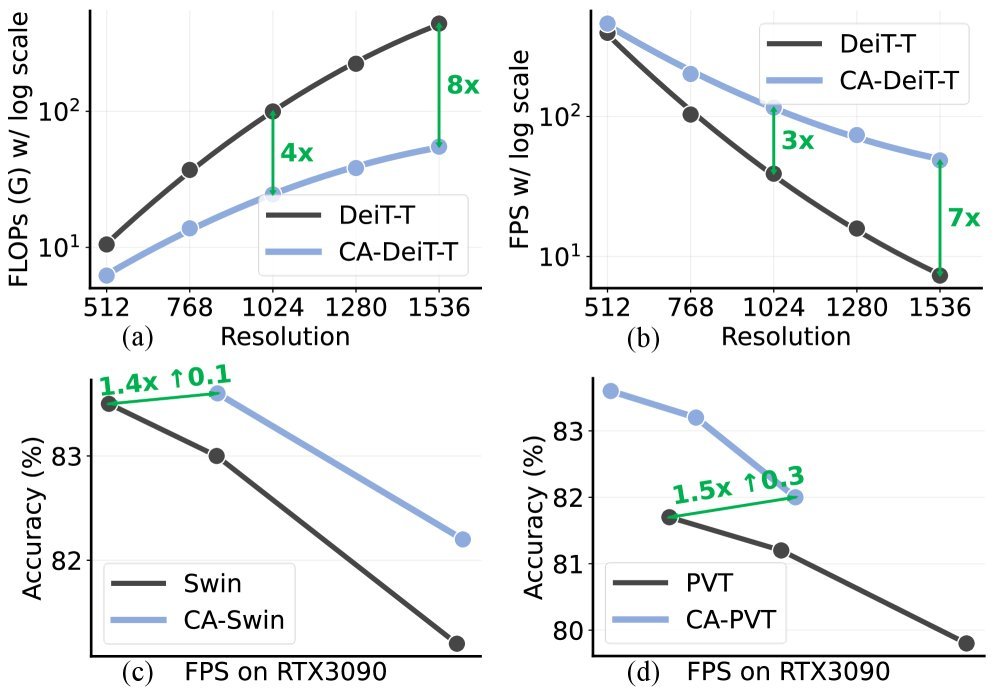
-
在 $1536 \times 1536$ 的分辨率下,CA-DeiT 的计算量比原始 DeiT 减少了 8倍。
-
实际推理速度提升了 7倍。
2. 不输原本的精度
你可能会担心,强制使用BCCB结构会不会限制模型的表达能力?
实验结果打消了这种顾虑。在 ImageNet 分类、COCO 目标检测和 ADE20K 语义分割任务中,使用 循环注意力 的模型不仅速度更快,性能往往还优于基线模型。
-
目标检测:CA-PVT-S 模型在参数量更少的情况下,比更大的 PVT-L 模型高出 1.3 AP。
-
语义分割:在 ADE20K 上,替换后的模型带来了最高 3.7% mIoU 的提升。
总结
这篇论文最精彩的地方在于,它不是为了“炫技”而引入复杂的数学工具,而是从观察到的现象出发——ViT自发地学习出了循环结构。
这表明,$O(N^2)$ 的全连接注意力对于视觉任务来说可能是冗余的。循环注意力(Circulant Attention)通过引入FFT,成功地剥离了这种冗余,让Vision Transformer在享受全局感受野的同时,拥有了线性级别的计算效率。
对于正在为ViT高分辨率部署发愁的工程师们来说,这无疑是一个值得尝试的“降本增效”新利器。