Wait, Wait, Wait... Why Do Reasoning Models Loop?
DeepSeek-R1变“复读机”?MIT揭秘:蒸馏导致死循环暴增,调高温度治标不治本

当你在使用 DeepSeek-R1 或 OpenThinker 等最新的推理模型解决复杂的数学问题时,是否遇到过这样的情况:模型开始输出长长的思维链(Chain of Thought),一切看起来都很顺利,直到它突然陷入了某种怪圈——不断重复同一段话,或者在两个步骤之间反复横跳,直到耗尽 Token 上限。
ArXiv URL:http://arxiv.org/abs/2512.12895v1
这种“死循环”(Looping)现象并非个例,而是当前长思维链推理模型面临的一个普遍顽疾。虽然大多数开发者建议通过调高“温度”(Temperature)参数来缓解这一问题,但这真的触及病灶了吗?
来自 MIT、微软研究院和威斯康星大学麦迪逊分校的研究团队在最新论文《Wait, Wait, Wait… Why Do Reasoning Models Loop?》中,深入剖析了这一现象。该研究得出了一个令人惊讶的结论:死循环的本质是模型学习过程中的系统性错误,而通常被视为“解药”的高温度采样,实际上只是一种掩盖问题的权宜之计。
现象:学生模型比老师更容易“鬼打墙”
研究团队首先对当前的开源推理模型进行了大规模测试,包括 DeepSeek-R1 的蒸馏版本(Distilled Qwen/Llama)、OpenThinker-3 以及 Phi-4 等。他们在 AIME(美国数学邀请赛)题目上测试了这些模型,发现了一些反直觉的规律:
-
低温必死循环:几乎所有模型在贪婪解码(Greedy Decoding,即温度为 0)或低温度下,都会频繁陷入死循环。
-
小模型更严重:在同一家族中,参数量越小的模型,死循环概率越高。
-
“青出于蓝而逊于蓝”:这是最关键的发现。通过知识蒸馏训练出来的“学生模型”,其死循环频率远高于它们的“老师模型”。
如下图所示,OpenThinker3-1.5B(学生)在低温度下的死循环比例高达 30% 以上,而它的老师 QwQ-32B 几乎从不陷入死循环。
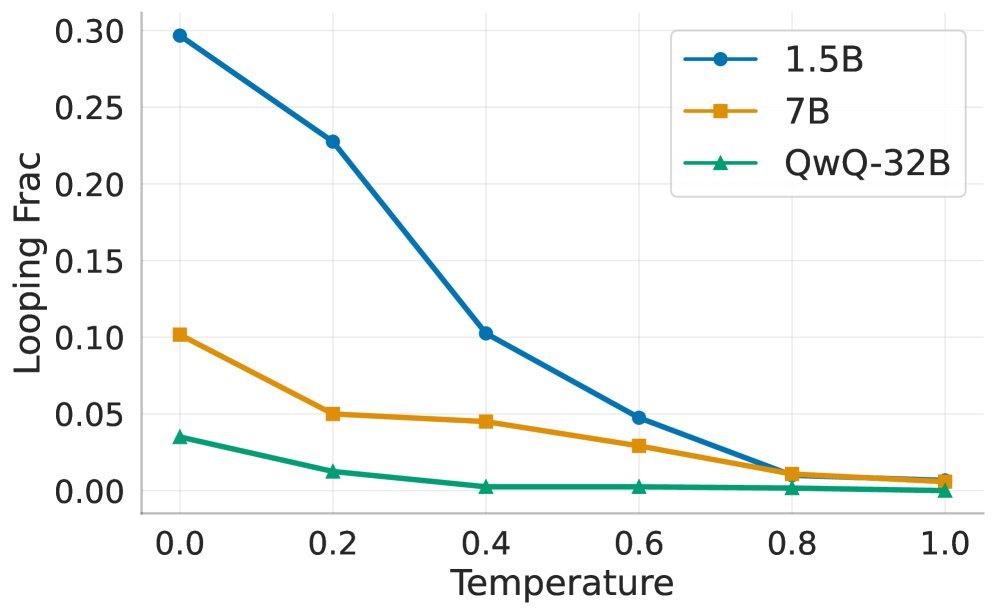
如果学生完美地学习了老师的概率分布,这种差异是不应该存在的。这直接指向了一个核心原因:学习误差(Errors in Learning)。也就是说,学生模型并没有学会老师在关键决策点上的精准判断,这种“学艺不精”导致了死循环。
深度归因:为什么模型会选择“复读”?
为了搞清楚这种“学习误差”是如何转化为“死循环”的,研究人员设计了一个巧妙的合成图推理任务(Synthetic Graph Reasoning Task)。他们让模型在一个星型图上进行随机游走,模拟推理过程中的“前进”和“回溯”。
通过这个受控实验,论文揭示了导致死循环的两大核心机制:
1. 学习难度导致的“风险规避”(Risk Aversion)
这是最主要的原因。在推理过程中,正确的“下一步”(例如数学证明中的关键推导)往往很难学,因为它可能混杂在无数错误的选项中。相比之下,循环动作(Cyclic Action)——比如重述已知条件、回溯到上一步——通常非常容易识别且容易学习。
当模型面临选择时,如果“正确的进步动作”太难学(即模型无法将其与其他干扰项区分开),模型会将原本属于正确动作的概率质量“稀释”到所有干扰项中。
数学上的解释是这样的:
假设正确动作是 $a_{correct}$,容易的循环动作是 $a_{cycle}$。如果模型无法区分 $a_{correct}$ 和其他 $n$ 个错误动作,那么根据最大似然估计,模型分配给 $a_{correct}$ 的概率会变成 $(1-p)/n$,而 $a_{cycle}$ 依然保持 $p$ 的高概率。
结果就是,模型为了“求稳”,倾向于选择概率更高的循环动作,从而陷入死循环。这解释了为什么能力较弱的学生模型(学习能力差,区分度低)更容易死循环。
2. 变压器架构的“时间相关性误差”(Temporally Correlated Errors)
即使没有学习难度,Transformer 架构本身也存在一种归纳偏置(Inductive Bias)。
研究发现,模型在某个决策点犯下的微小预测误差,往往具有时间相关性。简单来说,如果模型在第 10 步经过节点 A 时,错误地稍微偏向了路径 X;那么当它在第 20 步再次回到节点 A 时,它依然会偏向路径 X。
这种误差的自我强化,导致模型一旦踏入某条错误的路径,就会在后续的决策中不断重复这个错误,最终形成闭环。
温度(Temperature):是解药还是止痛药?
面对死循环,目前的通用做法是调高 Temperature(增加随机性)。这确实有效,因为随机性促使模型跳出概率最高的“死循环陷阱”,去探索其他路径。
但该研究指出,这并不是真正的解决方案。
如下图所示,随着温度升高,死循环确实减少了(图 a),但模型的平均响应长度(Average CoT Length)却在持续飙升(图 b),甚至远超老师模型。
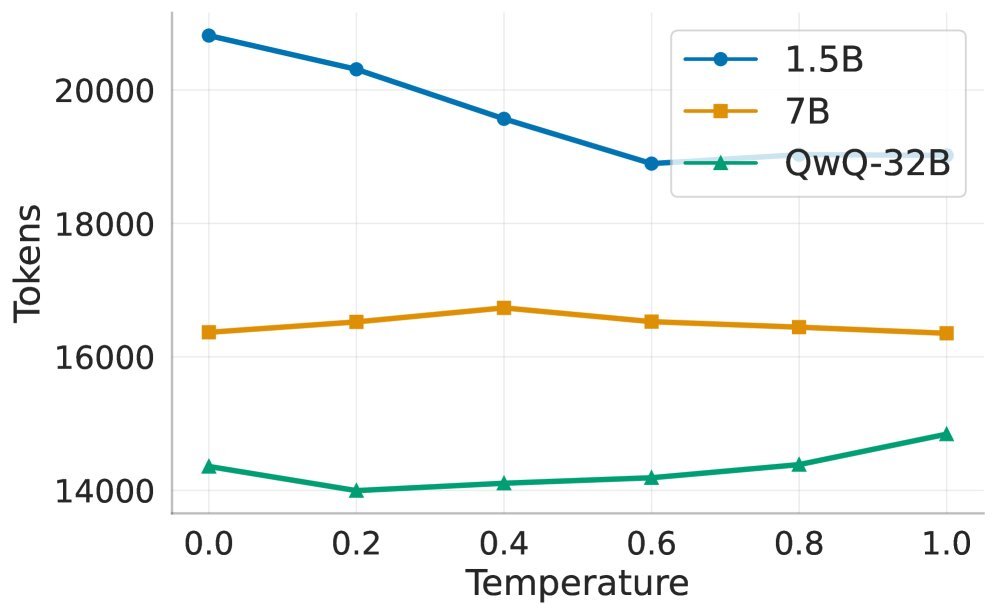
这意味着,高温度下的模型并没有学会“正确”的推理路径,它只是在错误和循环的边缘疯狂试探,依靠运气(随机性)最终跌跌撞撞地找到了答案,或者输出了大量无效的废话。
结论很扎心:温度只是掩盖了模型“学艺不精”的事实,它是一种权宜之计(Stopgap),而非整体解决方案。
总结与启示
这篇论文为我们理解大模型的推理机制提供了非常重要的视角。它告诉我们,DeepSeek-R1 等模型出现的“复读机”行为,不仅仅是解码策略的问题,更是模型训练阶段未能完美拟合复杂推理分布的体现。
对于开发者而言,这意味着仅仅依靠 Inference-time 的策略(如调整温度、惩罚重复)是不够的。未来的方向可能需要更直接的训练时干预(Training-time Interventions),例如设计专门的损失函数来纠正这种“风险规避”倾向,或者在蒸馏过程中更精准地对齐老师和学生在关键决策点上的概率分布。
只有从根本上减少“学习误差”,我们才能得到既不罗嗦、又不死循环的高效推理模型。